Pan Chuang AI sharing
Author | Md Sohel Mahmood Compile | VK Source: Towards Data Science
introduce
Classifying natural language is one of the great challenges facing natural language processing.
It involves techniques that can effectively distinguish between target text and normal text. Other services, such as chat robots, also rely heavily on text entered by users. They need to process a lot of data to determine user needs and guide the right path.
Use of Tensorflow
In the first part of this spam classifier, I showed how to use nltk package to analyze and classify text, and then input it into the classifier model to train and finally evaluate the performance of the model. I have demonstrated the performance of naive Bayes, SVC and random forest as e-mail classifiers.
https://towardsdatascience.com/ml-classifier-performance-comparison-for-spam-emails-detection-77749926d508
In this article, I will demonstrate how to token ize and effectively classify e-mail using Tensorflow. Let's start.
import numpy as np import pandas as pd import tensorflow as tf from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences
I've included pad_sequence, which will be used to make all text arrays equal in size. padding can be done according to the maximum size and can be post filled or pre filled. The superparameters are defined below
vocab_size = 1000 embedding_dim = 64 max_length = 120 trunc_type='post' padding_type='post' oov_tok = "<OOV>"
Users can use these parameters to prevent training data from over fitting. For example, you can reduce your vocabulary to minimize over fitting of low-frequency words. Similarly, the lower the embedding dimension, the faster the model can be trained. I also included a tag for words outside the vocabulary.
I will use the same dataset used in part 1.
spam = pd.read_csv('spam.csv', encoding='latin-1')
spam = spam.filter(['v1','v2'], axis=1)
spam.columns = ['label', 'text']
sentences = []
labels = []
for i in range(0,spam.shape[0],1):
sentences.append(spam['text'][i])
labels.append(spam['label'][i])
I have allocated 80% of the entire data set for training and the rest for testing.
training_size = int(spam.shape[0]*0.8) training_sentences = sentences[0:training_size] testing_sentences = sentences[training_size:] training_labels_str = labels[0:training_size] testing_labels_str = labels[training_size:]
Encode labels
Since the label of the dataset is a string, it will be converted to an integer by encoding it into 0 and 1 (0 for spam and 1 for real text).
training_labels = [0] * len(training_labels_str)
for ind,item in enumerate(training_labels_str):
if item == 'ham':
training_labels[ind] = 1
else:
training_labels[ind] = 0
testing_labels = [0] * len(testing_labels_str)
for ind,item in enumerate(testing_labels_str):
if item == 'ham':
testing_labels[ind] = 1
else:
testing_labels[ind] = 0
Next, you'll finish converting text and labels to numpy arrays.
training_padded = np.array(training_padded) testing_padded = np.array(testing_padded) training_labels = np.array(training_labels) testing_labels = np.array(testing_labels) tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok) tokenizer.fit_on_texts(training_sentences) word_index = tokenizer.word_index
As mentioned earlier, padding is required to make the array equal in length.
training_sequences = tokenizer.texts_to_sequences(training_sentences) training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type) testing_sequences = tokenizer.texts_to_sequences(testing_sentences) testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
Model definition
Then RNN and bidirectional LSTM algorithms are used to define the model. Here, bidirectional LSTM is used to obtain the best performance on RNN.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(1, activation='sigmoid')
])
adam = tf.keras.optimizers.Adam(learning_rate=0.0001, beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy',optimizer=adam,metrics=['accuracy'])
model.summary()
num_epochs = 20
history = model.fit(training_padded, training_labels, epochs=num_epochs, \
validation_data=(testing_padded, testing_labels), verbose=1)
Training model
After 20 epoch s, the model has been well trained, and the accuracy of the validation data (here is the test data) is about 98%
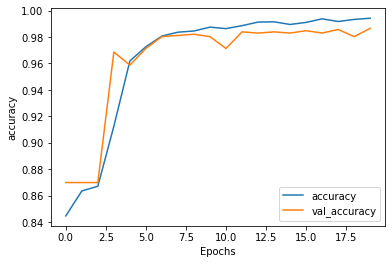
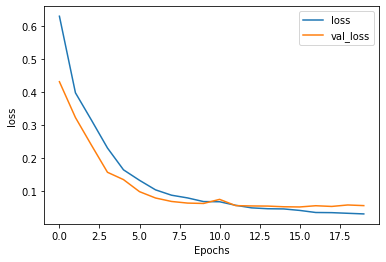
Then predict.
X_train = training_padded
X_test = testing_padded
y_train = training_labels
y_test = testing_labels
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
y_pred = model.predict(X_test)
# Convert forecast value to 0 or 1
y_prediction = [0] * y_pred.shape[0]
for ind,item in enumerate(y_pred):
if item > 0.5:
y_prediction[ind] = 1
else:
y_prediction[ind] = 0
rep = classification_report(y_test, y_prediction)
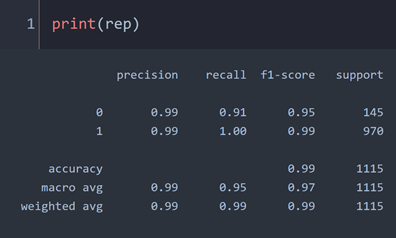
The report shows that the model has good accuracy, recall rate and F1 score for both text categories (0 for spam and 1 for normal mail). For 0, the recall rate is slightly lower than the accuracy, indicating that there are some false negatives. The model mistakenly recognizes some normal e-mails as spam.
We can identify any sample text to check whether it is spam or normal text. Since tokenizer is already defined, we no longer need to define it again. All we need is tokenize the sample text, fill it with 0, and then pass it to the model for prediction.
Choose some catchy words, such as "WINNER", "free" and "prize", which will eventually make this text detected as spam.
sample_text = ["Winner!!! Darling please click the link to claim your free prize"]
sample_text_tokenized = tokenizer.texts_to_sequences(sample_text)
sample_text_tokenized_padded = pad_sequences(sample_text_tokenized, maxlen=max_length, padding=padding_type, truncating=trunc_type)
# 0 is spam and 1 is normal
pred = float(model.predict(sample_text_tokenized_padded))
if (pred>0.5):
print ("This is a real email")
else:
print("This is a spam")
conclusion
This paper demonstrates how to use Tensorflow to effectively train NLP models with high accuracy, and then evaluate model performance parameters such as accuracy, recall and F1 score. With this small data set, it seems that 20 epoch s can generate an excellent model, and the verification accuracy is about 98%.
Github page: https://mdsohelmahmood.github.io/2021/06/23/Spam-email-classification-Part2-Tensorflow.html