2021SC@SDUSC
The book continues from the above. According to the division of labor, I am responsible for analyzing the source code in the parser package. Therefore, I will first give a basic overview of the parser package, and then analyze the source code.
1, Basic overview of parser package
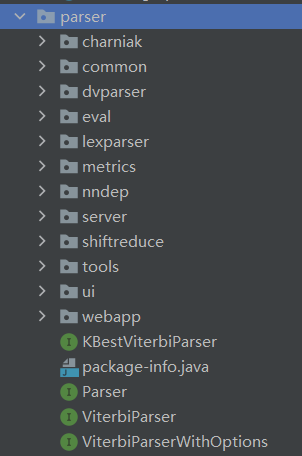
As shown in the figure, there are many sub packages in the parser package, including charniak, common, dvparser, eval, lexparser, metrics, nndep, server, shiftreduce, tools, ui and webapp. It is not difficult to see from the name that the code in the parser package supports the syntax parsing function of the whole program. The sub packages with names such as dvparser and lexparser are the function module packages that store the specific resolution function branches. For other sub package names such as common, UI, Eval, webapp, tools and server, it is not difficult to understand that the functions of storing source code are regular source code, user interface source code, evaluation source code, web program source code, tool source code and server-side source code. As for the last remaining sub package names, most of them are abbreviations. Further analysis is needed to know the significance and function of the source code.
2, Basic overview of common sub package
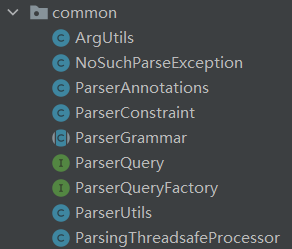
First, let's look at the so-called regular source code -- that is, the source code in the common sub package. When you open the common sub package, you can see that there are 9 source files written in java language. It is not difficult to see from the source file icon of IDEA that ParserGrammar is an abstract class, ParserQuery is an interface, ParserQueryFactory is obviously an abstract factory of ParserQuery, and the rest are implementation classes. According to the top-down principle, I will first analyze the abstract class ParserGrammar (ParserQuery and its abstract classes are included), and then analyze the remaining implementation classes.
3, ParserGrammar abstract class source code analysis
According to the class declaration of the ParserGrammar abstract class, the ParserGrammar abstract class implements two interfaces. The first interface implemented is function < list <? Extensions hasword >, tree >, and the second is ParserQueryFactory.
public abstract class ParserGrammar implements Function<List<? extends HasWord>, Tree>, ParserQueryFactory {The syntax of the first interface seems a little difficult to understand. Obviously, it is a syntax sugar. Let's explain it here.
List<?>: It is a generic type. Before assignment, it means that any type of set assignment can be accepted, but elements cannot be added to it after assignment, but can be remove d and clear, not immutable. List<?> Generally, it receives an external collection as a parameter or returns a collection of specific element types, also known as a wildcard collection.
Therefore, we can know that the first interface implemented is a function interface, which will receive a list <? The objects of the extends HasWord > class are used as input, that is, a list of objects whose elements are all inherited from a subclass of the HasWord class is input, and then an object of the Tree class is output. Then the ParserGrammar abstract class that implements this function interface will naturally implement this method.
The second interface is the ParserQueryFactory interface. As mentioned earlier, this interface is an abstract factory of ParserQuery. Therefore, the ParserGrammar abstract class implementing this interface will naturally produce such a ParserQuery object, which can be seen later.
Next, the concrete definition of the abstract class is analyzed. The first is the two member variables logger and parserQuery. By now, we can understand how the second interface is implemented. Through this interface object as a public abstract variable, this abstract variable can specifically implement this interface object when parsing the ParserGrammar abstract class in the future. The static variable logger is the object of RedwoodChannels class, which I don't know yet and needs to be analyzed and verified in the future.
private static Redwood.RedwoodChannels logger = Redwood.channels(ParserGrammar.class); public abstract ParserQuery parserQuery();
There are too many member methods of this abstract class. Let's look at them one by one. Among many member functions, the most important is the tokenize method, which processes the input string sentence through the getTokenizer() method of TokenizerFactory, performs lexical analysis on it, divides it into specific words, and returns it in the token list.
public List<? extends HasWord> tokenize(String sentence) {
TokenizerFactory<? extends HasWord> tf = treebankLanguagePack().getTokenizerFactory();
Tokenizer<? extends HasWord> tokenizer = tf.getTokenizer(new StringReader(sentence));
List<? extends HasWord> tokens = tokenizer.tokenize();
return tokens;
}With the tokenize method, the parse method processes the generated word segmentation list on this basis to turn it into a tree structure.
public Tree parse(String sentence) {
List<? extends HasWord> tokens = tokenize(sentence);
if (getOp().testOptions.preTag) {
Function<List<? extends HasWord>, List<TaggedWord>> tagger = loadTagger();
tokens = tagger.apply(tokens);
}
return parse(tokens);
}The apply method also processes the word list through the parse method.
public Tree apply(List<? extends HasWord> words) {
return parse(words);
}At this time, two temporary variables are defined in the class, namely function interface object tagger and string taggerPath. With these two temporary variables, the next method definition has its meaning.
private transient Function<List<? extends HasWord>, List<TaggedWord>> tagger; private transient String taggerPath;
Based on the above two temporary variables, we can analyze the following specific function methods, loadTagger and lemmatize. Because you don't know about the Options class, skip the analysis of loadTagger temporarily. For the overloaded function lemmatize, you can know from its comments that this is an analysis method for classifying and analyzing parts of speech. The input string is non English analysis, and the input list is English analysis.
public Function<List<? extends HasWord>, List<TaggedWord>> loadTagger() {
Options op = getOp();
if (op.testOptions.preTag) {
synchronized(this) { // TODO: rather coarse synchronization
if (!op.testOptions.taggerSerializedFile.equals(taggerPath)) {
taggerPath = op.testOptions.taggerSerializedFile;
tagger = ReflectionLoading.loadByReflection("edu.stanford.nlp.tagger.maxent.MaxentTagger", taggerPath);
}
return tagger;
}
} else {
return null;
}
}
public List<CoreLabel> lemmatize(String sentence) {
List<? extends HasWord> tokens = tokenize(sentence);
return lemmatize(tokens);
}
/**
* Only works on English, as it is hard coded for using the
* Morphology class, which is English-only
*/
public List<CoreLabel> lemmatize(List<? extends HasWord> tokens) {
List<TaggedWord> tagged;
if (getOp().testOptions.preTag) {
Function<List<? extends HasWord>, List<TaggedWord>> tagger = loadTagger();
tagged = tagger.apply(tokens);
} else {
Tree tree = parse(tokens);
tagged = tree.taggedYield();
}
Morphology morpha = new Morphology();
List<CoreLabel> lemmas = Generics.newArrayList();
for (TaggedWord token : tagged) {
CoreLabel label = new CoreLabel();
label.setWord(token.word());
label.setTag(token.tag());
morpha.stem(label);
lemmas.add(label);
}
return lemmas;
}The rest are abstract methods and need to implement class definitions.
public abstract Tree parse(List<? extends HasWord> words); public abstract Tree parseTree(List<? extends HasWord> words); public abstract List<Eval> getExtraEvals(); public abstract List<ParserQueryEval> getParserQueryEvals(); public abstract Options getOp(); public abstract TreebankLangParserParams getTLPParams(); public abstract TreebankLanguagePack treebankLanguagePack(); public abstract String[] defaultCoreNLPFlags(); public abstract void setOptionFlags(String ... flags); public abstract boolean requiresTags();