brief introduction
The ONNX Runtime is an engine for ONNX(Open Neural Network Exchange) model reasoning. Microsoft, together with Facebook and other companies, launched an in-depth learning and machine learning model format standard - ONNX in 2017. Along the way, it provides an engine dedicated to ONNX model reasoning, onnxruntime. At present, the ONNX Runtime can only run at the HOST end, but the official website also indicates that the adaptation work for the mobile end is also in progress.
Half at work and half out of interest, I decided to read the source code of onnxruntime. Let's make a study record here.
install
The GitHub warehouse address of ONNX Runtime is https://github.com/microsoft/onnxruntime. For the compilation and installation process, please refer to the instructions on GitHub. For convenience, the installation source of PyPi is selected directly. implement
pip install onnxruntime
The installation is complete. Note that only Python 3 is supported.
start
Related documents
onnxruntime\onnxruntime\python\session.py
onnxruntime\onnxruntime\core\framework\utils.cc
onnxruntime\onnxruntime\python\onnxruntime_pybind_state.cc
onnxruntime\onnxruntime\core\session\inference_session.cc
onnxruntime\onnxruntime\core\session\inference_session.h
Code entry
Code reading needs to find an entry first. Through the example of onnxruntime, we know that using onnxruntime in Python is very simple. The main code is three lines:
import onnxruntime sess = onnxruntime.InferenceSession('YouModelPath.onnx') output = sess.run([output_nodes], {input_nodes: x})
The first line imports the onnxruntime module; the second line creates an instance of the InferenceSession and passes it a model address; the third line calls the run method for model reasoning. So the InferenceSession in the onnxruntime module is our entry point.
Instance generation
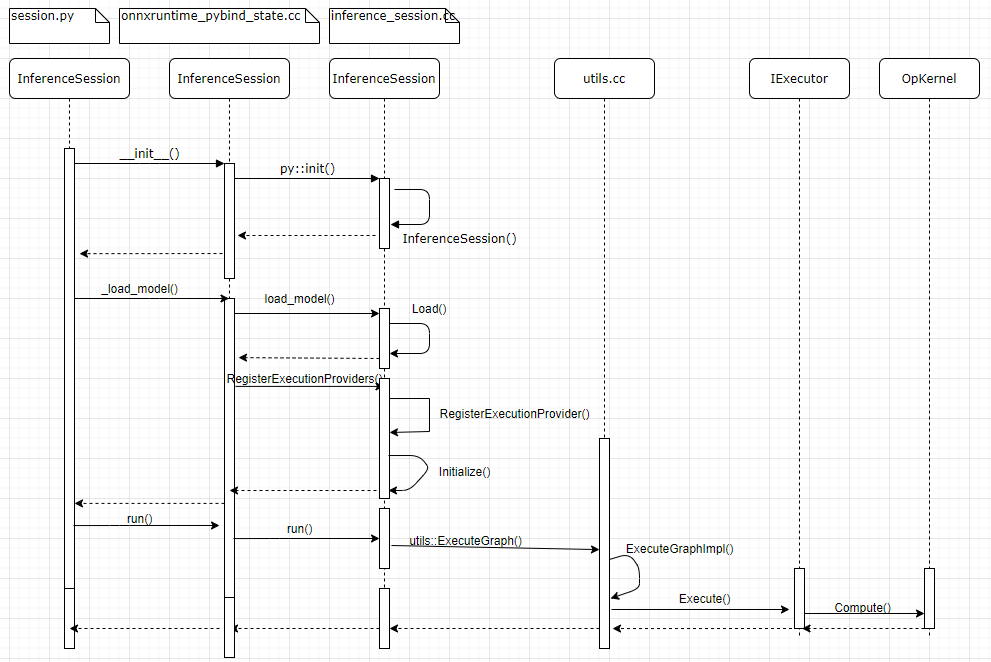
The code organization of ONNX Runtime is very good. We can easily find the file session.py where the InferenceSession is located. The whole file is very simple, and only one InferenceSession class is defined. By reading the ﹐ init ﹐ function of the InferenceSession,
def __init__(self, path_or_bytes, sess_options=None, providers=[]): """ :param path_or_bytes: filename or serialized model in a byte string :param sess_options: session options :param providers: providers to use for session. If empty, will use all available providers. """ self._path_or_bytes = path_or_bytes self._sess_options = sess_options self._load_model(providers) self._enable_fallback = True def _load_model(self, providers=[]): if isinstance(self._path_or_bytes, str): self._sess = C.InferenceSession( self._sess_options if self._sess_options else C.get_default_session_options(), self._path_or_bytes, True) elif isinstance(self._path_or_bytes, bytes): self._sess = C.InferenceSession( self._sess_options if self._sess_options else C.get_default_session_options(), self._path_or_bytes, False) # elif isinstance(self._path_or_bytes, tuple): # to remove, hidden trick # self._sess.load_model_no_init(self._path_or_bytes[0], providers) else: raise TypeError("Unable to load from type '{0}'".format(type(self._path_or_bytes))) # Pay attention to the following sentence, and we will come back to explain it in detail later self._sess.load_model(providers)
We found that the InferenceSession here is just a shell, and all the work has been entrusted to C.InferenceSession. From the import statement of C from onnxruntime.capi import ﹐ pybind ﹐ state as C, it can be seen that it is actually a python interface implemented in C language. Its source code is in onnxruntime \ onnxruntime \ Python \ onnxruntime ﹐ pybind ﹐ state.cc. Onnxruntime ﹣ pybind ﹣ state.cc is an interface that exposes C + + code to python, just like a door. After passing here, the code enters the world of C + + from python.
Here's the door. Where's the key?
We're looking at Python
self._sess = C.InferenceSession( self._sess_options if self._sess_options else C.get_default_session_options(), self._path_or_bytes, True)
It is the hope of the whole village. From this sentence, we know that there should be a class named InferenceSession defined in onnxruntime ﹣ pybind ﹣ state.cc. The operation is as fierce as a tiger. Locate where the InferenceSession is defined:
py::class_<InferenceSession>(m, "InferenceSession", R"pbdoc(This is the main class used to run a model.)pbdoc")
// In Python3, a Python bytes object will be passed to C++ functions that accept std::string or char*
// without any conversion. So this init method can be used for model file path (string)
// and model content (bytes)
.def(py::init([](const SessionOptions& so, const std::string& arg, bool is_arg_file_name) {
// Given arg is the file path. Invoke the corresponding ctor().
if (is_arg_file_name) {
return onnxruntime::make_unique<InferenceSession>(so, arg, SessionObjectInitializer::Get());
}
// Given arg is the model content as bytes. Invoke the corresponding ctor().
std::istringstream buffer(arg);
return onnxruntime::make_unique<InferenceSession>(so, buffer, SessionObjectInitializer::Get());
}))
Welcome to C + +. Def (py:: init ([] (const sessionoptions & so, const STD:: String & Arg, bool is "Arg" file "name) implements the function similar to" init "in Python. It constructs an instance by calling the corresponding constructor of the class" InferenceSession "in C + +, and then returns the pointer of this instance to python. Since the address string of the model is passed in our example, we need to find the signature type as follows:
InferenceSession(const SessionOptions& session_options,
const std::string& model_uri,
logging::LoggingManager* logging_manager = nullptr);
Constructor for.
Here is a strange phenomenon:
if (is_arg_file_name) {
return onnxruntime::make_unique<InferenceSession>(so, arg, SessionObjectInitializer::Get());
}
In the third parameter, we get an instance of the class SessionObjectInitializer by looking at SessionObjectInitializer::Get(), but the constructor corresponding to the InferenceSession corresponds to the required pointer of a logging::LoggingManager. How about it? We know that C + + is not like Python. C + + is a strongly typed language, and we will not make do with it. Here, the author uses a little trick. He defines two type conversion functions for SessionObjectInitializer, and asks the compiler to help him go to the required type. Here, the compiler will convert SessionObjectInitializer to logging::LoggingManager *.
Let's see.
InferenceSession(const SessionOptions& session_options,
const std::string& model_uri,
logging::LoggingManager* logging_manager = nullptr);
Implementation:
InferenceSession::InferenceSession(const SessionOptions& session_options,
const std::string& model_uri,
logging::LoggingManager* logging_manager)
: insert_cast_transformer_("CastFloat16Transformer") {
model_location_ = ToWideString(model_uri);
model_proto_ = onnxruntime::make_unique<ONNX_NAMESPACE::ModelProto>();
auto status = Model::Load(model_location_, *model_proto_);
ORT_ENFORCE(status.IsOK(), "Given model could not be parsed while creating inference session. Error message: ",
status.ErrorMessage());
// Finalize session options and initialize assets of this session instance
ConstructorCommon(session_options, logging_manager);
}
Here are three main things to do:
- Save the model address in the class member variable model "location";
- Save the binary content of the model in the class member variable model ﹣ proto ﹣;
- Call ConstructorCommon to do the rest of the work.
Do some environment checks in the constructor common, prepare log output, etc. The most important thing is to create a session state instance, session ﹣ state ﹣ which is a class member variable, which packs the thread pool, model structure, provider and other information needed to run the model. As for what a provider is, it's actually the hardware of the model, such as CPU or GPU. By now, many information in session state has not been completed, such as the model structure has not been saved, the provider is just a shell, there is no hardware information saved in it, and an initialization stage is needed. At this point, the creation of the InferenceSession instance is complete.
Initialization
Go back to the original starting point, where Python code begins, and the last sentence, self. \
.def( "load_model", [](InferenceSession* sess, std::vector<std::string>& provider_types) { OrtPybindThrowIfError(sess->Load()); InitializeSession(sess, provider_types); }, R"pbdoc(Load a model saved in ONNX format.)pbdoc")
The load? Model mainly does the following:
- Analyze the binary content of the model;
- Select the model running mode, parallel or serial;
- Select the model Provider. If the user does not specify a Provider, register the hardware supported in the current running environment, such as GPU, CPU, etc., and ensure that the CPU is available;
- Determine the running order of each node in the model.
Let's not go into details here, just know that it parses binary data into a graph according to the ONNX standard and stores it in session [stat]. I'll tell you more later. After this step, the session state is complete and ready for war.
Function
After initialization, everything is ready. Let's look directly at the run method of the InferenceSession in C + +, because as we know before, the operations in Python will eventually call the C + + code to execute the actual content. Although the InferenceSession overloads many run methods, it will eventually call the signature as
Status InferenceSession::Run(const RunOptions& run_options, const std::vector<std::string>& feed_names,
const std::vector<OrtValue>& feeds, const std::vector<std::string>& output_names,
std::vector<OrtValue>* p_fetches)
This one. Here, the run method checks the input data and passes the data, model information, provider information, etc. to utils::ExecuteGraph:
utils::ExecuteGraph(*session_state_, feeds_fetches_manager, feeds, *p_fetches,
session_options_.execution_mode,
run_options.terminate, run_logger))
The backhand of utils::ExecuteGraph entrusts the work to utils::ExecuteGraphImpl, and utils::ExecuteGraphImpl will find the nodes similar to the corresponding kernel according to the execution sequence of each node determined in the previous initialization, and call their Compute() method for calculation.
summary
A general process is to expose the C + + interface to Python by using pybind11, which is provided to users directly after simple encapsulation. There are several key points worth further study:
- Determine the execution order of model nodes;
- Model node Provider selection;
- Model analysis process;
- Detailed process of model reasoning;
- How to reason efficiently.
Finally, a picture is worth a thousand words: