When I read other blogs before, I found that there are two views in the defect analysis of kafka consumer's RoundRobin. One is that if the themes of consumer consumption in the consumer group are different or the number of consumer threads is different, the number of consumer consumption partitions will be inclined; Another view is that the disadvantage is that consumers will consume content that does not belong to their own theme, so this article is written in this context. If there is any mistake, please correct it.
PS: I think the first view is right. See the subsequent source code analysis. I don't know whether the second view is wrong or the old version of the source code.
Analysis of producer partition strategy
When messages are sent, they are sent to a topic, which is essentially a directory, and topic is composed of some partition logs
1) Reason for partition
(1) It is convenient to expand in the cluster. Each Partition can be adjusted to adapt to its machine, and a topic can be composed of multiple partitions. Therefore, the whole cluster can adapt to data of any size;
(2) Concurrency can be improved because you can read and write in Partition units.
2) Principle of zoning
We need to encapsulate the data sent by the producer into a producer record object.
The ProducerRecord class has the following constructor
ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) ProducerRecord(String topic, Integer partition, K key, V value) ProducerRecord(String topic, K key, V value) ProducerRecord(String topic, V value)
1. When the partition is specified, the specified value is directly used as the partition value;
2. If the partition is not specified but there is a key, the hash value of the key and the partition number of topic are used to obtain the partition value;
3. When there is neither partition value nor key value, an integer is randomly generated for the first call (it will increase automatically for each subsequent call), and the partition value is obtained by subtracting this value from the total number of partitions available for topic, that is, the commonly known round robin algorithm( (default)
The following is the DefaultPartitioner class source. We can also imitate it to implement the Partition interface and implement our own Partition:
package org.apache.kafka.clients.producer.internals;
/**
* The default partitioning strategy:
Default partition policy:
If a partition is given, use it
If there is no partition but there is a key, the partition is obtained according to the hash value of the key
If there are no partition and key values, sampling polling is performed
* <ul>
* <li>If a partition is specified in the record, use it
* <li>If no partition is specified but a key is present choose a partition based on a hash of the key
* <li>If no partition or key is present choose a partition in a round-robin fashion
*/
public class DefaultPartitioner implements Partitioner {
private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();
public void configure(Map<String, ?> configs) {}
public int partition(String topic, // theme
Object key, // Given key
byte[] keyBytes, // key serialized value
Object value, // Value to put in
byte[] valueBytes, // Serialized value
Cluster cluster) { // Current cluster
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
// Number of partitions corresponding to the topic
int numPartitions = partitions.size();
// If key is null
if (keyBytes == null) {
// Get the next partition value of topic polling, but it has not been taken
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
// Modulo the above partition value to get the real partition value
int part = Utils.toPositive(nextValue) % availablePartitions.size();
// Get the corresponding partition
return availablePartitions.get(part).partition();
} else {
// No partitions
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// After entering the key value, the partition number can be obtained by directly taking the module of the hash value of the key
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
// Self increasing
return counter.getAndIncrement();
}
public void close() {}
}
Consumer partition policy analysis
There are multiple consumers in a consumer group and multiple partitions in a topic, so it is bound to involve the allocation of partitions, that is, to determine which consumer consumes that partition.
Kafka has three allocation strategies, one is RoundRobin, one is Range, and the last one is sticky (only in the new version).
Trigger partition policy condition:
- New consumers in the same Consumer Group;
- Add new partitions for subscribed topics( (no partitions reduced)
- The consumer leaves the current Consumer Group, including shutdowns or crashes.
Trigger time: when the number of consumers in the consumer group changes( Including when the consumer starts and changes)
1) RoundRobin
List all partitions and all consumers, then sort according to hashcode, and finally allocate partitions to each consumer through polling algorithm.
Specific cases:
If there are three topics: T0 (three partitions P0-0, P0-1,P0-2), T1 (two partitions P1-0,P1-1), T2 (four partitions P2-0, P2-1, P2-2, P2-3)
There are three consumers: C0 (subscribed to T0, T1),C1 (subscribed to T1, T2) and C2 (subscribed to T0,T2)
The partitioning process is as follows:
Polling focuses on groups
The partitions will be arranged in a certain order (hashcode sort), the consumers will form a ring structure, and then start polling.
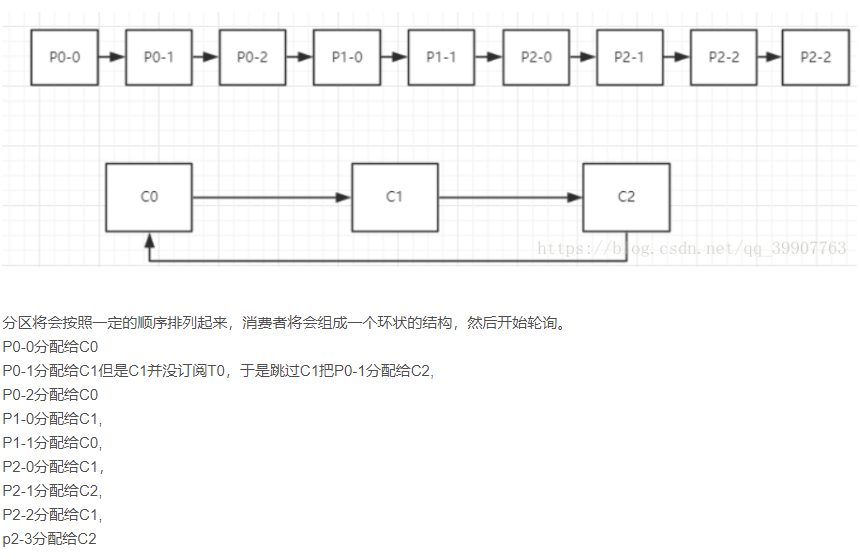
The result may be as follows:
C0: P0-0,P0-2,P1-1
C1: P1-0,P2-0,P2-2
C2: P0-1,P2-1,P2-3
advantage:
The difference in the number of messages between multiple consumers is within 1( The premise is that the consumption themes of consumers in the consumer group are the same, and the number of consumption threads of different consumers should be the same)
Disadvantages:
If consumers subscribe to different topics in a consumer group, one consumer may consume multiple partitions while other consumers consume few partitions.
//For example, if the consumption themes of consumers in the consumer group are different:
For example, there are three consumers
C0, C1, C2
3 There are three themes with 1, 2 and 3 partitions respectively
t0, t1, t2,
Then the topic partition relationship is as follows
t0p0, t1p0, t1p1, t2p0, t2p1, t2p2.
Assumptions:
C0 subscribe t0;
C1 subscribe t0, t1;
C2 subscribe t0, t1, t2.
The final distribution results are as follows:
C0: [t0p0]
C1: [t1p0]
C2: [t1p1, t2p0, t2p1, t2p2]
Therefore, the problem with this allocation method is that if consumers subscribe to different topics, it will lead to uneven resource allocation.
//The source code of RoundRobin partition is as follows:
public class RoundRobinAssignor extends AbstractPartitionAssignor {
public RoundRobinAssignor() {
}
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic, Map<String, Subscription> subscriptions) {
Map<String, List<TopicPartition>> assignment = new HashMap();
//Subscribed topics;
Iterator var4 = subscriptions.keySet().iterator();
while(var4.hasNext()) {
String memberId = (String)var4.next();
assignment.put(memberId, new ArrayList());
}
//Sort the consumer set to build a consumer ring, which is realized by taking the remainder of the total number through the index position + 1;
CircularIterator<String> assigner = new CircularIterator(Utils.sorted(subscriptions.keySet()));
Iterator var9 = this.allPartitionsSorted(partitionsPerTopic, subscriptions).iterator();
while(var9.hasNext()) {
TopicPartition partition = (TopicPartition)var9.next();
//Current theme;
String topic = partition.topic();
//Here, loop through to see if the consumer has subscribed to the topic. Otherwise, it will continue to the next consumer. The main function is to skip;
//Consumers who do not subscribe to this topic;
while(!((Subscription)subscriptions.get(assigner.peek())).topics().contains(topic)) {
assigner.next();
}
//Add partition information for the current consumer;
((List)assignment.get(assigner.next())).add(partition);
}
return assignment;
}
......
Scenario: therefore, it should be used when the topic subscribed by the current consumer group is the same;
2) Range (default policy)
The range partition strategy is for each topic and only focuses on a single consumer

First, the partitions in the same topic are sorted by serial number, and the consumers (not consumer groups) are sorted alphabetically. The number of partitions / consumers determines how many partitions each consumer should consume. If not, the first few consumers will consume one more partition.
range has nothing to do with groups. It is only sent to subscribed consumers, not to subscribed consumer groups
Disadvantages: as the number of topics increases, the number gap between different consumer consumption zones may become larger and larger( If one topic is less than one, multiple topics will be much less)
Scenario: different consumers subscribe to different topic s;
Note: under this partition strategy, the number of consumers in the same consumer group can be greater than the number of partitions, but idle consumers will be generated;
3) Sticky, this allocation strategy was introduced in kafka version 0.11.X. it is the most complex and excellent allocation strategy at present.
Its design mainly achieves two purposes:
- The distribution of partitions shall be as uniform as possible( The number of theme partitions allocated to these consumers should be as small as possible)
- The partition allocation shall be the same as the last allocation as far as possible( When partition rebalancing occurs, it retains as many existing assignments as possible.)
If the two objectives conflict, give priority to the first objective.
Add content:
//Here is the part of the core source code in the Sticky strategy to judge whether it is the best partition strategy. I haven't finished reading the whole. After the follow-up review, I can take a look at it first;
private boolean canParticipateInReassignment(TopicPartition partition,
Map<TopicPartition, List<String>> partition2AllPotentialConsumers) {
// if a partition has two or more potential consumers it is subject to reassignment.
return partition2AllPotentialConsumers.get(partition).size() >= 2;
}
private boolean canParticipateInReassignment(String consumer,
Map<String, List<TopicPartition>> currentAssignment,
Map<String, List<TopicPartition>> consumer2AllPotentialPartitions,
Map<TopicPartition, List<String>> partition2AllPotentialConsumers) {
List<TopicPartition> currentPartitions = currentAssignment.get(consumer);
int currentAssignmentSize = currentPartitions.size();
int maxAssignmentSize = consumer2AllPotentialPartitions.get(consumer).size();
if (currentAssignmentSize > maxAssignmentSize)
log.error("The consumer " + consumer + " is assigned more partitions than the maximum possible.");
if (currentAssignmentSize < maxAssignmentSize)
// if a consumer is not assigned all its potential partitions it is subject to reassignment
return true;
for (TopicPartition partition: currentPartitions)
// if any of the partitions assigned to a consumer is subject to reassignment the consumer itself
// is subject to reassignment
if (canParticipateInReassignment(partition, partition2AllPotentialConsumers))
return true;
return false;
}
We analyze with examples:
Purpose 1:
3 consumers
C0, C1, C2
3 themes
t0, t1, t2
The three topics have 1, 2 and 3 partitions respectively. The results are as follows
t0p0, t1p0, t1p1, t2p0,t2p1, t2p2
Assumptions:
C0 subscription t0
C1 subscription t0, t1
C2 subscription t0, t1, t2
The distribution results according to RoundRobin are as follows:
C0: [t0p0]
C1: [t1p0]
C2: [t1p1, t2p0, t2p1, t2p2]
Sticky's allocation results are as follows:
C0 [t0p0]
C1 [t1p0, t1p1]
C2 [t2p0, t2p1, t2p2]
Objective 2:
For example, if three consumers (C0, C1, C2) subscribe to two topics (T0 and T1) and each topic has three partitions (P0, P1, p2), then all the partitions subscribed can be identified as T0p0, T0p1, T0p2, T1p0, T1p1, T1p2. At this time, after using the Sticky allocation strategy, the partition allocation results are as follows:
| Consumer thread | Consumption partition serial number |
|---|---|
| C0 | T0p0,T1p0 |
| C1 | T0p1,T1p1 |
| C2 | T0p2,T1p2 |
At this time, you will find that the partition results here are very similar to the RoundRobin partition policy, but the underlying layer is different. If it is the RoundRobin partition policy, the results are:
| Consumer thread | Consumption partition serial number |
|---|---|
| C0 | T0p0,T0p2,T1p1 |
| C1 | T0p1,T1p0,T1p2 |
If it is a Sticky partition policy, the result is:
| Consumer thread | Consumption partition serial number |
|---|---|
| C0 | T0p0,T1p0,T0p2 |
| C1 | T0p1,T1p1,T1p2 |
Carefully observe the serial number of the consumption partition after re partition. It will be found that C0 still contains T0p0 and T1p0 partitions, while C1 still contains T0p1 and T1p1 partitions; Then, T0p2 and T1p2 partitions originally belonging to C2 are allocated to C0 and C1 consumers. At this time, both partitions will not be allocated to C0 or C1, because this violates the first condition;
Why design like this?
This is because after partition reallocation, for the same partition, the previous consumers and the newly assigned consumers may not be the same, and half of the previous consumers have to be processed in the newly assigned consumers
Processing once at a time will waste system resources.