Spark common RDD operators for big data development
map
map passes in a piece of data and returns a piece of data
Map is to perform function operations on the elements in the RDD one by one and map them to another RDD,
Each data item in an RDD is transformed into a new element through the function mapping in the map.
Input partition and output partition are one-to-one, that is, there are as many output partitions as there are input partitions
object DemoMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("DemoMap")
.setMaster("local")
val sc = new SparkContext(conf)
val listRDD = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7))
listRDD.map(i=>i+1)//Add 1 to each element of the List set
.foreach(println)
}
}
flatMap
flatMap is simply to pass in one item and return N items
flatMap operation is to apply the function to each element in the RDD and form a new RDD with all the contents of the returned iterator.
flatMap will automatically flatten (expand) the results
object DemoFlatMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DemoFlatMap")
val sc = new SparkContext(conf)
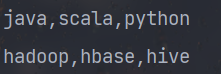
val lineRDD = sc.parallelize(List("java,scala,python", "hadoop,hbase,hive"))
lineRDD.map(line=>line.split(",")).foreach(line=>println(line.mkString(",")))
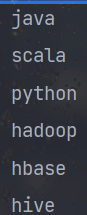
lineRDD.flatMap(line=>line.split(",")).foreach(println)
}
}
lineRDD.map(line=>line.split(" 😊). If foreach(println) is written like this, only the address value is output
Linerdd.map (line = > line. Split (","). Foreach (line = > println (line. Mkstring (",")) output is printed as
Linerdd. Flatmap (line = > line. Split (","). Foreach (println) is output as
The difference between flatMap and map is that map is "mapping", while flatMap "maps first and then flattens". Map generates an element every time (func) and returns an object. One more step of flatMap is to merge all objects into one object.
mapPartitions and mapPartitionsWithIndex
Qu Yu foreachPartition(belong to Action,And no return value), and mapPartitions Gets the return value map The difference has been mentioned earlier, but due to the single Run alone in RDD On each partition of( block),So in a type T of RDD Run on When( function)Must be Iterator<T> => Iterator<U>Method of type (input parameter) And mapPartitions Similar, but you need to provide an integer value representing the partition index value as a parameter Number, therefore function Must be( int, Iterator<T>)=>Iterator<U>Type
object DemoMapPartitions {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DemoMapPartition")
val sc = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("spark/data/student.txt", 6)
println(stuRDD.getNumPartitions)//See how many partitions there are
// take is also an action operator, which will return an Array
// The foreach here is actually the method of Array, not the operator of RDD
stuRDD.take(10).foreach(println)
//Process data by partition
stuRDD.mapPartitions(rdd=>rdd.map(_.split(",")(1)))foreach(println)
//Get an index when processing each partition
stuRDD.mapPartitionsWithIndex((index,rdd)=>{
println("Partition currently traversed:"+index)
rdd.map(line=>line.split(",")(1))
}).foreach(println)
}
}
filter
object DemoFilter {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DemoFilter")
val sc = new SparkContext(conf)
val listRDD: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7))
listRDD.filter(i=>i%2==0).foreach(println)//Filter out even numbers
listRDD.filter(_%2==1)//Equivalent to the above, it is a abbreviation
}
}
sample
Sampling operation, used to extract part of the data from the sample. withReplacement, whether to put back, fraction sampling scale, and seed are used to seed the specified random number generator. (whether to put back sampling is divided into true and false, fraction sampling scale is (0, 1). Seed seed is an integer real number
object DemoSample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DemoSample")
val sc = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("spark/data/student.txt")
val sm = stuRDD.sample(withReplacement = false, fraction = 0.1)
sm.foreach(println)
}
}
union
For the union of the source dataset and other datasets, no duplication is required.
object DemoUnion {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DemoUnion")
val sc= new SparkContext(conf)
val listRDD1: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7))
println(listRDD1.getNumPartitions)
val listRDD2: RDD[Int] = sc.parallelize(List(8, 9, 10))
println(listRDD2.getNumPartitions)
listRDD1.union(listRDD2).foreach(println)
}
}
join
join adds an RDD, calls on a dataSet of (k, v) and (k, w) types, and returns a pair dataSet of (k, (v, w)).
leftOuterJoin, rightOuterJoin... Are similar to the connection in MySQL. I won't say more
object DemoJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DemoJoin")
val sc = new SparkContext(conf)
// Build RDD in K-V format
val tuple2RDD1: RDD[(String, String)] = sc.parallelize(List(("001", "Zhang San"), "002" -> "Xiao Hong", "003" -> "Xiao Ming"))
val tuple2RDD2: RDD[(String, Int)] = sc.parallelize(List(("001", 20), "002" -> 22, "003" -> 21))
val tuple2RDD3: RDD[(String, String)] = sc.parallelize(List(("001", "male"), "002" -> "female"))
tuple2RDD1.join(tuple2RDD2).map{
case(id:String,(name:String,age:Int))=>id+","+name+","+age
}.foreach(println)//Equivalent to the following expression
tuple2RDD1.join(tuple2RDD2).map(kv => {
val i: String = kv._1
val j: String = kv._2._1
val k: Int = kv._2._2
i + "," + j + "," + k
}).foreach(println)
//leftOuterJoin
tuple2RDD1.leftOuterJoin(tuple2RDD3)
.map{
// Processing logic on Association
case (id: String, (name: String, Some(gender))) =>
id + "," + name + "," + gender
// Processing logic on unassociated
case (id: String, (name: String, None)) =>
id + "," + name + "," + "-"
}.foreach(println)
}
}
groupByKey
It is called on a PairRDD or (k,v) RDD and returns a (k, iteratable). Its main function is to group all the same key value pairs into a set sequence, and its order is uncertain. groupByKey loads all key value pairs into memory for storage and calculation. If there are too many corresponding values of a key, it is easy to cause memory overflow
object DemoGroupByKey {
def main(args: Array[String]): Unit = {
/**
* groupBy Specify the fields to group
*/
// Count the number of classes
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("DemoGroupByKey")
val sc: SparkContext = new SparkContext(conf)
// Reading student data to build RDD
val stuRDD: RDD[String] = sc.textFile("spark/data/students.txt")
stuRDD.groupBy(line => line.split(",")(4))
.map(kv => (kv._1, kv._2.size))
.foreach(println)
/**
* groupByKey On the RDD in K-V format, it is grouped by K by default
*/
stuRDD.map(line => (line.split(",")(4), line))
.groupByKey()
.map(kv => (kv._1, kv._2.size))
.foreach(println)
}
}
sort,sortBykey
It is also based on pairRDD and is sorted according to the key value. Ascending is ascending, which is true by default, that is, ascending; numTasks
def main(args: Array[String]): Unit = {
/**
* sortBy Conversion operator
* Specifies the default ascending order by which to sort
*
* sortByKey Conversion operator
* It needs to be used on the RDD in KV format. It is sorted directly by key, and the default ascending order is
*/
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("DemoSort")
val sc: SparkContext = new SparkContext(conf)
// Reading student data to build RDD
val stuRDD: RDD[String] = sc.textFile("spark/data/students.txt")
//ascending=false descending
stuRDD.sortBy(line=>line.split(",")(0),ascending=false)
.foreach(println)
stuRDD.map(line=>(line.split(",")(0),line))
.sortByKey(ascending=false)
.foreach(println)
}
}
MapValues
object DemoMapValues {
/**
* mapValues Conversion operator
* It needs to act on the RDD in K-V format
* Pass in a function f
* Pass the value of each piece of RDD data to the function f, and the key remains unchanged
* The size of the data will not change
*/
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DemoMapValues")
val sc = new SparkContext(conf)
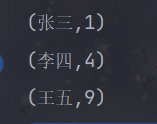
val listRDD: RDD[(String, Int)] = sc.parallelize(List(("Zhang San", 1), ("Li Si", 2), ("Wang Wu", 3)))
listRDD.mapValues(v=>v*v)
.foreach(println)
}
}
Common operators
object DemoAction {
def main(args: Array[String]): Unit = {
/**
* Operator (behavior operator): each action operator will trigger a job
* foreach,count,take,collect,reduce,saveAsTextFile
*/
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("DemoAction")
val sc: SparkContext = new SparkContext(conf)
// Reading student data to build RDD
val stuRDD: RDD[String] = sc.textFile("spark/data/students.txt")
// foreach
stuRDD.foreach(println)
// take takes out the first n pieces of data, which is equivalent to limit
stuRDD.take(100).foreach(println)
// count
// What is the amount of data returned by RDD
val l: Long = stuRDD.count()
println(l)
// collect
// Convert RDD to Array in Scala
// Note that the size of the data volume is easy to OOM
val stuArr: Array[String] = stuRDD.collect()
stuArr.take(10).foreach(println)
// reduce global aggregation
// select sum(age) from student group by 1
val i: Int = stuRDD.map(line => line.split(",")(2).toInt)
.reduce(_ + _)
println(i)
// save
stuRDD
.sample(withReplacement = false, fraction = 0.2)
.saveAsTextFile("spark/data/sample")
}
}