spark version 1.6.0, Scala version 2.12, jdk version 1.8. spark has been used recently and is recorded here.
One master and three workers, together with Hadoop-2.7.7 cluster, namdenode on master and two datanode s on worker 1 and worker 2.
List-1
192.168.33.30 worker1 master 192.168.33.31 worker2 192.168.33.32 worker3
Modify the host name of the master machine to be master, the host name of the worker2 machine to be node1, and the host name of the worker2 machine to be node2.
Place spark under / opt, as shown in List-2 below, on all three machines.
List-2
[root@master opt]# ll total 20 drwxr-xr-x 2 root root 22 4 Month 1313:51 applog drwxr-xr-x 11 root root 4096 4 Month 1116:31 hadoop-2.7.7 drwxr-xr-x 8 root root 4096 4 Month 1114:52 jdk1.8 drwxr-xr-x 6 root root 46 4 Month 1313:35 scala2.12 drwxr-xr-x 14 root root 4096 4 Month 1313:27 spark-1.6.0-bin-hadoop2.6
Master to two nodes of ssh dense, that is, on master ssh node 1/node 2 can face password.
/ etc/profile is List-3 below, which is done in master.
List-3
#spark export SPARK_HOME=/opt/spark-1.6.0-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin
The most important thing is the configuration file under spark's conf. On master, the following description is given:
1,spark-env.sh
cp spark-env.sh.template spark-env.sh, then modify the contents of spark-env.sh, as follows, and then replace the spark-env.sh of node1 and node2 with this file.
List-4
export JAVA_HOME=/opt/jdk1.8 export HADOOP_HOME=/opt/hadoop-2.7.7 export SCALA_HOME=/opt/scala2.12 export HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop export SPARK_MASTER_IP=master export SPARK_MASTER_PORT=7077 export SPARK_WORKDER_CORES=4 export SPARK_WORKER_MEMORY=1024m export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.7/bin/hadoop classpath);
2,spark-defaults.conf
cp, spark-defaults.conf.template, spark-defaults.conf, and then modify spark-defaults.conf, as shown in List-5 below. In addition, you manually build the / opt/applogs/spark-eventlog directory in hdfs to store the event log of spark. This file is then used to replace spark-defaults.conf for node1 and node2.
List-5
spark.eventLog.enabled true spark.eventLog.dir hdfs://master:9000/opt/applogs/spark-eventlog
3,log4j.properties
cp log4j.properties.template log4j.properties, modify log4j.properties, as follows List-6. Finally, replace this file with node1 and node2.
- The value of log4j.rootCategory ends with ", FILE".
- Add the contents of List-7, and the end result is List-6.
List-6
log4j.rootCategory=INFO, console,FILE log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n # Settings to quiet third party logs that are too verbose log4j.logger.org.spark-project.jetty=WARN log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR log4j.appender.FILE=org.apache.log4j.DailyRollingFileAppender log4j.appender.FILE.Threshold=INFO log4j.appender.FILE.file=/opt/applog/spark.log log4j.appender.logFile.Encoding = UTF-8 log4j.appender.FILE.layout=org.apache.log4j.PatternLayout log4j.appender.FILE.layout.ConversionPattern=[%-5p] [%d{yyyy-MM-dd HH:mm:ss}] [%C{1}:%M:%L] %m%n # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
List-7: Practical results show that the directory / opt/applog/spark.log is ultimately on the host, not on hdfs
log4j.appender.FILE=org.apache.log4j.DailyRollingFileAppender log4j.appender.FILE.Threshold=INFO log4j.appender.FILE.file=/opt/applog/spark.log log4j.appender.logFile.Encoding = UTF-8 log4j.appender.FILE.layout=org.apache.log4j.PatternLayout log4j.appender.FILE.layout.ConversionPattern=[%-5p] [%d{yyyy-MM-dd HH:mm:ss}] [%C{1}:%M:%L] %m%n
4,slaves
cp slaves.template slaves, modify the slaves file, List-8 below. Finally, replace the file on node1 and node2 with this file.
List-8: spark worker will be started on the host in this file
master node1 node2
start-all.sh in List-9 is executed on the master, and then a master and worker can be seen by jps command on the master, and a worker can be seen by jps command on node1/node2.
List-9
[root@node1 spark-1.6.0-bin-hadoop2.6]# pwd /opt/spark-1.6.0-bin-hadoop2.6 [root@node1 spark-1.6.0-bin-hadoop2.6]# sbin/start-all.sh
Enter http://192.168.33.30:8080/ in the browser and see the following
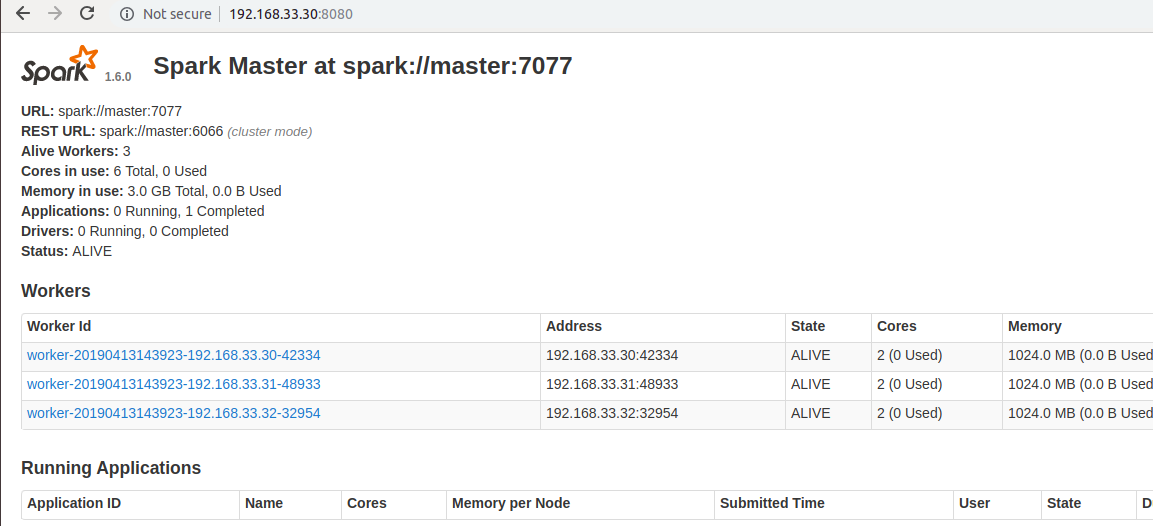
Figure 1
Reference:
- https://www.jianshu.com/p/91a98fd882e7