The following links are personal opinions on detectron 2 (target detection framework). If there is any error, please point out it. I will correct it as soon as possible. Interested friends can add wechat: a944284742 to discuss technology with each other. If it helps you anything, remember to like it! Because it's the biggest encouragement for me.
Detectron 2 (target detection framework) no dead angle play-00: Directory
Preface
Through the previous introduction, we can say that we have a very good understanding of detectron 2 in general. Next, let's look at the construction of network model. Based on the previous explanation, all models have been and are known to exist in a container. To obtain the desired model from the container, the core code is located in detectron 2 / modeling / meta arch / build.py:
from detectron2.utils.registry import Registry META_ARCH_REGISTRY = Registry("META_ARCH") # noqa F401 META_ARCH_REGISTRY.__doc__ = """ def build_model(cfg): meta_arch = cfg.MODEL.META_ARCHITECTURE return META_ARCH_REGISTRY.get(meta_arch)(cfg)
It first loads the model container through meta arch Registry ("meta arch"), then constructs it through meta arch = retinaet, and obtains the retinaet model.
RetinaNet
The implementation of RetinaNet is located in / detectron 2 / modeling / meta arch / RetinaNet.py as follows:
@META_ARCH_REGISTRY.register() class RetinaNet(nn.Module):
The @ meta? Arch? Registry. Register() on it is to register the retinaet model into the meta? Arch? Registry container. First, let's look at the functions implemented by RetinaNet, as follows:
# Network front line communication def forward(self, batched_inputs): # Calculate loss def losses(self, gt_classes, gt_anchors_deltas, pred_class_logits, pred_anchor_deltas): # Combining with anchors to obtain ground truth def get_ground_truth(self, anchors, targets): # Network reasoning, if the size of the picture is the same, a single batch_ def inference(self, box_cls, box_delta, anchors, image_sizes): # Network reasoning: if the size of pictures is the same, they cannot be unified into one batch size, then reasoning is carried out one by one def inference_single_image(self, box_cls, box_delta, anchors, image_size): # Image preprocessing def preprocess_image(self, batched_inputs):
After a general understanding of the functions implemented, let's take a look at the initialization function of class RetinaNet:
def __init__(self, cfg): super().__init__() # GPU related designation self.device = torch.device(cfg.MODEL.DEVICE) # fmt: off, # 11 when training my dataset self.num_classes = cfg.MODEL.RETINANET.NUM_CLASSES # Default is ['p3 ',' P4 ',' P5 ',' P6 ',' P7 '] self.in_features = cfg.MODEL.RETINANET.IN_FEATURES # Loss parameters: the correlation coefficient of focal Hou loss and the smoothing coefficient of L1 self.focal_loss_alpha = cfg.MODEL.RETINANET.FOCAL_LOSS_ALPHA self.focal_loss_gamma = cfg.MODEL.RETINANET.FOCAL_LOSS_GAMMA self.smooth_l1_loss_beta = cfg.MODEL.RETINANET.SMOOTH_L1_LOSS_BETA # Inference parameters: self.score_threshold = cfg.MODEL.RETINANET.SCORE_THRESH_TEST self.topk_candidates = cfg.MODEL.RETINANET.TOPK_CANDIDATES_TEST self.nms_threshold = cfg.MODEL.RETINANET.NMS_THRESH_TEST # Maximum number of box es per picture self.max_detections_per_image = cfg.TEST.DETECTIONS_PER_IMAGE # fmt: on # Backbone network self.backbone = build_backbone(cfg) # The output shape of the feature map obtained from the backbone network mainly specifies the multiple of scaling, as follows: # p3 = ShapeSpec(channels=256, height=None, width=None, stride=8) # p4 = ShapeSpec(channels=256, height=None, width=None, stride=16) # p5 = ShapeSpec(channels=256, height=None, width=None, stride=32) # p6 = ShapeSpec(channels=256, height=None, width=None, stride=64) # ...... backbone_shape = self.backbone.output_shape() feature_shapes = [backbone_shape[f] for f in self.in_features] # Head model building, mainly building multiple branches, respectively box, confidence regression, and classification self.head = RetinaNetHead(cfg, feature_shapes) # According to the parameters of cfg configuration, generate anchor self.anchor_generator = build_anchor_generator(cfg, feature_shapes) # Matching and loss # Convert box (dx, dy, dw, dh) to center band and offset value self.box2box_transform = Box2BoxTransform(weights=cfg.MODEL.RPN.BBOX_REG_WEIGHTS) # The predicted box matches the ground truth self.matcher = Matcher( cfg.MODEL.RETINANET.IOU_THRESHOLDS, cfg.MODEL.RETINANET.IOU_LABELS, allow_low_quality_matches=True, ) # Average pixel level pixel_mean = torch.Tensor(cfg.MODEL.PIXEL_MEAN).to(self.device).view(3, 1, 1) # Standard deviation at pixel level pixel_std = torch.Tensor(cfg.MODEL.PIXEL_STD).to(self.device).view(3, 1, 1) # Regularization self.normalizer = lambda x: (x - pixel_mean) / pixel_std self.to(self.device)
In fact, through the creation of the above classes and functions, the process is outlined, but they only create classes and functions, which will be called in the back propagation. So let's take a look at retinaet's anti back propagation.
forward
def forward(self, batched_inputs): """ Args: batched_inputs: a list, batch Each item in the list con For now, each item in the * image: Tensor, image in * instances: Instances Other information that's * "height", "width" (int) See :meth:`postproces Returns: dict[str: Tensor]: mapping from a named loss """ # Batched input is a batch size # If it includes: 'file Ou name' = '/ data / ZWH / 0 # 'height' = 492 'width' = 65 # 'instances': some comments, such as the coordinate of semantic segmentation, the seat of box # The preprocess? Image function is used to images = self.preprocess_image(ba if "instances" in batched_inputs[ gt_instances = [x["instances" elif "targets" in batched_inputs[ log_first_n( logging.WARN, "'targets' ) gt_instances = [x["targets"]. else: gt_instances = None # The characteristic diagram P3 [24256,72,92], P4 [24,2] are obtained # The characteristic figure P5 [24256,9,12], P7 [24,25] are obtained features = self.backbone(images.t features = [features[f] for f in # The feature map is sent to the head together for fusion, and the box, confidence level are predicted, box_cls, box_delta = self.head(fe # Generate anchor anchors = self.anchor_generator(f # If it's training, calculate the loss in combination with the ground truth if self.training: gt_classes, gt_anchors_reg_de return self.losses(gt_classes # If it's training, return the predicted result else: results = self.inference(box_ processed_results = [] for results_per_image, input_ results, batched_inputs, ): height = input_per_image. width = input_per_image.g r = detector_postprocess( processed_results.append( return processed_results
English notes have not been cancelled here. Interested friends can read the following. Through the above notes, we should have a better understanding of the positive propagation of the network.
Input data source
Although it has been explained almost in 78-78, there is another problem, that is, in the process of forward propagation, that is, the source of the input of the forward (self, batched input) function, batched input is actually very easy to find. It is located at:
detectron2/engine/train_loop.py:
class SimpleTrainer(TrainerBase): def __init__(self, model, data_loader, optimizer):\ ...... def run_step(self): """ # Get the data of a batch ENU size. If necessary, you can decorate the dataloader If your want to do something with the data, you can wrap the dataloader. """ data = next(self._data_loader_iter) data_time = time.perf_counter() - start
The data is corresponding to the previously mentioned batched Ou inputs, which is displayed in the configuration and operation of the user as follows: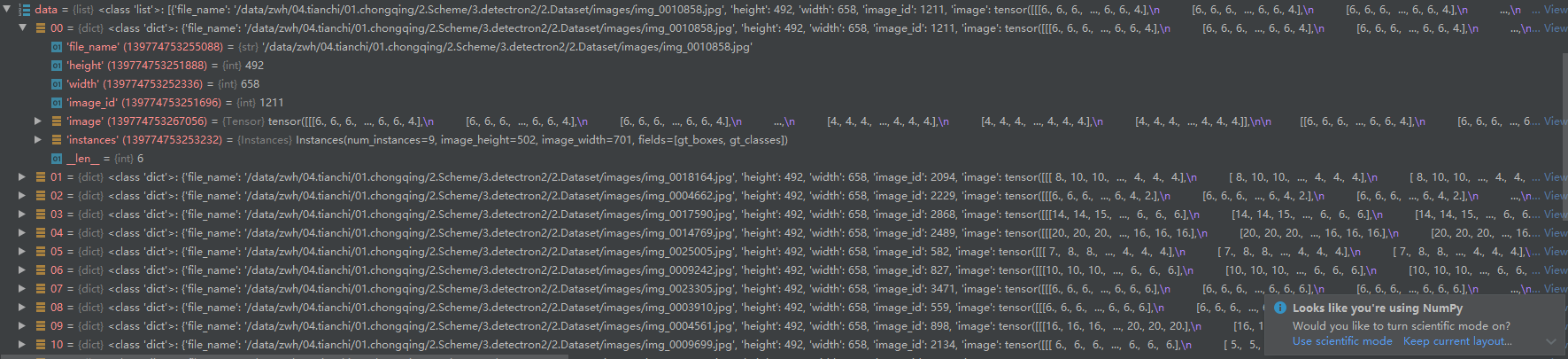
In fact, as mentioned before, it is:
Batched input is a batch size
If it includes: 'file Ou name' = '/ data / ZWH / 0
'height' = 492 'width' = 65
'instances': some comments, such as the coordinate of semantic segmentation, the coordinate of box
epilogue
So far, the analysis is more detailed. Later, we study data preprocessing, anchor, and loss calculation. Later on.
Come on, Wuhan, China. When peaches and plums are in full bloom, it must be the beginning for you and me to cook and work together!

