1, Why use ConcurrentHashMap
Using HashMap in concurrent programming may lead to program loop, but using thread safe HashTable is very inefficient. In order to solve this problem, ConcurrentHashMap came out.
1) For thread unsafe HashMap, in a multithreaded environment, using HashMap for put operation will cause an endless loop (JDK1.7), which will lead to the problem of data coverage in JDK1.8.
2) For an inefficient HashTable, HashTable uses synchronized to ensure thread safety. In the case of fierce thread competition, the efficiency of HashTable is very low. When a thread asks for the synchronization method of HashTable, other threads also access the synchronization method of HashTable, it will enter the blocking or polling state, which is very inefficient.
2, ConcurrentHashMap - JDK 1.7
In JDK 1.7, Java uses the Segment lock mechanism to implement ConcurrentHashMap. ConcurrentHashMap saves a Segment array in the object, that is, the whole hash table is divided into multiple segments; Each Segment element, that is, each Segment, is similar to a Hashtable; In this way, when performing the put operation, first locate the Segment to which the element belongs according to the hash algorithm, and then lock the Segment. Therefore, concurrent HashMap can implement multi-threaded put operation in multi-threaded concurrent programming.
structure
The entire ConcurrentHashMap consists of segments, which represent "part" or "paragraph" "Means, so it is described in many places as a segment lock, which can also be called a slot. In short, ConcurrentHashMap is an array of segments. Segments are locked by inheriting ReentrantLock, so each operation that needs to be locked locks a segment. In this way, as long as each segment is thread safe, it can achieve global locking Thread safe.
The following is the structure of ConcurrentHashMap:
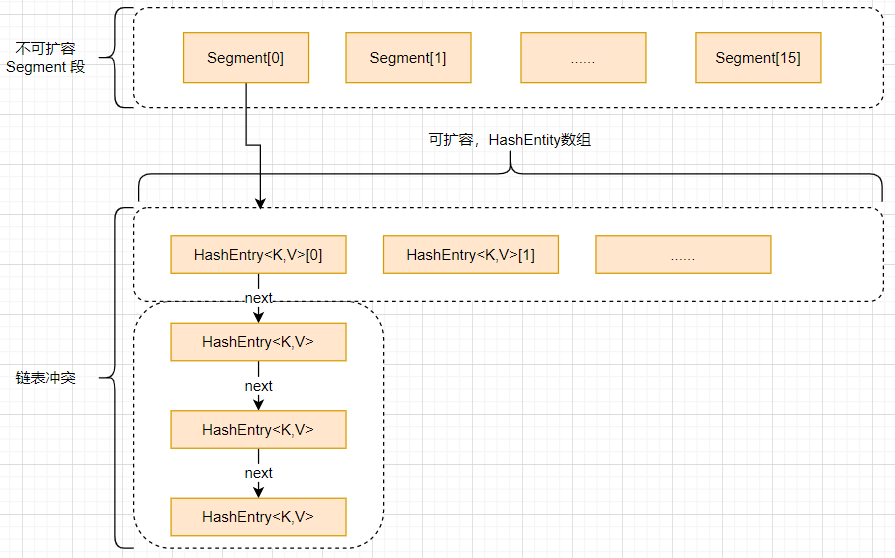
Once initialized, the number of segments cannot be changed. By default, the number of segments is 16. It can be considered that concurrent HashMap supports up to 16 threads by default.
initialization
Explore the initialization process of ConcurrentHashMap through the parameterless construction of ConcurrentHashMap.
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
The reference structure is called in the parameter free structure, and the default values of the three parameters are passed in.
// Default initialization capacity static final int DEFAULT_INITIAL_CAPACITY = 16; // Default load factor static final float DEFAULT_LOAD_FACTOR = 0.75f; // Default concurrency level static final int DEFAULT_CONCURRENCY_LEVEL = 16;
Next, let's look at the internal implementation logic of the parametric constructor:
- concurrencyLevel: parallel level, concurrent number, and number of segments. The default value is 16, as explained above.
- initialCapacity: initial capacity. This value refers to the initial capacity of the entire ConcurrentHashMap. It needs to be evenly distributed to each Segment during actual operation.
- loadFactor: load factor. The Segment array cannot be expanded, so this load factor is used internally for each Segment.
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
// Parameter verification
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException();
// Verify the concurrency level size, greater than 1 < < 16, reset to 65536
if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS;
// What is the power of 2
int sshift = 0;
int ssize = 1;
// This loop can find the nearest power value of 2 above the concurrencyLevel
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// Record segment offset
this.segmentShift = 32 - sshift;
// Record segment mask
this.segmentMask = ssize - 1;
// Set capacity
if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY;
// c = capacity / ssize, default 16 / 16 = 1. Here is the capacity similar to HashMap in each Segment
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity) ++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
//The HashMap like capacity in Segment is at least 2 or a multiple of 2
while (cap < c) cap <<= 1;
// Create a Segment array and create the first element segments[0] of the array
Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
// Write segment[0] to array
UNSAFE.putOrderedObject(ss, SBASE, s0);
this.segments = ss;
}
To summarize the initialization logic of ConcurrnetHashMap in Java 7:
1) Necessary parameter verification.
2) Verify the concurrency level size. If it is greater than the maximum value, reset it to the maximum value. The default value for nonparametric construction is 16.
3) Find the power value of the nearest 2 above the concurrency level as the initialization capacity. The default is 16.
4) Record the segmentShift offset, which is N in [capacity = 2 to the nth power], and the default is 32 - sshift = 28.
5) Record the segmentMask, which is ssize - 1 = 16 -1 = 15 by default, and the segmentShift will be used in the put operation.
6) Initialize segments[0], other locations are still null.
The default size of Segment[i] is 2, the load factor is 0.75, and the initial threshold is 1.5, that is, inserting the first element will not trigger capacity expansion, and inserting the second element will carry out the first capacity expansion
put process
Let's first look at the main process of put:
public V put(K key, V value) {
Segment<K,V> s;
if (value == null) throw new NullPointerException();
// 1. Calculate the hash value of the key
int hash = hash(key);
// 2. Find the position j in the Segment array according to the hash value
// hash is 32 bits, shift the segmentShift(28) bits to the right without sign, leaving the upper 4 bits,
// Then perform an and operation with segmentMask(15), that is, j is the upper 4 bits of the hash value, that is, the array subscript of the slot
int j = (hash >>> segmentShift) & segmentMask;
// As I just said, segment[0] is initialized during initialization, but other locations are still null
// Ensuesegment (J) initializes segment[j]
if ((s = (Segment<K,V>) UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
// 3. Insert the new value into slot s
return s.put(key, hash, value, false);
}
The first layer is very simple. You can quickly find the corresponding Segment according to the hash value, and then the put operation inside the Segment, which is composed of array + linked list.
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// Before writing to the segment, you need to obtain the exclusive lock of the segment
// Let's look at the main process first, and we will introduce this part in detail later
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
// This is an array inside segment
HashEntry<K,V>[] tab = table;
// Then use the hash value to find the array subscript that should be placed
int index = (tab.length - 1) & hash;
// first is the header of the linked list at this position of the array
HashEntry<K,V> first = entryAt(tab, index);
// Although the following string of for loops is very long, it is also easy to understand. Think about the two cases where there are no elements at this position and there is already a linked list
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key || (e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
// Overwrite old value
e.value = value;
++modCount;
}
break;
}
// Continue to follow the linked list
e = e.next;
}
else {
// Whether the node is null or not depends on the process of obtaining the lock, but it has nothing to do with here.
// If it is not null, it is directly set as the linked list header; if it is null, it is initialized and set as the linked list header.
if (node != null) node.setNext(first);
else node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// If the threshold of the segment is exceeded, the segment needs to be expanded
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node); // The expansion will also be analyzed in detail later
else
// If the threshold is not reached, put the node in the index position of the array tab
// In fact, the new node is set as the header of the original linked list
setEntryAt(tab, index, node);
++ modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// Unlock
unlock();
}
return oldValue;
}
The overall process is relatively simple. Due to the protection of exclusive lock, the internal operation of segment is not complex. Here, the put operation is over.
Initialize slot ensuesegment
The first slot segment[0] will be initialized during the initialization of ConcurrentHashMap. For other slots, it will be initialized when the first value is inserted. Concurrency needs to be considered here, because multiple threads may come in to initialize the same slot segment[k] at the same time, but as long as one succeeds.
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// Here we see why segment[0] should be initialized before,
// Initialize segment[k] with the array length and load factor at the current segment[0]
// Why use "current" because segment[0] may have been expanded long ago
Segment<K,V> proto = ss[0];
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
// Initializes an array inside segment[k]
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
// Check again whether the slot is initialized by other threads
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// Use the while loop and CAS internally. After the current thread successfully sets the value or other threads successfully set the value, exit
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
In general, ensuesegment (int k) is relatively simple. CAS is used to control concurrent operations.
Get write lock scanandlockforward
As we saw earlier, when putting into a segment, we first call node = tryLock()? Null: scanAndLockForPut (key, hash, value), that is, first perform a tryLock() to quickly obtain the exclusive lock of the segment. If it fails, enter the scanAndLockForPut method to obtain the lock. Let's specifically analyze how locking is controlled in this method:
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// Cyclic lock acquisition
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
// Go here to explain that the linked list at this position of the array is empty and has no elements
// Of course, another reason for entering here is that tryLock() fails, so concurrency exists in this slot, not necessarily in this location
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key)) retries = 0;
else
// Go down the list
e = e.next;
}
// If the number of retries exceeds max_ SCAN_ Restries (single core 1 multi-core 64), then do not rob, enter the blocking queue and wait for the lock
// lock() is a blocking method until it returns after obtaining the lock
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
// At this time, there is a big problem, that is, new elements enter the linked list and become a new header
// So the strategy here is to go through the scanAndLockForPut method again
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
This method has two exits. One is that tryLock() succeeds and the loop terminates. The other is that the number of retries exceeds max_ SCAN_ Restries, go to the lock() method, which will block and wait until the exclusive lock is successfully obtained. This method seems complex, but it actually does one thing, that is, obtain the exclusive lock of the segment, and instantiate the node if necessary.
Capacity expansion rehash
The segment array cannot be expanded. The expansion is the expansion of the internal array hashentry < K, V > [] in a certain position of the segment array. After the expansion, the capacity is twice the original capacity. During the put element, if it is judged that the insertion of the value will cause the number of elements of the segment to exceed the threshold, expand the capacity first and then interpolate. This method does not need to consider concurrency, because when it comes here, it holds the exclusive lock of the segment.
// The node on the method parameter is the data to be added to the new array after this expansion.
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 2x
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
// Create a new array
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
// If the new mask is expanded from 16 to 32, the sizeMask is 31, corresponding to binary '000... 00011111'
int sizeMask = newCapacity - 1;
// Traverse the original array, the old routine, and split the linked list at position i of the original array into two positions i and i+oldCap of the new array
for (int i = 0; i < oldCapacity ; i++) {
// e is the first element of the linked list
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// Calculate where it should be placed in the new array,
// Assuming that the length of the original array is 16 and e is at oldTable[3], idx can only be 3 or 3 + 16 = 19
int idx = e.hash & sizeMask;
// There is only one element at this position, which is easier to do
if (next == null) newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// e is the linked list header
HashEntry<K,V> lastRun = e;
// idx is the new position of the head node e of the current linked list
int lastIdx = idx;
// The following for loop will find a lastRun node, after which all elements will be put together
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// Put the linked list composed of lastRun and all subsequent nodes in the position of lastIdx
newTable[lastIdx] = lastRun;
// The following operations are to process the nodes before lastRun,
// These nodes may be assigned to another linked list or to the above linked list
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// Put the new node in the head of one of the two linked lists in the new array
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
get procedure
1) Calculate the hash value and find the specific position in the segment array, or the "slot" we used earlier.
2) The slot is also an array. Find the specific position in the array according to the hash.
3) Follow the linked list to find it.
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
// 1. hash value
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 2. Find the corresponding segment according to the hash
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 3. Find the linked list at the corresponding position of the internal array of segment and traverse
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
Both the put operation of adding nodes and the remove operation of deleting nodes need to add the exclusive lock on the segment, so there will be no problem between them. The problem we need to consider is that the put or remove operation occurs in the same segment during get.
Thread safety of put operation:
1) The initialization slot, which we mentioned earlier, uses CAS to initialize the array in the Segment.
2) The operation of adding nodes to the linked list is inserted into the header. Therefore, if the get operation is in the middle of the process of traversing the linked list at this time, it will not be affected. Of course, another concurrency problem is that after put, the node just inserted into the header needs to be read. This depends on the UNSAFE.putOrderedObject used in the setEntryAt method.
3) Capacity expansion is to create a new array, then migrate the data, and finally set the newTable to the attribute table. Therefore, if the get operation is also in progress at this time, it doesn't matter. If get goes first, it is to query the old table; If put comes first, the visibility guarantee of put operation is that table uses volatile keyword.
Thread safety of remove operation:
1) The get operation needs to traverse the linked list, but the remove operation will "destroy" the linked list.
2) If the get operation of the remove broken node has passed, there is no problem here.
3) If remove destroys a node first, consider two cases. 1. If this node is a head node, you need to set the next of the head node to the element at this position of the array. Although table uses volatile decoration, volatile does not provide visibility assurance for internal operations of the array. Therefore, UNSAFE is used in the source code to operate the array. See the method setEntryAt. 2. If the node to be deleted is not the head node, it will connect the successor node of the node to be deleted to the predecessor node. The concurrency guarantee here is that the next attribute is volatile.
3, ConcurrentHashMap - JDK 1.8
structure
Prior to JDK1.7, ConcurrentHashMap was implemented through the Segment lock mechanism, so its maximum concurrency is limited by the number of segments. Therefore, in JDK1.8, the implementation principle of ConcurrentHashMap abandons this design, but selects the method of array + linked list + red black tree similar to HashMap, while CAS and synchronized are used for locking.
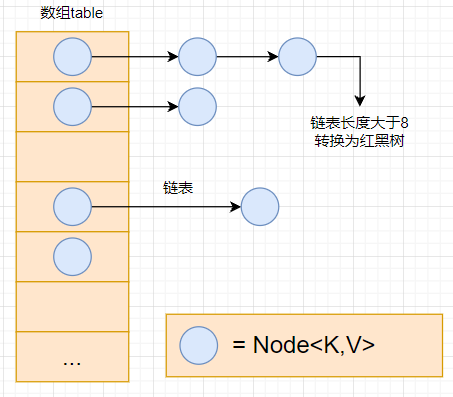
The structure is basically the same as the HashMap of Java 8, but it needs to ensure thread safety, so it really needs to be complex in the source code.
initialization
// There's nothing to do here
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0) throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
By providing the initial capacity, sizeCtl is calculated, sizeCtl = [(1.5 * initialCapacity + 1), and then take the nth power of the nearest 2 upward]
put process
Direct source code:
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// Get hash value
int hash = spread(key.hashCode());
// Used to record the length of the corresponding linked list
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// If the array is empty, initialize the array
if (tab == null || (n = tab.length) == 0)
// Initialize the array, which will be described in detail later
tab = initTable();
// Find the array subscript corresponding to the hash value to get the first node f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// If the array is empty,
// Use a CAS operation to put the new value into it. The put operation is almost over and can be pulled to the last side
// If CAS fails, there are concurrent operations. Just go to the next cycle
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break;
}
// hash can be equal to MOVED. This can only be seen later, but you can guess from the name. It must be because of capacity expansion
else if ((fh = f.hash) == MOVED)
// Help with data migration. It's easy to understand this after reading the introduction of data migration
tab = helpTransfer(tab, f);
else { // That is to say, f is the head node of this position, and it is not empty
V oldVal = null;
// Gets the monitor lock of the head node of the array at this position
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // The hash value of the header node is greater than 0, indicating that it is a linked list
// Used to accumulate and record the length of the linked list
binCount = 1;
// Traversal linked list
for (Node<K,V> e = f;; ++binCount) {
K ek;
// If an "equal" key is found, judge whether to overwrite the value, and then you can break
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// At the end of the linked list, put the new value at the end of the linked list
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // Red black tree
Node<K,V> p;
binCount = 2;
// Call the interpolation method of red black tree to insert a new node
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent) p.val = value;
}
}
}
}
if (binCount != 0) {
// Determine whether to convert the linked list into a red black tree. The critical value is the same as HashMap, which is 8
if (binCount >= TREEIFY_THRESHOLD)
// This method is slightly different from that in HashMap, that is, it does not necessarily carry out red black tree conversion,
// If the length of the current array is less than 64, you will choose to expand the array instead of converting to a red black tree
// We won't look at the specific source code. We'll talk about it later in the expansion part
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
Initialize array initTable
This is relatively simple. It mainly initializes an array of appropriate size, and then sets sizeCtl. The concurrency problem in the initialization method is controlled by performing a CAS operation on sizeCtl.
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// The "credit" of initialization was "robbed" by other threads
if ((sc = sizeCtl) < 0) Thread.yield();
// CAS, set sizeCtl to - 1, which means that the lock has been robbed
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// DEFAULT_ The default initial capacity of capability is 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// Initialize the array with a length of 16 or the length provided during initialization
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// Assign this array to table, which is volatile
table = tab = nt;
// If n is 16, then sc = 12
// It's actually 0.75 * n
sc = n - (n >>> 2);
}
} finally {
// Set sizeCtl to sc, let's take it as 12
sizeCtl = sc;
}
break;
}
}
return tab;
}
Linked list to red black tree treeifyBin
We also said in the put source code analysis earlier that treeifyBin does not necessarily carry out red black tree conversion, or it may only do array expansion.
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
// MIN_ TREEIFY_ Capability is 64
// Therefore, if the array length is less than 64, that is, 32 or 16 or less, the array capacity will be expanded
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
// We will analyze this method in detail later
tryPresize(n << 1);
// b is the head node
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
// Lock
synchronized (b) {
if (tabAt(tab, index) == b) {
// The following is to traverse the linked list and establish a red black tree
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null);
if ((p.prev = tl) == null) hd = p;
else tl.next = p;
tl = p;
}
// Set the red black tree to the corresponding position of the array
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
Capacity expansion tryprevize
The capacity expansion here is also doubled. After expansion, the array capacity is twice that of the original.
// First of all, the method parameter size has doubled when it is passed in
private final void tryPresize(int size) {
// c: 1.5 times the size, plus 1, and then take the nearest 2 to the nth power.
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// The if branch is basically the same as the code for initializing the array. Here, we can ignore this code
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2); // 0.75 * n
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY) break;
else if (tab == table) {
// I don't understand what rs really means, but it doesn't matter
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 2. Add 1 to sizeCtl with CAS, and then execute the transfer method
// nextTab is not null at this time
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 1. Set sizeCtl to (RS < < resize_stamp_shift) + 2)
// I don't understand what this value really means? But what you can calculate is that the result is a relatively large negative number
// Call the transfer method, and the nextTab parameter is null
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
The core of this method is the operation of sizecl value. First set it to a negative number, then execute transfer(tab, null), and then add sizecl by 1 and execute transfer(tab, nt) in the next cycle. Then, you may continue to add sizecl by 1 and execute transfer(tab, nt).
Therefore, the possible operation is to execute transfer(tab, null) + multiple transfers (tab, NT). How to end the cycle here needs to read the transfer source code.
Data migration transfer
Migrate the elements of the original tab array to the new nextTab array.
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// Stripe is directly equal to N in single core mode, and (n > > > 3) / ncpu in multi-core mode. The minimum value is 16
// Stripe can be understood as "step size". There are n locations that need to be migrated,
// Divide the n tasks into multiple task packages, and each task package has stripe tasks
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE;
// If nextTab is null, initialize it first
// As we said earlier, the periphery will ensure that the parameter nextTab is null when the first thread initiating migration calls this method
// When the thread participating in the migration calls this method later, nextTab will not be null
if (nextTab == null) {
try {
// Capacity doubled
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
// nextTable is an attribute in ConcurrentHashMap
nextTable = nextTab;
// transferIndex is also an attribute of ConcurrentHashMap, which is used to control the location of migration
transferIndex = n;
}
int nextn = nextTab.length;
// ForwardingNode is translated as the Node being migrated
// This construction method will generate a Node. The key, value and next are null. The key is that the hash is MOVED
// We will see later that after the node at position i in the original array completes the migration,
// The ForwardingNode will be set at location i to tell other threads that the location has been processed
// So it's actually a sign.
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance means that you are ready to move to the next location after completing the migration of one location
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
// The following for loop is the most difficult to understand in the front. To understand them, you should first understand the back, and then look back
// i is the location index, and bound is the boundary. Note that it is from back to front
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// The following while is really hard to understand
// If advance is true, it means that the next location can be migrated
// Simply understand the ending: i points to transferIndex, and bound points to transferIndex stripe
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing) advance = false;
// Assign the transferIndex value to nextIndex
// Here, once the transferIndex is less than or equal to 0, it means that there are corresponding threads to process all positions of the original array
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
// Look at the code in parentheses. nextBound is the boundary of this migration task. Note that it is from back to front
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
// All migration operations have been completed
nextTable = null;
// Assign the new nextTab to the table attribute to complete the migration
table = nextTab;
// Recalculate sizeCtl: n is the length of the original array, so the value obtained by sizeCtl will be 0.75 times the length of the new array
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// As we said before, sizeCtl will be set to (RS < < resize_stamp_shift) + 2 before migration
// Then, for each thread participating in the migration, sizeCtl will be increased by 1,
// Here, the CAS operation is used to subtract 1 from sizeCtl, which means that your task has been completed
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// The task ends and the method exits
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return;
// Here, the description (SC - 2) = = resizestamp (n) < < resize_ STAMP_ SHIFT,
// In other words, after all the migration tasks are completed, it will enter the if(finishing) {} branch above
finishing = advance = true;
i = n; // recheck before commit
}
}
// If the location i is empty and there are no nodes, the "ForwardingNode" empty node just initialized is placed“
else if ((f = tabAt(tab, i)) == null) advance = casTabAt(tab, i, null, fwd);
// At this location is a ForwardingNode, which means that the location has been migrated
else if ((fh = f.hash) == MOVED) advance = true; // already processed
else {
// Lock the node at this position of the array and start processing the migration at this position of the array
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// If the hash of the head Node is greater than 0, it indicates that it is the Node node of the linked list
if (fh >= 0) {
// The following is similar to the concurrent HashMap migration in Java 7,
// You need to divide the linked list into two,
// Find the lastRun in the original linked list, and then migrate the lastRun and its subsequent nodes together
// Nodes before lastRun need to be cloned and then divided into two linked lists
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0) ln = new Node<K,V>(ph, pk, pv, ln);
else hn = new Node<K,V>(ph, pk, pv, hn);
}
// One of the linked lists is placed in the position i of the new array
setTabAt(nextTab, i, ln);
// Another linked list is placed in the position i+n of the new array
setTabAt(nextTab, i + n, hn);
// Set the position of the original array to fwd, which means that the position has been processed,
// Once other threads see that the hash value of this location is MOVED, they will not migrate
setTabAt(tab, i, fwd);
// If advance is set to true, it means that the location has been migrated
advance = true;
}
else if (f instanceof TreeBin) {
// Migration of red and black trees
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null) lo = p;
else loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null) hi = p;
else hiTail.next = p;
hiTail = p;
++hc;
}
}
// If the number of nodes is less than 8 after one is divided into two, the red black tree will be converted back to the linked list
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// Place ln in position i of the new array
setTabAt(nextTab, i, ln);
// Place hn at position i+n of the new array
setTabAt(nextTab, i + n, hn);
// Set the position of the original array to fwd, which means that the position has been processed,
// Once other threads see that the hash value of this location is MOVED, they will not migrate
setTabAt(tab, i, fwd);
// If advance is set to true, it means that the location has been migrated
advance = true;
}
}
}
}
}
}
get procedure
1) Calculate the hash value.
2) Find the corresponding position of the array according to the hash value: (n - 1) & H.
3) Search according to the properties of the node at this location.
- If the location is null, you can return null directly.
- If the node at this location is exactly what we need, return the value of this node.
- If the hash value of the node at this location is less than 0, it indicates that it is expanding capacity, or it is a red black tree. We will introduce the find method later.
- If the above three items are not satisfied, it is the linked list, which can be traversed and compared.
4, Summary
HashTable: the synchronized keyword is used to lock put and other operations
ConcurrentHashMap JDK1.7: implemented using segment lock mechanism
ConcurrentHashMap JDK1.8: it is implemented using array + linked list + red black tree data structure and CAS atomic operation
Shoulders of Giants:
https://www.pdai.tech/md/java/thread/java-thread-x-juc-collection-ConcurrentHashMap.html#juc%E9%9B%86%E5%90%88-concurrenthashmap%E8%AF%A6%E8%A7%A3
https://snailclimb.gitee.io/javaguide/#/docs/java/collection/ConcurrentHashMap%E6%BA%90%E7%A0%81+%E5%BA%95%E5%B1%82%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%88%86%E6%9E%90?id=_1-concurrenthashmap-17