1. Local mode
- The so-called Local mode is an environment in which Spark code can be executed locally without any additional node resources
- Commonly used for teaching, debugging, presentations, etc. The environment in which code was previously run in IDEA is called a development environment, which is different.
1.1 Installation Configuration in Local Mode
gunzip
Upload the spark-3.0.0-bin-hadoop3.2.tgz file to Linux and uncompress it, place it in the specified location, do not include Chinese or spaces in the path, and do not emphasize if decompression is involved in subsequent courseware
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module cd /opt/module mv spark-3.0.0-bin-hadoop3.2 spark-local
1.2 Use of local mode
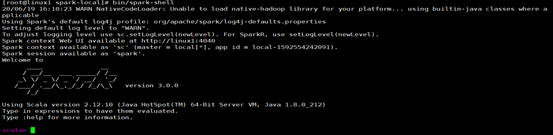
1. Start Local Environment
Enter the uncompressed path and launch the Local environment by executing the following instructions
bin/spark-shell
2.Web UI Monitor Page Access
http://Virtual Machine Address: 4040
This page can only be accessed while the Spark task is running and the task cannot be connected after execution

3 Command Line Tools
In the data directory under the unzipped folder, add the word.txt file. Execute the following code instructions in the command line tool (consistent with the code simplification version in IDEA)
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

4 Exit local mode
Press Ctrl+C or enter Scala command: quit
5 Submit an application
In practice, they are all developed in idea, then packaged into jar packages and submitted to the application
Submit a written program
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[2] \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10 --class Represents the main class of the program to be executed. Replace this with the application we wrote --master local[2] Deployment mode, default to local mode, Number represents allocated virtual CPU Number of cores [simultaneous Task Number of) spark-examples_2.12-3.0.0.jar Where the running application class is located jar Pack, can be set to play by ourselves when in use jar package The number 10 represents the program's entry parameters, which set the number of tasks currently applied
2. Standalone mode
Local mode has only one machine to operate on, but in real work you still have to submit the application to the appropriate cluster for execution
What is the standalone pattern?
- Spark itself can configure cluster mode, independent of external resource scheduling frameworks such as yarn, our so-called Standalone mode
- Spark's Stanalone pattern is also a classic master-slave architecture
2.1 standalone mode configuration
1. Cluster planning:

2. Unzip files
Upload the spark-3.0.0-bin-hadoop3.2.tgz file to Linux and unzip it in the specified location
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module cd /opt/module mv spark-3.0.0-bin-hadoop3.2 spark-standalone
3. Modify the configuration file
1.slavers configuration
- Enter the conf directory of the uncompressed path and modify the slaves.template file name to slaves
Remove suffix to take effect
mv slaves.template slaves
- Modify the slaves file to add a work node
hadoop102 hadoop103 hadoop104
2.master Configuration
- Modify the spark-env.sh.template file name to spark-env.sh configuration master
mv spark-env.sh.template spark-env.sh
- Modify the spark-env.sh file to add JAVA_HOME environment variable and master node corresponding to cluster
export JAVA_HOME=/opt/module/jdk1.8.0_144 SPARK_MASTER_HOST= hadoop102 SPARK_MASTER_PORT= 7077
Note: port 7077, equivalent to port 8020 for hadoop3 internal communications, needs to confirm its Hadoop configuration
3. Distribution Spark Home Directory
Distribute the spark-standalone directory because standalone is a cluster mode
xsync spark-standalone
2.2 Using standalone clusters
- Execute script command: sbin/start-all.sh start cluster

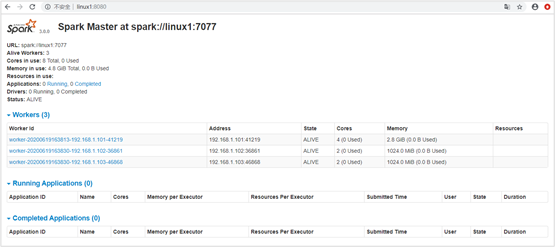
Start all, you can see that Master is started, then three Worker s are started
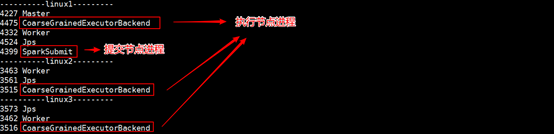
- View three server running processes
================linux1================ 3330 Jps 3238 Worker 3163 Master ================linux2================ 2966 Jps 2908 Worker ================linux3================ 2978 Worker 3036 Jps
- View the Master Resource Monitoring Web UI interface: http://hadoop102:8080
4 Submit an application
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop102:7077 \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10
- - class represents the main class of the program to be executed
- - master spark://linux1:7077 Stand-alone deployment mode, connecting to the Spark cluster
- Spark-examples_ The jar package where the 2.12-3.0.0.jar runtime class resides
- The number 10 represents the program's entry parameters, which set the number of tasks currently applied
When a task is executed, multiple Java processes are generated that are used to start the Task thread
3. yarn mode
Standalone mode provides computing resources by Spark itself without the need for other frameworks. This approach reduces the coupling with other third-party resource frameworks and is highly independent. However, you should also remember that Spark is primarily a computing framework, not a resource scheduling framework, so the resource scheduling provided by Spark itself is not its strength, so it is more reliable to integrate with other professional resource scheduling frameworks. So let's move on to learn how Spark works in a powerful Yarn environment (because Yarn uses a lot in its domestic work).
3.1 yarn mode configuration
1. Unzip the file
Upload the spark-3.0.0-bin-hadoop3.2.tgz file to linux and uncompress it, and place it in the specified location
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module cd /opt/module mv spark-3.0.0-bin-hadoop3.2 spark-yarn
2. Modify the configuration file
- Modify and distribute Hadoop configuration file/opt/module/hadoop/etc/hadoop/yarn-site.xml
<!--Whether to start a thread to check the amount of physical memory being used by each task and kill it if it exceeds the allocated value by default true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--Whether to start a thread to check the amount of virtual memory being used by each task and kill it if it exceeds the allocated value by default true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name> //
<value>false</value>
</property>
Yarn is a resource scheduling platform, resourcemanager allocates containers to a node that can't exceed one gigabyte of memory. If you want to use more than one gigabyte of memory, you violate the resources of other containers and you have to shut them down
- Modify conf/spark-env.sh to add JAVA_HOME and YARN_CONF_DIR Configuration
mv spark-env.sh.template spark-env.sh vim spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212 YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop #The directory where Yarn's profile is located so that Yarn can find the yarn-site.xml file
3.2 Using spark on yarn
- HDFS and YARN clusters must be started with this mode
bin/start-dfs.sh
bin/start-yarn.sh - Submit an application
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --The running environment is yarn --deploy-mode cluster \ --Cluster deployment mode ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10
4.Spark Submits Task Parameter Description
In submission applications, there are usually several submission parameters at the same time
bin/spark-submit \ --class <main-class> --master <master-url> \ ... # other options <application-jar> \ [application-arguments]
--class
Classes containing primary functions in Spark programs
--master
The mode (environment) in which the Spark program runs
- Local[*] indicates running in local mode
- spark://linux1:7077 Represents running in standalone mode
- Yarn indicates that the yarn environment is running
--executor-memory 1G
Specify 1 G of free memory per executor
Conform to cluster memory configuration, specific analysis
--total-executor-cores 2
Specifies that all executor s use two cpu cores
--executor-cores
Specify the number of cpu cores to use per executor
application-jar
- Packaged application jar with dependencies.
- This URL must be globally visible in the cluster.
For example, hdfs://Shared Storage System
If it is file:// path, then all nodes have the same jar in their path
application-arguments
Parameters passed to main() method