1. Introduction
Previous articles have provided a preliminary introduction to the use of quartz quartz-2.2.3 Source Code Analysis and Integration of Quartz and Spring In this article, the Quartz distributed cluster implementation is analyzed from the source code perspective.
2. Quartz Cluster
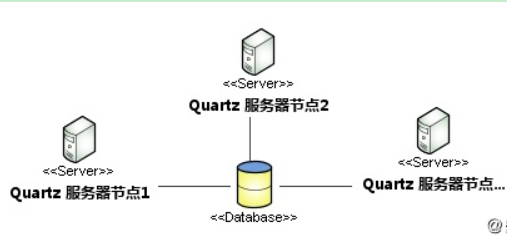
The Quartz cluster is based on database locks. Each node in a Quartz cluster is a separate Quartz application that manages other nodes.This means that you must start or stop each node separately.In a Quartz cluster, a stand-alone Quartz node does not communicate with another Quartz node or management node, but senses another Quartz application through the same database table.Cluster architecture:
Database tables

Table Information Introduction
qrtz_blob_triggers: A trigger stored as a Blob type.
qrtz_calendars stores alendar information for Quartz
qrtz_cron_triggers stores CronTrigger s, including Cron expressions and time zone information
qrtz_fired_triggers stores state information related to triggered Trigger s and execution information for associated Job s
qrtz_job_details stores the details of each configured Job
Information on pessimistic locks for the qrtz_locks stored program
qrtz_paused_trigger_grps stores information about suspended Trigger groups
qrtz_scheduler_state stores a small amount of state information about Scheduler, and other Scheduler instances
qrtz_simple_triggers stores simple Trigger s, including repetitions, intervals, and touches
qrtz_simprop_triggers stores two types of triggers, CalendarIntervalTrigger and DailyTimeIntervalTrigger
qrtz_triggers stores information about configured Trigger s
qrtz_locks is the row lock table for the synchronization mechanism of the Quartz cluster, including the following locks: CALENDAR_ACCESS, JOB_ACCESS, MISFIRE_ACCESS, STATE_ACCESS, TRIGGER_ACCESS
3. Source Code Analysis Quartz Cluster Synchronization Mechanism (Database Row Lock Table)
The source code is based on Quartz2.3.0.Starting with task scheduling QuartzScheduler Thread, the process of getting triggers in its run method
try {
triggers = qsRsrcs.getJobStore().acquireNextTriggers(
now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());
acquiresFailed = 0;
if (log.isDebugEnabled())
log.debug("batch acquisition of " + (triggers == null ? 0 : triggers.size()) + " triggers");
} catch (JobPersistenceException jpe) {
if (acquiresFailed == 0) {
qs.notifySchedulerListenersError(
"An error occurred while scanning for the next triggers to fire.",
jpe);
}
if (acquiresFailed < Integer.MAX_VALUE)
acquiresFailed++;
continue;
} catch (RuntimeException e) {
if (acquiresFailed == 0) {
getLog().error("quartzSchedulerThreadLoop: RuntimeException "
+e.getMessage(), e);
}
if (acquiresFailed < Integer.MAX_VALUE)
acquiresFailed++;
continue;
}JobStoreSupport.java
public List<OperableTrigger> acquireNextTriggers(final long noLaterThan, final int maxCount, final long timeWindow)
throws JobPersistenceException {
String lockName;
if(isAcquireTriggersWithinLock() || maxCount > 1) {
lockName = LOCK_TRIGGER_ACCESS;
} else {
lockName = null;
}
return executeInNonManagedTXLock(lockName,
new TransactionCallback<List<OperableTrigger>>() {
public List<OperableTrigger> execute(Connection conn) throws JobPersistenceException {
return acquireNextTrigger(conn, noLaterThan, maxCount, timeWindow);
}
},
new TransactionValidator<List<OperableTrigger>>() {
public Boolean validate(Connection conn, List<OperableTrigger> result) throws JobPersistenceException {
try {
List<FiredTriggerRecord> acquired = getDelegate().selectInstancesFiredTriggerRecords(conn, getInstanceId());
Set<String> fireInstanceIds = new HashSet<String>();
for (FiredTriggerRecord ft : acquired) {
fireInstanceIds.add(ft.getFireInstanceId());
}
for (OperableTrigger tr : result) {
if (fireInstanceIds.contains(tr.getFireInstanceId())) {
return true;
}
}
return false;
} catch (SQLException e) {
throw new JobPersistenceException("error validating trigger acquisition", e);
}
}
});
}Lock appears, lockName
protected static final String LOCK_TRIGGER_ACCESS = "TRIGGER_ACCESS"; protected static final String LOCK_STATE_ACCESS = "STATE_ACCESS";
Next, look at the process of acquiring locks
/**
* Execute the given callback having optionally acquired the given lock.
* This uses the non-managed transaction connection.
*
* @param lockName The name of the lock to acquire, for example
* "TRIGGER_ACCESS". If null, then no lock is acquired, but the
* lockCallback is still executed in a non-managed transaction.
*/
protected <T> T executeInNonManagedTXLock(
String lockName,
TransactionCallback<T> txCallback, final TransactionValidator<T> txValidator) throws JobPersistenceException {
boolean transOwner = false;
Connection conn = null;
try {
if (lockName != null) {
// If we aren't using db locks, then delay getting DB connection
// until after acquiring the lock since it isn't needed.
if (getLockHandler().requiresConnection()) {
conn = getNonManagedTXConnection();
}
//Acquire locks
transOwner = getLockHandler().obtainLock(conn, lockName);
}
if (conn == null) {
conn = getNonManagedTXConnection();
}
final T result = txCallback.execute(conn);
try {
commitConnection(conn);
} catch (JobPersistenceException e) {
rollbackConnection(conn);
if (txValidator == null || !retryExecuteInNonManagedTXLock(lockName, new TransactionCallback<Boolean>() {
@Override
public Boolean execute(Connection conn) throws JobPersistenceException {
return txValidator.validate(conn, result);
}
})) {
throw e;
}
}
Long sigTime = clearAndGetSignalSchedulingChangeOnTxCompletion();
if(sigTime != null && sigTime >= 0) {
signalSchedulingChangeImmediately(sigTime);
}
return result;
} catch (JobPersistenceException e) {
rollbackConnection(conn);
throw e;
} catch (RuntimeException e) {
rollbackConnection(conn);
throw new JobPersistenceException("Unexpected runtime exception: "
+ e.getMessage(), e);
} finally {
try {
releaseLock(lockName, transOwner);
} finally {
cleanupConnection(conn);
}
}
}/**
* Grants a lock on the identified resource to the calling thread (blocking
* until it is available).
*
* @return true if the lock was obtained.
*/
public boolean obtainLock(Connection conn, String lockName)
throws LockException {
if(log.isDebugEnabled()) {
log.debug(
"Lock '" + lockName + "' is desired by: "
+ Thread.currentThread().getName());
}
if (!isLockOwner(lockName)) {
//Execute sql to get locks
executeSQL(conn, lockName, expandedSQL, expandedInsertSQL);
if(log.isDebugEnabled()) {
log.debug(
"Lock '" + lockName + "' given to: "
+ Thread.currentThread().getName());
}
getThreadLocks().add(lockName);
//getThreadLocksObtainer().put(lockName, new
// Exception("Obtainer..."));
} else if(log.isDebugEnabled()) {
log.debug(
"Lock '" + lockName + "' Is already owned by: "
+ Thread.currentThread().getName());
}
return true;
}org.quartz.impl.jdbcjobstore.DBSemaphore
Look at these two values
private String expandedSQL;
private String expandedInsertSQL;
private void setExpandedSQL() {
if (getTablePrefix() != null && getSchedName() != null && sql != null && insertSql != null) {
expandedSQL = Util.rtp(this.sql, getTablePrefix(), getSchedulerNameLiteral());
expandedInsertSQL = Util.rtp(this.insertSql, getTablePrefix(), getSchedulerNameLiteral());
}
}Look at the acquisition of lockHandler first
private Semaphore lockHandler = null; // set in initialize() method...
initialize method
/**
* <p>
* Called by the QuartzScheduler before the <code>JobStore</code> is
* used, in order to give it a chance to initialize.
* </p>
*/
public void initialize(ClassLoadHelper loadHelper,
SchedulerSignaler signaler) throws SchedulerConfigException {
if (dsName == null) {
throw new SchedulerConfigException("DataSource name not set.");
}
classLoadHelper = loadHelper;
if(isThreadsInheritInitializersClassLoadContext()) {
log.info("JDBCJobStore threads will inherit ContextClassLoader of thread: " + Thread.currentThread().getName());
initializersLoader = Thread.currentThread().getContextClassLoader();
}
this.schedSignaler = signaler;
// If the user hasn't specified an explicit lock handler, then
// choose one based on CMT/Clustered/UseDBLocks.
if (getLockHandler() == null) {
// If the user hasn't specified an explicit lock handler,
// then we *must* use DB locks with clustering
if (isClustered()) {
setUseDBLocks(true);
}
if (getUseDBLocks()) {
if(getDriverDelegateClass() != null && getDriverDelegateClass().equals(MSSQLDelegate.class.getName())) {
if(getSelectWithLockSQL() == null) {
String msSqlDflt = "SELECT * FROM {0}LOCKS WITH (UPDLOCK,ROWLOCK) WHERE " + COL_SCHEDULER_NAME + " = {1} AND LOCK_NAME = ?";
getLog().info("Detected usage of MSSQLDelegate class - defaulting 'selectWithLockSQL' to '" + msSqlDflt + "'.");
setSelectWithLockSQL(msSqlDflt);
}
}
getLog().info("Using db table-based data access locking (synchronization).");
setLockHandler(new StdRowLockSemaphore(getTablePrefix(), getInstanceName(), getSelectWithLockSQL())); //handler assignment
} else {
getLog().info(
"Using thread monitor-based data access locking (synchronization).");
setLockHandler(new SimpleSemaphore());
}
}
}As if you had seen the assignment of sql and lockHandler
new StdRowLockSemaphore(getTablePrefix(), getInstanceName(), getSelectWithLockSQL())
// MISC CONSTANTS
String DEFAULT_TABLE_PREFIX = "QRTZ_";
getInstanceName() //Instance name in configuration file
getSelectWithLockSQL() //This is null because mssql is not used;
public StdRowLockSemaphore(String tablePrefix, String schedName, String selectWithLockSQL) {
super(tablePrefix, schedName, selectWithLockSQL != null ? selectWithLockSQL : SELECT_FOR_LOCK, INSERT_LOCK);
}
public static final String SELECT_FOR_LOCK = "SELECT * FROM "
+ TABLE_PREFIX_SUBST + TABLE_LOCKS + " WHERE " + COL_SCHEDULER_NAME + " = " + SCHED_NAME_SUBST
+ " AND " + COL_LOCK_NAME + " = ? FOR UPDATE";
public static final String INSERT_LOCK = "INSERT INTO "
+ TABLE_PREFIX_SUBST + TABLE_LOCKS + "(" + COL_SCHEDULER_NAME + ", " + COL_LOCK_NAME + ") VALUES ("
+ SCHED_NAME_SUBST + ", ?)";
public DBSemaphore(String tablePrefix, String schedName, String defaultSQL, String defaultInsertSQL) {
this.tablePrefix = tablePrefix;
this.schedName = schedName;
setSQL(defaultSQL);
setInsertSQL(defaultInsertSQL);
}There are two sql s, two lock names

You can see that the Quartz cluster uses pessimistic locking to lock the triggers table rows to ensure correct task synchronization.When a thread uses the SQL described above to perform operations on data in a table, the database locks the row; at the same time, another thread needs to acquire a lock before it can perform operations on that row and is occupied, so the thread can only wait until the row lock is released.
Go back to
private String expandedSQL;
//SELECT * FROM QRTZ_LOCKS WHERE SCHED_NAME = 'schedulerFactory' AND LOCK_NAME = ? FOR UPDATE
private String expandedInsertSQL;
//INSERT INTO QRTZ_LOCKS (SCHED_NAME, LOCK_NAME) VALUES ('schedulerFactory', ?);
private void setExpandedSQL() {
if (getTablePrefix() != null && getSchedName() != null && sql != null && insertSql != null) {
expandedSQL = Util.rtp(this.sql, getTablePrefix(), getSchedulerNameLiteral());
expandedInsertSQL = Util.rtp(this.insertSql, getTablePrefix(), getSchedulerNameLiteral());
}
}Two values confirm the process of acquiring the lock, where lockName is "TRIGGER_ACCESS"
org.quartz.impl.jdbcjobstore.StdRowLockSemaphore#executeSQL
/**
* Execute the SQL select for update that will lock the proper database row.
*/
@Override
protected void executeSQL(Connection conn, final String lockName, final String expandedSQL, final String expandedInsertSQL) throws LockException {
PreparedStatement ps = null;
ResultSet rs = null;
SQLException initCause = null;
// attempt lock two times (to work-around possible race conditions in inserting the lock row the first time running)
int count = 0;
do {
count++;
try {
ps = conn.prepareStatement(expandedSQL);
ps.setString(1, lockName);
if (getLog().isDebugEnabled()) {
getLog().debug(
"Lock '" + lockName + "' is being obtained: " +
Thread.currentThread().getName());
}
rs = ps.executeQuery();
if (!rs.next()) {
getLog().debug(
"Inserting new lock row for lock: '" + lockName + "' being obtained by thread: " +
Thread.currentThread().getName());
rs.close();
rs = null;
ps.close();
ps = null;
ps = conn.prepareStatement(expandedInsertSQL);
ps.setString(1, lockName);
int res = ps.executeUpdate();
if(res != 1) {
if(count < 3) {
// pause a bit to give another thread some time to commit the insert of the new lock row
try {
Thread.sleep(1000L);
} catch (InterruptedException ignore) {
Thread.currentThread().interrupt();
}
// try again ...
continue;
}
throw new SQLException(Util.rtp(
"No row exists, and one could not be inserted in table " + TABLE_PREFIX_SUBST + TABLE_LOCKS +
" for lock named: " + lockName, getTablePrefix(), getSchedulerNameLiteral()));
}
}
return; // obtained lock, go
} catch (SQLException sqle) {
//Exception src =
// (Exception)getThreadLocksObtainer().get(lockName);
//if(src != null)
// src.printStackTrace();
//else
// System.err.println("--- ***************** NO OBTAINER!");
if(initCause == null)
initCause = sqle;
if (getLog().isDebugEnabled()) {
getLog().debug(
"Lock '" + lockName + "' was not obtained by: " +
Thread.currentThread().getName() + (count < 3 ? " - will try again." : ""));
}
if(count < 3) {
// pause a bit to give another thread some time to commit the insert of the new lock row
try {
Thread.sleep(1000L);
} catch (InterruptedException ignore) {
Thread.currentThread().interrupt();
}
// try again ...
continue;
}
throw new LockException("Failure obtaining db row lock: "
+ sqle.getMessage(), sqle);
} finally {
if (rs != null) {
try {
rs.close();
} catch (Exception ignore) {
}
}
if (ps != null) {
try {
ps.close();
} catch (Exception ignore) {
}
}
}
} while(count < 4);
throw new LockException("Failure obtaining db row lock, reached maximum number of attempts. Initial exception (if any) attached as root cause.", initCause);
}The process of acquiring locks is also worth exploring.The way to acquire row locks, insert is guaranteed to acquire locks, because a select for update failure may also result in the absence of this data.
If there are already rows represented by lockName, lock them directly, if they are not inserted.However, it is possible to fail when locking or inserting, fail and retry, which throws an exception directly if it exceeds a certain number of times.
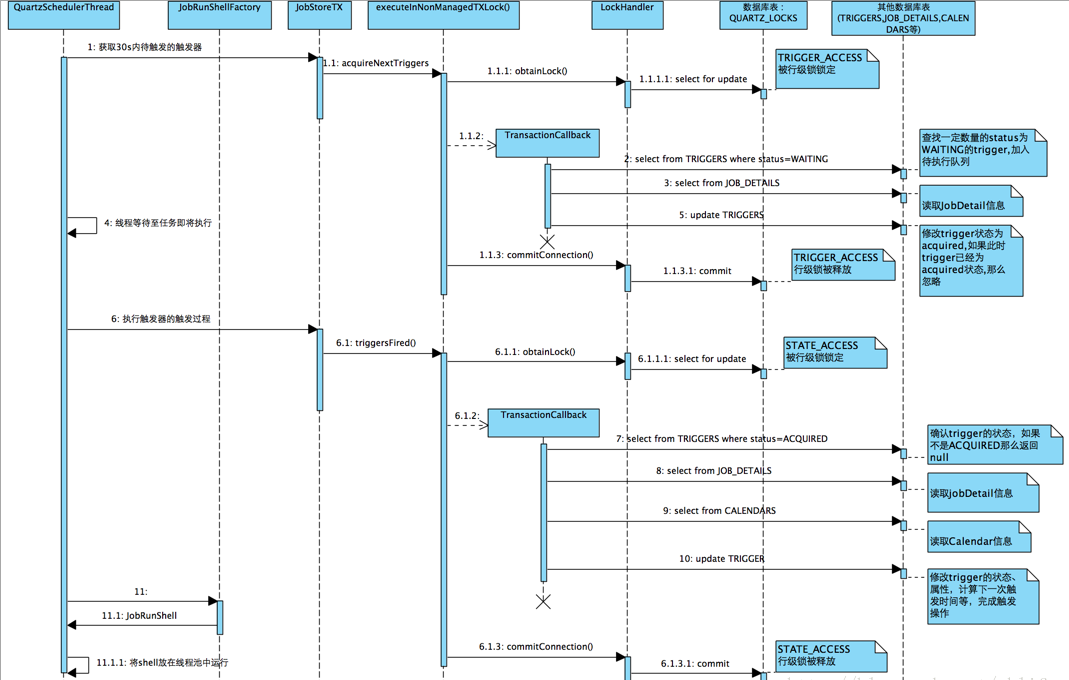
0. Scheduler thread run()
1. Get trigger to trigger
1.1 Database LOCKS Table TRIGGER_ACCESS Row Locking
1.2 Read JobDetail information
1.3 Read trigger information from the trigger table and mark it as Acquired
1.4 commit transaction, release lock
2. Trigger trigger
2.1 Database LOCKS Table STATE_ACCESS Row Locking
2.2 Confirm trigger status
2.3 Read JobDetail information for trigger
2.4 Read alendar information for trigger
2.3 Update trigger information
2.3commit transaction, release lock
3 Instantiate and execute Job
3.1 Get a thread from the thread pool to execute the run method of the JobRunShell
4. Summary
Before a dispatcher instance performs a database operation involving a distributed problem, it first acquires row-level locks on the corresponding previous dispatcher in the QUARTZ2_LOCKS table, and after acquiring the locks, it can perform database operations on other tables. With the submission of operational transactions, row-level locks are released, providing access to other dispatcher instances.

