1 Spark Introduction
Spark is a fast, universal and scalable large data analysis engine. It was born in AMPLab, University of California, Berkeley in 2009. It was open source in 2010. It became Apache incubator in June 2013 and top-level Apache project in February 2014. At present, Spark ecosystem has developed into a collection of multiple sub-projects, including Spark SQL, Spark Streaming, GraphX, MLlib and other sub-projects. Spark is a large data parallel computing framework based on memory computing. Spark is based on memory computing, which improves the real-time performance of data processing in large data environment, guarantees high fault tolerance and scalability, and allows users to deploy Spark on a large number of cheap hardware to form a cluster. Spark is supported by many big data companies, including Hortonworks, IBM, Intel, Cloudera, MapR, Pivotal, Baidu, Ali, Tencent, Jingdong, Ctrip and Youku Potatoes. At present, Baidu's Spark has been used in Fengchao, Big Search, Direct Number, Baidu Big Data and other businesses; Ali has built a large-scale graph computing and graph mining system using GraphX, and implemented many recommendation algorithms for production systems; Tencent Spark cluster has reached 8000 units, which is the largest known Spark cluster in the world.
1.1 Reasons for Learning Spark
Intermediate Output: MapReduce-based computing engines usually output intermediate results to disk for storage and fault tolerance. Considering the task pipeline, when some queries are translated into MapReduce tasks, they often generate multiple Stages, which in turn rely on the underlying file system (such as HDFS) to store the output of each Stage.
Spark is an alternative to MapReduce, compatible with HDFS and Hive, and can be integrated into Hadoop's ecosystem to make up for MapReduce's shortcomings.
1.2 Characteristics of Spark
1.2.1 fast
Compared with Hadoop's MapReduce, Spark runs more than 100 times faster in memory and 10 times faster in hard disk. Spark implements an efficient DAG execution engine, which can process data streams efficiently through memory-based.
1.2.2 easy to use
Spark supports the API s of Java, Python and Scala, as well as over 80 advanced algorithms, enabling users to quickly build different applications. And Spark supports interactive Python and Scala shells, so it is very convenient to use Spark clusters in these shells to verify the solution.
1.2.3 Universal
Spark provides a unified solution. Spark can be used for batch processing, interactive query (Spark SQL), real-time stream processing (Spark Streaming), machine learning (Spark MLlib) and graph computing (GraphX). These different types of processing can be used seamlessly in the same application. Spark's unified solution is very attractive, after all, any company wants to use a unified platform to deal with the problems encountered, reduce the human cost of development and maintenance and the material cost of deploying the platform.
1.2.4 Compatibility
Spark can be easily integrated with other open source products. For example, Spark can use Hadoop's YARN and Apache Mesos as its resource management and dispatcher, and can process all Hadoop-supported data, including HDFS, HBase and Cassandra. This is particularly important for users who have deployed Hadoop clusters because Spark's powerful processing capabilities can be used without any data migration. Spark can also be independent of third-party resource management and scheduler. It implements Standalone as its built-in resource management and scheduling framework, which further reduces the use threshold of Spark and makes it very easy for everyone to deploy and use Spark. In addition, Spark provides tools for deploying Standalone's Spak cluster on EC2.
2 Spark Cluster Installation
Download address https://spark.apache.org/downloads.html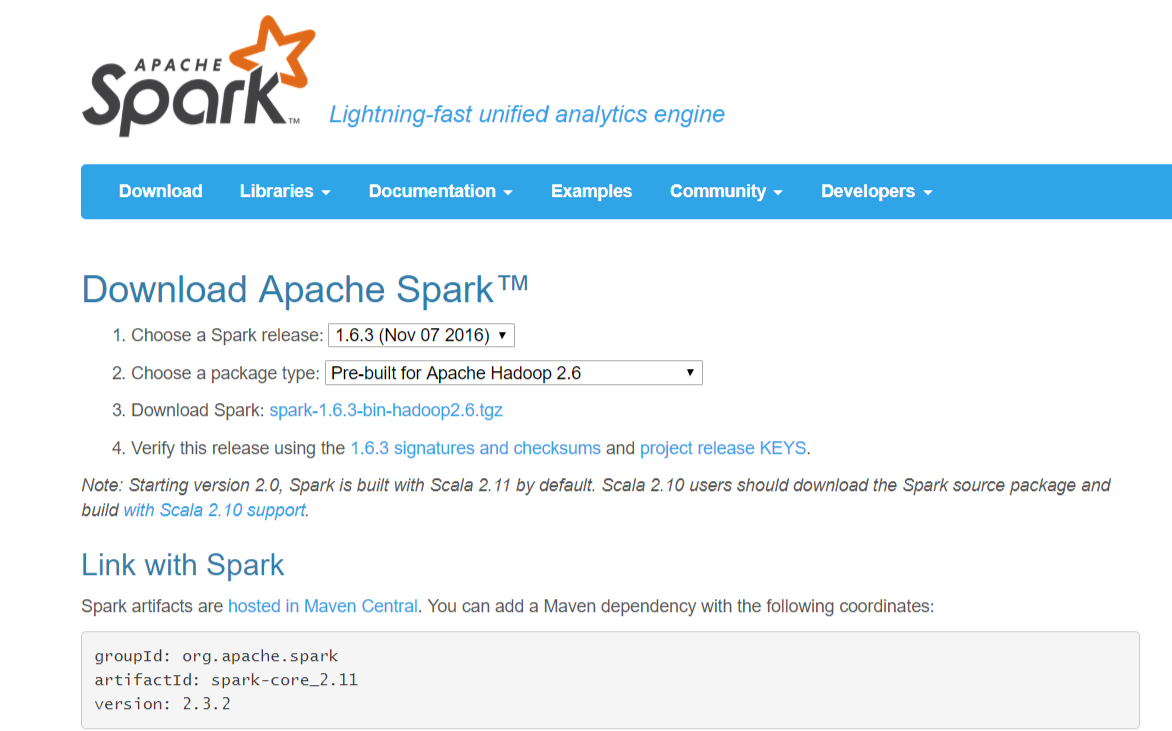
2.1 Source Upload to Cluster
decompression
2.2 Modify configuration files
2.2.1 spark-env.sh
[hadoop@node1 ~]$ cd /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/ [hadoop@node1 spark-1.6.3-bin-hadoop2.6]$ ll total 1380 drwxr-xr-x. 2 hadoop hadoop 4096 Nov 3 2016 bin -rw-r--r--. 1 hadoop hadoop 1343562 Nov 3 2016 CHANGES.txt drwxr-xr-x. 2 hadoop hadoop 230 Nov 3 2016 conf drwxr-xr-x. 3 hadoop hadoop 19 Nov 3 2016 data drwxr-xr-x. 3 hadoop hadoop 79 Nov 3 2016 ec2 drwxr-xr-x. 3 hadoop hadoop 17 Nov 3 2016 examples drwxr-xr-x. 2 hadoop hadoop 237 Nov 3 2016 lib -rw-r--r--. 1 hadoop hadoop 17352 Nov 3 2016 LICENSE drwxr-xr-x. 2 hadoop hadoop 4096 Nov 3 2016 licenses -rw-r--r--. 1 hadoop hadoop 23529 Nov 3 2016 NOTICE drwxr-xr-x. 6 hadoop hadoop 119 Nov 3 2016 python drwxr-xr-x. 3 hadoop hadoop 17 Nov 3 2016 R -rw-r--r--. 1 hadoop hadoop 3359 Nov 3 2016 README.md -rw-r--r--. 1 hadoop hadoop 120 Nov 3 2016 RELEASE drwxr-xr-x. 2 hadoop hadoop 4096 Nov 3 2016 sbin [hadoop@node1 spark-1.6.3-bin-hadoop2.6]$ cd conf [hadoop@node1 conf]$ ll total 36 -rw-r--r--. 1 hadoop hadoop 987 Nov 3 2016 docker.properties.template -rw-r--r--. 1 hadoop hadoop 1105 Nov 3 2016 fairscheduler.xml.template -rw-r--r--. 1 hadoop hadoop 1734 Nov 3 2016 log4j.properties.template -rw-r--r--. 1 hadoop hadoop 6671 Nov 3 2016 metrics.properties.template -rw-r--r--. 1 hadoop hadoop 865 Nov 3 2016 slaves.template -rw-r--r--. 1 hadoop hadoop 1292 Nov 3 2016 spark-defaults.conf.template -rwxr-xr-x. 1 hadoop hadoop 4209 Nov 3 2016 spark-env.sh.template [hadoop@node1 conf]$ mv spark-env.sh.template spark-env.sh
Add the following configuration to the configuration file
export JAVA_HOME=/usr/apps/jdk1.8.0_181-amd64 export SPARK_MASTER_IP=node1 export SPARK_MASTER_PORT=7077
2.2.2 slaves
[hadoop@node1 conf]$ mv slaves.template slaves
Add content
node2 node3
2.3 Copy the configured Spark to other nodes
[hadoop@node1 ~]$ scp -r /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/ node2:/home/hadoop/apps [hadoop@node1 ~]$ scp -r /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/ node3:/home/hadoop/apps
2.4 Modification of configuration files
/etc/profile
export SPARK_HOME=/home/hadoop/apps/spark-1.6.3-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Send the configuration file to node2,node3
[hadoop@node1 ~]$ sudo scp /etc/profile node2:/etc [sudo] password for hadoop: root@node2's password: profile 100% 2427 1.7MB/s 00:00 [hadoop@node1 ~]$ sudo scp /etc/profile node3:/etc root@node3's password: profile
Refresh the configuration file at the same time on three nodes
source /etc/profile
2.5 boot
[hadoop@node1 ~]$ /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node1.out localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. node3: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node3.out node2: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node2.out localhost: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node1.out [hadoop@node1 ~]$
2.5.1 http://node1:8080/
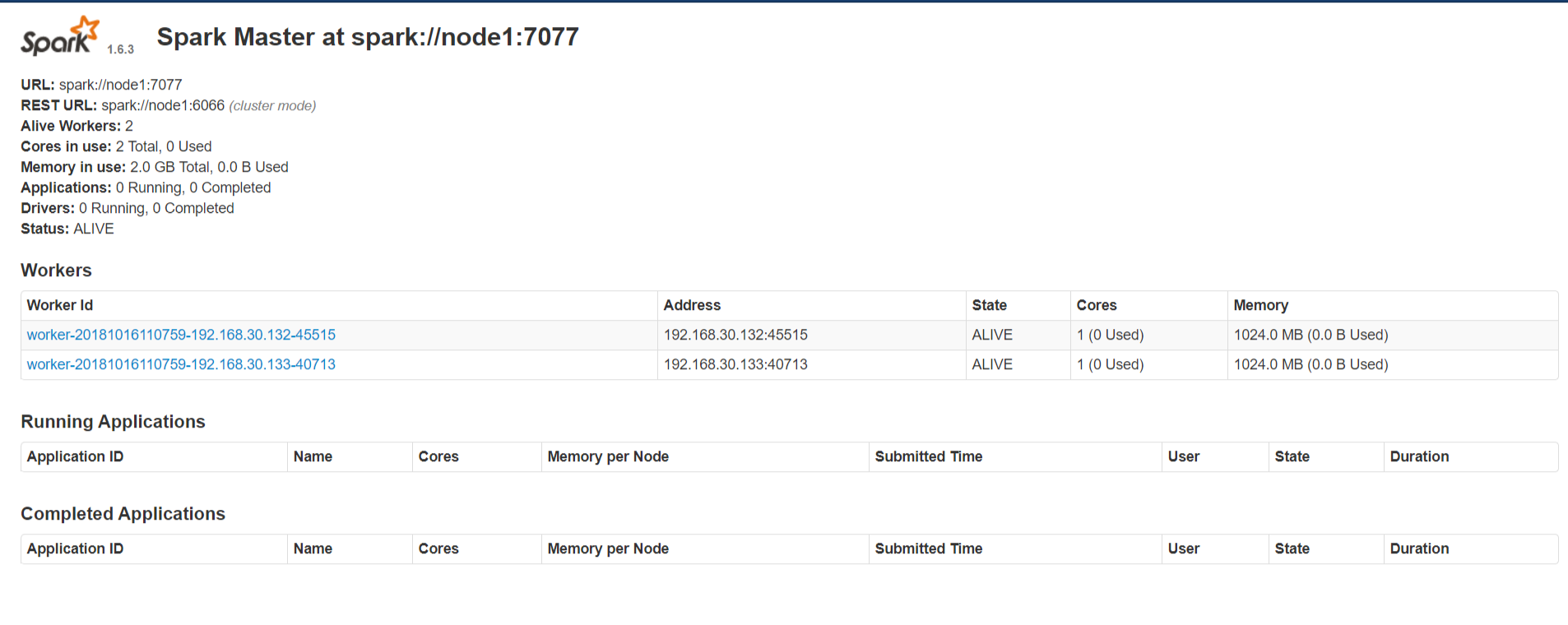
3 Spark Shell
/home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/bin/spark-shell --master spark://node1:7077 --total-executor-cores 4 --executor-memory 1g
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.3
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
18/10/16 12:04:49 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/16 12:04:50 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/16 12:04:54 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
18/10/16 12:04:54 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
18/10/16 12:04:57 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/16 12:04:57 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/16 12:05:02 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
18/10/16 12:05:02 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
SQL context available as sqlContext.
scala>
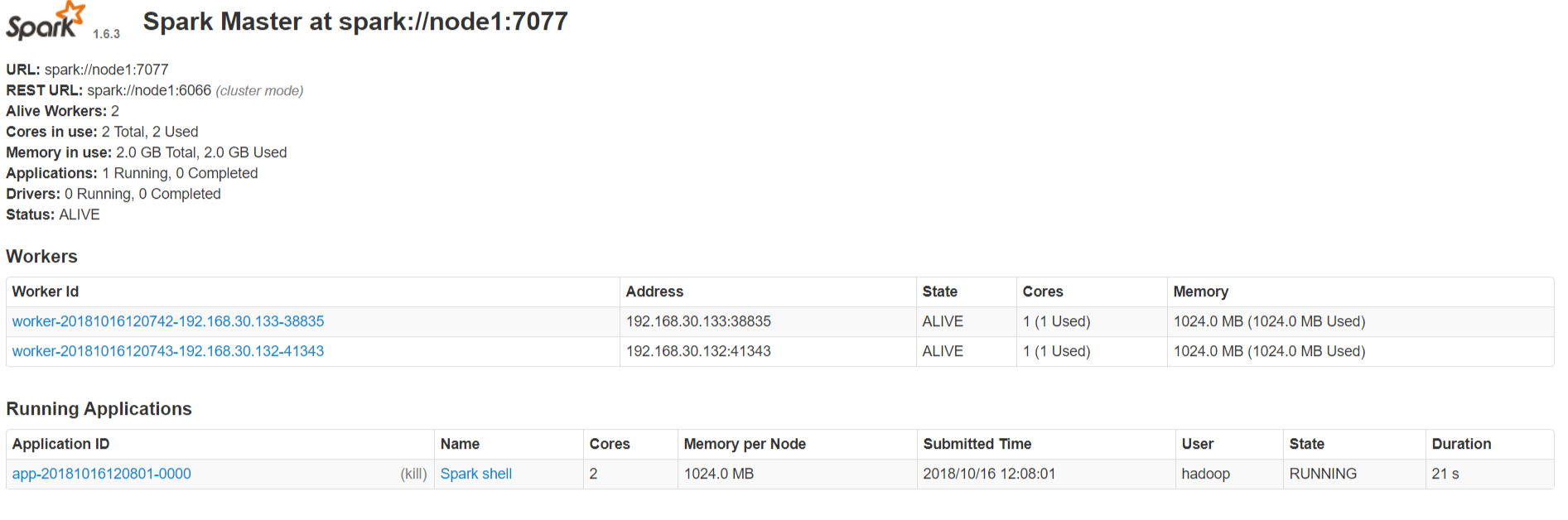
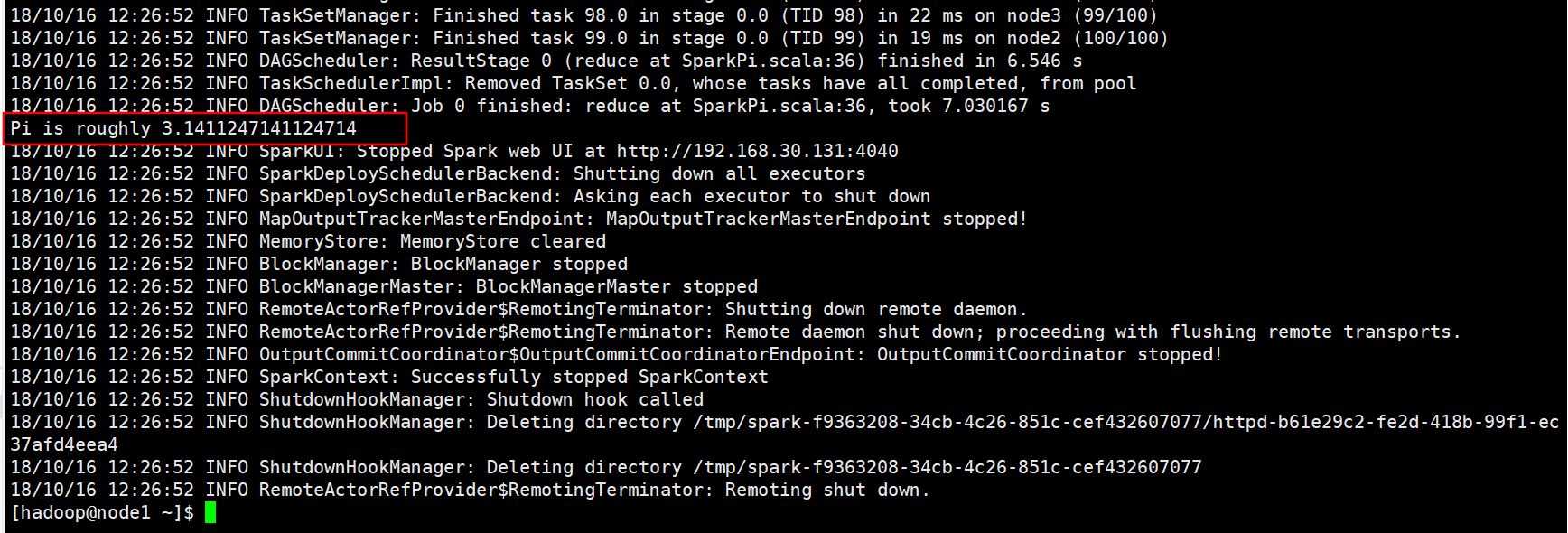
4 Execute the first Spark program
Using Monte Carlo Method to Find PI
scala> [hadoop@node1 ~]$ [hadoop@node1 ~]$ /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/bin/spark-submit \ > --class org.apache.spark.examples.SparkPi \ > --master spark://node1:7077 \ > --executor-memory 1G \ > --total-executor-cores 2 \ > /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/lib/spark-examples-1.6.3-hadoop2.6.0.jar 100