Sonar scanner engine source code analysis
Title: Sonar scanner engine source code analysis
date: 2021-09-18
author: mamian521#gmail.com
introduce
According to the source code analysis of sonar scanner CLI and sonar scanner API, we know that the source code for performing local scanning is not in these two places, but in another module, sonar scanner engine
Address:[ https://github.com/SonarSource/sonarqube.git](https://github.com/SonarSource/sonarqube.git)
This paper is based on branch-9.0
Initialize Batch
@Override
public Batch createBatch(Map<String, String> properties, final org.sonarsource.scanner.api.internal.batch.LogOutput logOutput) {
EnvironmentInformation env = new EnvironmentInformation(properties.get(SCANNER_APP_KEY), properties.get(SCANNER_APP_VERSION_KEY));
return Batch.builder()
.setEnvironment(env)
.setGlobalProperties(properties)
.setLogOutput((formattedMessage, level) -> logOutput.log(formattedMessage, LogOutput.Level.valueOf(level.name())))
.build();
}
Entry class
org/sonar/batch/bootstrapper/Batch.java
// Entrance method
public synchronized Batch execute() {
return doExecute(this.globalProperties, this.components);
}
public synchronized Batch doExecute(Map<String, String> scannerProperties, List<Object> components) {
configureLogging();
try {
GlobalContainer.create(scannerProperties, components).execute();
} catch (RuntimeException e) {
throw handleException(e);
}
return this;
}
private Batch(Builder builder) {
components = new ArrayList<>();
components.addAll(builder.components);
if (builder.environment != null) {
components.add(builder.environment);
}
if (builder.globalProperties != null) {
globalProperties.putAll(builder.globalProperties);
}
if (builder.isEnableLoggingConfiguration()) {
loggingConfig = new LoggingConfiguration(builder.environment).setProperties(globalProperties);
if (builder.logOutput != null) {
loggingConfig.setLogOutput(builder.logOutput);
}
}
}
According to the source code, you can see
During Batch initialization, there are two main parameters: one is to read configuration information, properties, and the other is component. Here, EnvironmentInformation, the class of environment information, is passed in, and the version of scanner is mainly saved.
Then start executing the execute method and add a synchronization lock.
Then execute the create and execute methods of GlobalContainer. As the name suggests, one is the method of instantiating a class, and the other is the method of execution.
public static GlobalContainer create(Map<String, String> scannerProperties, List<?> extensions) {
GlobalContainer container = new GlobalContainer(scannerProperties);
container.add(extensions);
return container;
}
............
@Override
public ComponentContainer add(Object... objects) {
for (Object object : objects) {
if (object instanceof ComponentAdapter) {
addPicoAdapter((ComponentAdapter) object);
} else if (object instanceof Iterable) {
// Recursion, repeated injection
add(Iterables.toArray((Iterable) object, Object.class));
} else {
addSingleton(object);
}
}
return this;
}
........
public ComponentContainer addComponent(Object component, boolean singleton) {
Object key = componentKeys.of(component);
if (component instanceof ComponentAdapter) {
pico.addAdapter((ComponentAdapter) component);
} else {
try {
pico.as(singleton ? Characteristics.CACHE : Characteristics.NO_CACHE).addComponent(key, component);
} catch (Throwable t) {
throw new IllegalStateException("Unable to register component " + getName(component), t);
}
declareExtension("", component);
}
return this;
}
When you execute the add method, you can see some keywords, such as container/singleton. In fact, you can infer that it uses a dependency injection framework, similar to Spring, which we often use now. If it is an iteratable object, it will enter the recursive call and inject circularly. If it is of other types, such as the EnvironmentInformation we passed in, it will be injected as a singleton object.
The framework used here is picocontainer
Official website: http://picocontainer.com/introduction.html
Introduction: PicoContainer is a very lightweight Ioc container that provides dependency injection and object lifecycle management functions. It is a pure small and beautiful Ioc container. Spring is Ioc +, which provides other functions such as AOP. It is a large and comprehensive framework, not just Ioc container.
It is speculated that the reason for using the framework is that the lightweight or the founder of SonarQubu is familiar with it, so the framework is used. It seems that there is little update and maintenance at present, and there is no replacement action for SonarQube. Let's just look at it as a Spring framework.
Then look at the execute method
public void execute() {
try {
startComponents();
} finally {
// Manually destroy the injected container
stopComponents();
}
}
// Template Pattern
/**
* This method MUST NOT be renamed start() because the container is registered itself in picocontainer. Starting
* a component twice is not authorized.
*/
public ComponentContainer startComponents() {
try {
// Call methods of subclass GlobalContainer/ProjectScanContainer
doBeforeStart();
// Manually start the container
pico.start();
// Call methods of subclass GlobalContainer/ProjectScanContainer
doAfterStart();
return this;
} catch (Exception e) {
throw PicoUtils.propagate(e);
}
}
......
@Override
protected void doBeforeStart() {
GlobalProperties bootstrapProps = new GlobalProperties(bootstrapProperties);
GlobalAnalysisMode globalMode = new GlobalAnalysisMode(bootstrapProps);
// injection
add(bootstrapProps);
add(globalMode);
addBootstrapComponents();
}
// Sequential injection
private void addBootstrapComponents() {
Version apiVersion = MetadataLoader.loadVersion(System2.INSTANCE);
SonarEdition edition = MetadataLoader.loadEdition(System2.INSTANCE);
DefaultAnalysisWarnings analysisWarnings = new DefaultAnalysisWarnings(System2.INSTANCE);
LOG.debug("{} {}", edition.getLabel(), apiVersion);
add(
// plugins
ScannerPluginRepository.class,
PluginClassLoader.class,
PluginClassloaderFactory.class,
ScannerPluginJarExploder.class,
ExtensionInstaller.class,
new SonarQubeVersion(apiVersion),
new GlobalServerSettingsProvider(),
new GlobalConfigurationProvider(),
new ScannerWsClientProvider(),
DefaultServer.class,
new GlobalTempFolderProvider(),
DefaultHttpDownloader.class,
analysisWarnings,
UriReader.class,
PluginFiles.class,
System2.INSTANCE,
Clock.systemDefaultZone(),
new MetricsRepositoryProvider(),
UuidFactoryImpl.INSTANCE);
addIfMissing(SonarRuntimeImpl.forSonarQube(apiVersion, SonarQubeSide.SCANNER, edition), SonarRuntime.class);
addIfMissing(ScannerPluginInstaller.class, PluginInstaller.class);
add(CoreExtensionRepositoryImpl.class, CoreExtensionsLoader.class, ScannerCoreExtensionsInstaller.class);
addIfMissing(DefaultGlobalSettingsLoader.class, GlobalSettingsLoader.class);
addIfMissing(DefaultNewCodePeriodLoader.class, NewCodePeriodLoader.class);
addIfMissing(DefaultMetricsRepositoryLoader.class, MetricsRepositoryLoader.class);
}
@Override
protected void doAfterStart() {
// Install plug-ins
installPlugins();
// Load using class loader
loadCoreExtensions();
long startTime = System.currentTimeMillis();
String taskKey = StringUtils.defaultIfEmpty(scannerProperties.get(CoreProperties.TASK), CoreProperties.SCAN_TASK);
if (taskKey.equals("views")) {
throw MessageException.of("The task 'views' was removed with SonarQube 7.1. " +
"You can safely remove this call since portfolios and applications are automatically re-calculated.");
} else if (!taskKey.equals(CoreProperties.SCAN_TASK)) {
throw MessageException.of("Tasks support was removed in SonarQube 7.6.");
}
String analysisMode = StringUtils.defaultIfEmpty(scannerProperties.get("sonar.analysis.mode"), "publish");
if (!analysisMode.equals("publish")) {
throw MessageException.of("The preview mode, along with the 'sonar.analysis.mode' parameter, is no more supported. You should stop using this parameter.");
}
new ProjectScanContainer(this).execute();
LOG.info("Analysis total time: {}", formatTime(System.currentTimeMillis() - startTime));
}
Sort it out. Here is to inject the class to be started, and then manually call the started method.
Finally, the real execution method is new ProjectScanContainer(this).execute();
This class ProjectScanContainer and GlobalContainer also inherit from ComponentContainer, so they override doBeforeStart doAfterStart in the execute method of the parent class. Here, it is applied to a design pattern, that is, the template design pattern. The parent class implements an execute method, but the subclass cannot be overwritten. The subclass of other methods in the method can be overwritten. This is the template design pattern
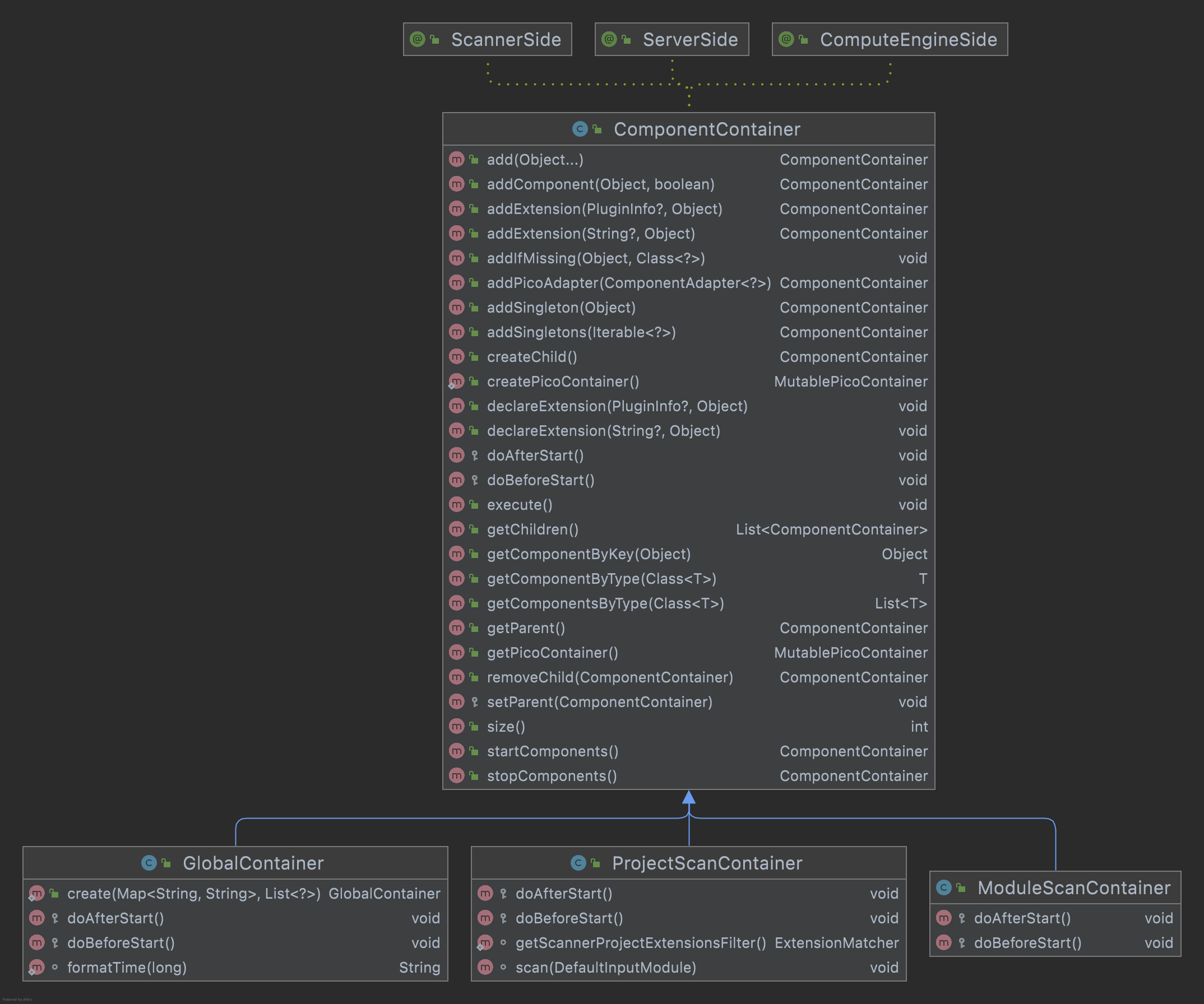
We mainly look at the class ProjectScanContainer, which is the class that performs scanning. You can see these methods
Let's review these methods of the parent class
// ComponentContaienr
public ComponentContainer startComponents() {
try {
// Call methods of subclass GlobalContainer/ProjectScanContainer
doBeforeStart();
// Manually start the container
pico.start();
// Call methods of subclass GlobalContainer/ProjectScanContainer
doAfterStart();
return this;
} catch (Exception e) {
throw PicoUtils.propagate(e);
}
}
- doBeforeStart()
- pico.start()
- doAfterStart()
So let's look at these methods in this order
// ProjectScanContainer
@Override
protected void doBeforeStart() {
// Load plug-in related classes
addScannerExtensions();
// Important, load scanned components
addScannerComponents();
// Warehouse file lock to detect whether there are the same scans
ProjectLock lock = getComponentByType(ProjectLock.class);
lock.tryLock();
// Initialize working directory
getComponentByType(WorkDirectoriesInitializer.class).execute();
}
private void addScannerExtensions() {
getComponentByType(CoreExtensionsInstaller.class)
.install(this, noExtensionFilter(), extension -> getScannerProjectExtensionsFilter().accept(extension));
getComponentByType(ExtensionInstaller.class)
.install(this, getScannerProjectExtensionsFilter());
}
// Load required components
private void addScannerComponents() {
add(
ScanProperties.class,
ProjectReactorBuilder.class,
WorkDirectoriesInitializer.class,
new MutableProjectReactorProvider(),
ProjectBuildersExecutor.class,
ProjectLock.class,
ResourceTypes.class,
ProjectReactorValidator.class,
ProjectInfo.class,
new RulesProvider(),
new BranchConfigurationProvider(),
new ProjectBranchesProvider(),
new ProjectPullRequestsProvider(),
ProjectRepositoriesSupplier.class,
new ProjectServerSettingsProvider(),
// temp
new AnalysisTempFolderProvider(),
// file system
ModuleIndexer.class,
InputComponentStore.class,
PathResolver.class,
new InputProjectProvider(),
new InputModuleHierarchyProvider(),
ScannerComponentIdGenerator.class,
new ScmChangedFilesProvider(),
StatusDetection.class,
LanguageDetection.class,
MetadataGenerator.class,
FileMetadata.class,
FileIndexer.class,
ProjectFileIndexer.class,
ProjectExclusionFilters.class,
// rules
new ActiveRulesProvider(),
new QualityProfilesProvider(),
CheckFactory.class,
QProfileVerifier.class,
// issues
DefaultNoSonarFilter.class,
IssueFilters.class,
IssuePublisher.class,
// metrics
DefaultMetricFinder.class,
// lang
Languages.class,
DefaultLanguagesRepository.class,
// issue exclusions
IssueInclusionPatternInitializer.class,
IssueExclusionPatternInitializer.class,
IssueExclusionsLoader.class,
EnforceIssuesFilter.class,
IgnoreIssuesFilter.class,
// context
ContextPropertiesCache.class,
ContextPropertiesPublisher.class,
SensorStrategy.class,
MutableProjectSettings.class,
ScannerProperties.class,
new ProjectConfigurationProvider(),
ProjectCoverageAndDuplicationExclusions.class,
// Report
ForkDateSupplier.class,
ScannerMetrics.class,
ReportPublisher.class,
AnalysisContextReportPublisher.class,
MetadataPublisher.class,
ActiveRulesPublisher.class,
AnalysisWarningsPublisher.class,
ComponentsPublisher.class,
TestExecutionPublisher.class,
SourcePublisher.class,
ChangedLinesPublisher.class,
CeTaskReportDataHolder.class,
// QualityGate check
QualityGateCheck.class,
// Cpd
CpdExecutor.class,
CpdSettings.class,
SonarCpdBlockIndex.class,
// PostJobs
PostJobsExecutor.class,
PostJobOptimizer.class,
DefaultPostJobContext.class,
PostJobExtensionDictionnary.class,
// SCM
ScmConfiguration.class,
ScmPublisher.class,
ScmRevisionImpl.class,
// Sensors
DefaultSensorStorage.class,
DefaultFileLinesContextFactory.class,
ProjectSensorContext.class,
ProjectSensorOptimizer.class,
ProjectSensorsExecutor.class,
ProjectSensorExtensionDictionnary.class,
// Filesystem
DefaultProjectFileSystem.class,
// CI
new CiConfigurationProvider(),
AppVeyor.class,
AwsCodeBuild.class,
AzureDevops.class,
Bamboo.class,
BitbucketPipelines.class,
Bitrise.class,
Buildkite.class,
CircleCi.class,
CirrusCi.class,
DroneCi.class,
GithubActions.class,
GitlabCi.class,
Jenkins.class,
SemaphoreCi.class,
TravisCi.class,
AnalysisObservers.class);
add(GitScmSupport.getObjects());
add(SvnScmSupport.getObjects());
addIfMissing(DefaultProjectSettingsLoader.class, ProjectSettingsLoader.class);
addIfMissing(DefaultRulesLoader.class, RulesLoader.class);
addIfMissing(DefaultActiveRulesLoader.class, ActiveRulesLoader.class);
addIfMissing(DefaultQualityProfileLoader.class, QualityProfileLoader.class);
addIfMissing(DefaultProjectRepositoriesLoader.class, ProjectRepositoriesLoader.class);
}
private void addScannerExtensions() {
getComponentByType(CoreExtensionsInstaller.class)
.install(this, noExtensionFilter(), extension -> getScannerProjectExtensionsFilter().accept(extension));
getComponentByType(ExtensionInstaller.class)
.install(this, getScannerProjectExtensionsFilter());
}
......
@Override
protected void doAfterStart() {
GlobalAnalysisMode analysisMode = getComponentByType(GlobalAnalysisMode.class);
InputModuleHierarchy tree = getComponentByType(InputModuleHierarchy.class);
ScanProperties properties = getComponentByType(ScanProperties.class);
properties.validate();
properties.get("sonar.branch").ifPresent(deprecatedBranch -> {
throw MessageException.of("The 'sonar.branch' parameter is no longer supported. You should stop using it. " +
"Branch analysis is available in Developer Edition and above. See https://redirect.sonarsource.com/editions/developer.html for more information.");
});
BranchConfiguration branchConfig = getComponentByType(BranchConfiguration.class);
if (branchConfig.branchType() == BranchType.PULL_REQUEST) {
LOG.info("Pull request {} for merge into {} from {}", branchConfig.pullRequestKey(), pullRequestBaseToDisplayName(branchConfig.targetBranchName()),
branchConfig.branchName());
} else if (branchConfig.branchName() != null) {
LOG.info("Branch name: {}", branchConfig.branchName());
}
// File index
getComponentByType(ProjectFileIndexer.class).index();
// Log detected languages and their profiles after FS is indexed and languages detected
getComponentByType(QProfileVerifier.class).execute();
// Check the module and execute the ModuleContainer
scanRecursively(tree, tree.root());
LOG.info("------------- Run sensors on project");
// scanning
getComponentByType(ProjectSensorsExecutor.class).execute();
// Code submission information git blank
getComponentByType(ScmPublisher.class).publish();
// Code repetition rate
getComponentByType(CpdExecutor.class).execute();
// Generate report, zip compress, upload
getComponentByType(ReportPublisher.class).execute();
// Do you want to wait for the quality valve, internal interface rotation training, and wait for the end of background tasks
if (properties.shouldWaitForQualityGate()) {
LOG.info("------------- Check Quality Gate status");
getComponentByType(QualityGateCheck.class).await();
}
getComponentByType(PostJobsExecutor.class).execute();
if (analysisMode.isMediumTest()) {
// After the test, notify that the scanning is completed and the observer designs the mode
getComponentByType(AnalysisObservers.class).notifyEndOfScanTask();
}
}
This should be a very important process. You can see that doBeforeStart mainly loads plugins first. These plugins are plug-ins of previously downloaded jar packages. According to the source code, they are mainly classes with ScannerSide annotation.
The second step is to load and inject all the above components in the addScannerComponents method
Step 3: execute the pico.start() method. Here, Pico is the dependency injection tool mentioned earlier. After the above classes are injected, some classes inherit from the Startable interface. After calling pico.start(), the start() method of these components will also be triggered.
The fourth step is to execute the doAfterStart method, in which the execute method of each component in the scan is executed.
Let's focus on some classes in doAfterStart.
Let me list a few
- ProjectLock
- ProjectFileIndexer
- ModuleScanContainer
- ProjectSensorsExecutor
- ScmPublisher
- ExtensionInstaller
- CpdExecutor
- ReportPublisher
- PostJobsExecutor
Let's look at them one by one.
ProjectLock
First look at the source code
public class DirectoryLock {
private static final Logger LOGGER = LoggerFactory.getLogger(DirectoryLock.class);
public static final String LOCK_FILE_NAME = ".sonar_lock";
private final Path lockFilePath;
private RandomAccessFile lockRandomAccessFile;
private FileChannel lockChannel;
private FileLock lockFile;
public DirectoryLock(Path directory) {
this.lockFilePath = directory.resolve(LOCK_FILE_NAME).toAbsolutePath();
}
public boolean tryLock() {
try {
lockRandomAccessFile = new RandomAccessFile(lockFilePath.toFile(), "rw");
lockChannel = lockRandomAccessFile.getChannel();
lockFile = lockChannel.tryLock(0, 1024, false);
return lockFile != null;
} catch (IOException e) {
throw new IllegalStateException("Failed to create lock in " + lockFilePath.toString(), e);
}
}
Its general meaning is to create a. Sonar in the working directory of sonar in the project_ Lock file is used to detect whether the current project is being scanned. Note that the class used is FileChannel rather than ordinary Files. This is an application of Java NIO. For details, please refer to this article. https://www.baeldung.com/java-lock-files
lockFile = lockChannel.tryLock(0, 1024, false);
At that time, a 1024 byte file will be created, empty content, and a file will be used as an exclusive lock.
The main purpose of this is to ensure that when multiple sonar scanners are executed at the same time, the information of multiple processes cannot be seen from each other. This lock is used to ensure that there is only one scanning process in one warehouse at the same time.
ProjectFileIndexer
In SonarQube, you can set the scan file range, excluded file range, test file range, test file exclusion range, gitignore, unit test and duplicate file exclusion range. Therefore, this class is used to index files to see which files need to be scanned and which are within the test range.
The indexModulesRecursively method is mainly called internally
public void index() {
progressReport = new ProgressReport("Report about progress of file indexation", TimeUnit.SECONDS.toMillis(10));
progressReport.start("Indexing files...");
LOG.info("Project configuration:");
projectExclusionFilters.log(" ");
projectCoverageAndDuplicationExclusions.log(" ");
ExclusionCounter exclusionCounter = new ExclusionCounter();
if (useScmExclusion) {
ignoreCommand.init(inputModuleHierarchy.root().getBaseDir().toAbsolutePath());
indexModulesRecursively(inputModuleHierarchy.root(), exclusionCounter);
ignoreCommand.clean();
} else {
indexModulesRecursively(inputModuleHierarchy.root(), exclusionCounter);
}
int totalIndexed = componentStore.inputFiles().size();
progressReport.stop(totalIndexed + " " + pluralizeFiles(totalIndexed) + " indexed");
int excludedFileByPatternCount = exclusionCounter.getByPatternsCount();
if (projectExclusionFilters.hasPattern() || excludedFileByPatternCount > 0) {
LOG.info("{} {} ignored because of inclusion/exclusion patterns", excludedFileByPatternCount, pluralizeFiles(excludedFileByPatternCount));
}
int excludedFileByScmCount = exclusionCounter.getByScmCount();
if (useScmExclusion) {
LOG.info("{} {} ignored because of scm ignore settings", excludedFileByScmCount, pluralizeFiles(excludedFileByScmCount));
}
}
private void indexModulesRecursively(DefaultInputModule module, ExclusionCounter exclusionCounter) {
inputModuleHierarchy.children(module).stream().sorted(Comparator.comparing(DefaultInputModule::key)).forEach(m -> indexModulesRecursively(m, exclusionCounter));
index(module, exclusionCounter);
}
private void index(DefaultInputModule module, ExclusionCounter exclusionCounter) {
// Emulate creation of module level settings
ModuleConfiguration moduleConfig = new ModuleConfigurationProvider().provide(globalConfig, module, globalServerSettings, projectServerSettings);
ModuleExclusionFilters moduleExclusionFilters = new ModuleExclusionFilters(moduleConfig);
ModuleCoverageAndDuplicationExclusions moduleCoverageAndDuplicationExclusions = new ModuleCoverageAndDuplicationExclusions(moduleConfig);
if (componentStore.allModules().size() > 1) {
LOG.info("Indexing files of module '{}'", module.getName());
LOG.info(" Base dir: {}", module.getBaseDir().toAbsolutePath());
module.getSourceDirsOrFiles().ifPresent(srcs -> logPaths(" Source paths: ", module.getBaseDir(), srcs));
module.getTestDirsOrFiles().ifPresent(tests -> logPaths(" Test paths: ", module.getBaseDir(), tests));
moduleExclusionFilters.log(" ");
moduleCoverageAndDuplicationExclusions.log(" ");
}
boolean hasChildModules = !module.definition().getSubProjects().isEmpty();
boolean hasTests = module.getTestDirsOrFiles().isPresent();
// Default to index basedir when no sources provided
List<Path> mainSourceDirsOrFiles = module.getSourceDirsOrFiles()
.orElseGet(() -> hasChildModules || hasTests ? emptyList() : singletonList(module.getBaseDir().toAbsolutePath()));
indexFiles(module, moduleExclusionFilters, moduleCoverageAndDuplicationExclusions, mainSourceDirsOrFiles, Type.MAIN, exclusionCounter);
module.getTestDirsOrFiles().ifPresent(tests -> indexFiles(module, moduleExclusionFilters, moduleCoverageAndDuplicationExclusions, tests, Type.TEST, exclusionCounter));
}
private void indexFiles(DefaultInputModule module, ModuleExclusionFilters moduleExclusionFilters,
ModuleCoverageAndDuplicationExclusions moduleCoverageAndDuplicationExclusions, List<Path> sources, Type type, ExclusionCounter exclusionCounter) {
try {
for (Path dirOrFile : sources) {
if (dirOrFile.toFile().isDirectory()) {
indexDirectory(module, moduleExclusionFilters, moduleCoverageAndDuplicationExclusions, dirOrFile, type, exclusionCounter);
} else {
fileIndexer.indexFile(module, moduleExclusionFilters, moduleCoverageAndDuplicationExclusions, dirOrFile, type, progressReport, exclusionCounter,
ignoreCommand);
}
}
} catch (IOException e) {
throw new IllegalStateException("Failed to index files", e);
}
}
......
// FileIndexer
void indexFile(DefaultInputModule module, ModuleExclusionFilters moduleExclusionFilters, ModuleCoverageAndDuplicationExclusions moduleCoverageAndDuplicationExclusions,
Path sourceFile, Type type, ProgressReport progressReport, ProjectFileIndexer.ExclusionCounter exclusionCounter, @Nullable IgnoreCommand ignoreCommand)
throws IOException {
// get case of real file without resolving link
Path realAbsoluteFile = sourceFile.toRealPath(LinkOption.NOFOLLOW_LINKS).toAbsolutePath().normalize();
Path projectRelativePath = project.getBaseDir().relativize(realAbsoluteFile);
Path moduleRelativePath = module.getBaseDir().relativize(realAbsoluteFile);
boolean included = evaluateInclusionsFilters(moduleExclusionFilters, realAbsoluteFile, projectRelativePath, moduleRelativePath, type);
if (!included) {
exclusionCounter.increaseByPatternsCount();
return;
}
boolean excluded = evaluateExclusionsFilters(moduleExclusionFilters, realAbsoluteFile, projectRelativePath, moduleRelativePath, type);
if (excluded) {
exclusionCounter.increaseByPatternsCount();
return;
}
if (!realAbsoluteFile.startsWith(project.getBaseDir())) {
LOG.warn("File '{}' is ignored. It is not located in project basedir '{}'.", realAbsoluteFile.toAbsolutePath(), project.getBaseDir());
return;
}
if (!realAbsoluteFile.startsWith(module.getBaseDir())) {
LOG.warn("File '{}' is ignored. It is not located in module basedir '{}'.", realAbsoluteFile.toAbsolutePath(), module.getBaseDir());
return;
}
String language = langDetection.language(realAbsoluteFile, projectRelativePath);
if (ignoreCommand != null && ignoreCommand.isIgnored(realAbsoluteFile)) {
LOG.debug("File '{}' is excluded by the scm ignore settings.", realAbsoluteFile);
exclusionCounter.increaseByScmCount();
return;
}
DefaultIndexedFile indexedFile = new DefaultIndexedFile(realAbsoluteFile, project.key(),
projectRelativePath.toString(),
moduleRelativePath.toString(),
type, language, scannerComponentIdGenerator.getAsInt(), sensorStrategy);
DefaultInputFile inputFile = new DefaultInputFile(indexedFile, f -> metadataGenerator.setMetadata(module.key(), f, module.getEncoding()));
if (language != null) {
inputFile.setPublished(true);
}
if (!accept(inputFile)) {
return;
}
checkIfAlreadyIndexed(inputFile);
componentStore.put(module.key(), inputFile);
issueExclusionsLoader.addMulticriteriaPatterns(inputFile);
String langStr = inputFile.language() != null ? format("with language '%s'", inputFile.language()) : "with no language";
LOG.debug("'{}' indexed {}{}", projectRelativePath, type == Type.TEST ? "as test " : "", langStr);
evaluateCoverageExclusions(moduleCoverageAndDuplicationExclusions, inputFile);
evaluateDuplicationExclusions(moduleCoverageAndDuplicationExclusions, inputFile);
if (properties.preloadFileMetadata()) {
inputFile.checkMetadata();
}
int count = componentStore.inputFiles().size();
progressReport.message(count + " " + pluralizeFiles(count) + " indexed... (last one was " + inputFile.getProjectRelativePath() + ")");
}
......
// InputComponentStore
public InputComponentStore put(String moduleKey, InputFile inputFile) {
DefaultInputFile file = (DefaultInputFile) inputFile;
updateNotAnalysedCAndCppFileCount(file);
addToLanguageCache(moduleKey, file);
inputFileByModuleCache.computeIfAbsent(moduleKey, x -> new HashMap<>()).put(file.getModuleRelativePath(), inputFile);
inputModuleKeyByFileCache.put(inputFile, moduleKey);
globalInputFileCache.put(file.getProjectRelativePath(), inputFile);
inputComponents.put(inputFile.key(), inputFile);
filesByNameCache.computeIfAbsent(inputFile.filename(), x -> new LinkedHashSet<>()).add(inputFile);
filesByExtensionCache.computeIfAbsent(FileExtensionPredicate.getExtension(inputFile), x -> new LinkedHashSet<>()).add(inputFile);
return this;
}
As you can see, the last real call is the InputComponentStore#put() method. Take a detailed look at the InputComponentStore class.
private final SortedSet<String> globalLanguagesCache = new TreeSet<>(); private final Map<String, SortedSet<String>> languagesCache = new HashMap<>(); private final Map<String, InputFile> globalInputFileCache = new HashMap<>(); private final Map<String, Map<String, InputFile>> inputFileByModuleCache = new LinkedHashMap<>(); private final Map<InputFile, String> inputModuleKeyByFileCache = new HashMap<>(); private final Map<String, DefaultInputModule> inputModuleCache = new HashMap<>(); private final Map<String, InputComponent> inputComponents = new HashMap<>(); private final Map<String, Set<InputFile>> filesByNameCache = new HashMap<>(); private final Map<String, Set<InputFile>> filesByExtensionCache = new HashMap<>(); private final BranchConfiguration branchConfiguration; private final SonarRuntime sonarRuntime; private final Map<String, Integer> notAnalysedFilesByLanguage = new HashMap<>();
Take another look at DefaultInputFile
public class DefaultInputFile extends DefaultInputComponent implements InputFile {
private static final intDEFAULT_BUFFER_SIZE= 1024 * 4;
private final DefaultIndexedFile indexedFile;
private final String contents;
private final Consumer<DefaultInputFile> metadataGenerator;
// Language detected
private boolean published;
private boolean excludedForCoverage;
private boolean excludedForDuplication;
private boolean ignoreAllIssues;
// Lazy init to save memory
// If / / NOSONAR is included in the code line, it will not be stored
private BitSet noSonarLines;
private Status status;
private Charset charset;
private Metadata metadata;
private Collection<int[]> ignoreIssuesOnlineRanges;
// Lines of code that can be executed
private BitSet executableLines;
According to these, we can know
ProjectFileIndexer —> FileIndexer —> InputComponentStore —> DefaultInputFile
In a file, a lot of information is saved, such as the member variable of DefaultInputFile.
There are two places to see. One is to use BitSet to store executableLines. Here, the line number of lines that can be executed is recorded. set or list is not used during storage, which optimizes the storage space.
InputComponentStore in this class, we can see that the way of putting is basically to put the file in the member variable of this class.
ModuleScanContainer
This ModuleScanContainer also inherits from ComponentContainer. We just regard it as a Module level component scanner. What is the Module level and how to distinguish it. This should refer to the Module module Module in Java. For example, a java project will be designed in multiple modules.
public void execute() {
Collection<ModuleSensorWrapper> moduleSensors = new ArrayList<>();
withModuleStrategy(() -> moduleSensors.addAll(selector.selectSensors(false)));
Collection<ModuleSensorWrapper> deprecatedGlobalSensors = new ArrayList<>();
if (isRoot) {
deprecatedGlobalSensors.addAll(selector.selectSensors(true));
}
printSensors(moduleSensors, deprecatedGlobalSensors);
withModuleStrategy(() -> execute(moduleSensors));
if (isRoot) {
execute(deprecatedGlobalSensors);
}
}
private void execute(Collection<ModuleSensorWrapper> sensors) {
for (ModuleSensorWrapper sensor : sensors) {
String sensorName = getSensorName(sensor);
profiler.startInfo("Sensor " + sensorName);
sensor.analyse();
profiler.stopInfo();
}
}
ProjectSensorsExecutor
public void execute() {
List<ProjectSensorWrapper> sensors = selector.selectSensors();
LOG.debug("Sensors : {}", sensors.stream()
.map(Object::toString)
.collect(Collectors.joining(" -> ")));
for (ProjectSensorWrapper sensor : sensors) {
String sensorName = getSensorName(sensor);
profiler.startInfo("Sensor " + sensorName);
sensor.analyse();
profiler.stopInfo();
}
}
private String getSensorName(ProjectSensorWrapper sensor) {
ClassLoader cl = getSensorClassLoader(sensor);
String pluginKey = pluginRepo.getPluginKey(cl);
if (pluginKey != null) {
return sensor.toString() + " [" + pluginKey + "]";
}
return sensor.toString();
}
private static ClassLoader getSensorClassLoader(ProjectSensorWrapper sensor) {
return sensor.wrappedSensor().getClass().getClassLoader();
}
.....
public List<ProjectSensorWrapper> selectSensors() {
Collection<ProjectSensor> result = sort(getFilteredExtensions(ProjectSensor.class, null));
return result.stream()
.map(s -> new ProjectSensorWrapper(s, sensorContext, sensorOptimizer))
.filter(ProjectSensorWrapper::shouldExecute)
.collect(Collectors.toList());
}
What are the classes that implement the ProjectSensor interface from the dependencies? For example, unit test collection, third-party Issue import, duplicate code analysis, Metric measurement information,
ScmPublisher
Here is to take out the files to be scanned from the files just index ed, and then query the GIT blank submission information for summary.
public void publish() {
if (configuration.isDisabled()) {
LOG.info("SCM Publisher is disabled");
return;
}
ScmProvider provider = configuration.provider();
if (provider == null) {
LOG.info("SCM Publisher No SCM system was detected. You can use the '" + CoreProperties.SCM_PROVIDER_KEY + "' property to explicitly specify it.");
return;
}
List<InputFile> filesToBlame = collectFilesToBlame(writer);
if (!filesToBlame.isEmpty()) {
String key = provider.key();
LOG.info("SCM Publisher SCM provider for this project is: " + key);
DefaultBlameOutput output = new DefaultBlameOutput(writer, analysisWarnings, filesToBlame, client);
try {
provider.blameCommand().blame(new DefaultBlameInput(fs, filesToBlame), output);
} catch (Exception e) {
output.finish(false);
throw e;
}
output.finish(true);
}
}
.......
// JGitBlameCommand
@Override
public void blame(BlameInput input, BlameOutput output) {
File basedir = input.fileSystem().baseDir();
try (Repository repo = JGitUtils.buildRepository(basedir.toPath()); Git git = Git.wrap(repo)) {
File gitBaseDir = repo.getWorkTree();
if (cloneIsInvalid(gitBaseDir)) {
return;
}
Stream<InputFile> stream = StreamSupport.stream(input.filesToBlame().spliterator(), true);
ForkJoinPool forkJoinPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors(), new GitThreadFactory(), null, false);
forkJoinPool.submit(() -> stream.forEach(inputFile -> blame(output, git, gitBaseDir, inputFile)));
try {
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS);
} catch (InterruptedException e) {
LOG.info("Git blame interrupted");
}
}
}
Note that a thread pool will be used to obtain the blade information, ForkJoinPool, which sets the number of all cores of the computer. The main use is jgit.
ExtensionInstaller
public ExtensionInstaller install(ComponentContainer container, ExtensionMatcher matcher) {
// core components
for (Object o : BatchComponents.all()) {
doInstall(container, matcher, null, o);
}
// plugin extensions
for (PluginInfo pluginInfo : pluginRepository.getPluginInfos()) {
Plugin plugin = pluginRepository.getPluginInstance(pluginInfo.getKey());
Plugin.Context context = new PluginContextImpl.Builder()
.setSonarRuntime(sonarRuntime)
.setBootConfiguration(bootConfiguration)
.build();
plugin.define(context);
for (Object extension : context.getExtensions()) {
doInstall(container, matcher, pluginInfo, extension);
}
}
return this;
}
.....
public static Collection<Object> all() {
List<Object> components = new ArrayList<>();
components.add(DefaultResourceTypes.get());
components.addAll(CorePropertyDefinitions.all());
components.add(ZeroCoverageSensor.class);
components.add(JavaCpdBlockIndexerSensor.class);
// Generic coverage
components.add(GenericCoverageSensor.class);
components.addAll(GenericCoverageSensor.properties());
components.add(GenericTestExecutionSensor.class);
components.addAll(GenericTestExecutionSensor.properties());
components.add(TestPlanBuilder.class);
// External issues
components.add(ExternalIssuesImportSensor.class);
components.add(ExternalIssuesImportSensor.properties());
return components;
}
CpdExecutor
// Default timeout, 5 minutes
private static final int TIMEOUT = 5 * 60 * 1000;
static final int MAX_CLONE_GROUP_PER_FILE = 100;
static final int MAX_CLONE_PART_PER_GROUP = 100;
public CpdExecutor(CpdSettings settings, SonarCpdBlockIndex index, ReportPublisher publisher, InputComponentStore inputComponentCache) {
this(settings, index, publisher, inputComponentCache, Executors.newSingleThreadExecutor());
}
public void execute() {
execute(TIMEOUT);
}
void execute(long timeout) {
List<FileBlocks> components = new ArrayList<>(index.noResources());
Iterator<ResourceBlocks> it = index.iterator();
while (it.hasNext()) {
ResourceBlocks resourceBlocks = it.next();
Optional<FileBlocks> fileBlocks = toFileBlocks(resourceBlocks.resourceId(), resourceBlocks.blocks());
if (!fileBlocks.isPresent()) {
continue;
}
components.add(fileBlocks.get());
}
int filesWithoutBlocks = index.noIndexedFiles() - index.noResources();
if (filesWithoutBlocks > 0) {
LOG.info("CPD Executor {} {} had no CPD blocks", filesWithoutBlocks, pluralize(filesWithoutBlocks));
}
total = components.size();
progressReport.start(String.format("CPD Executor Calculating CPD for %d %s", total, pluralize(total)));
try {
for (FileBlocks fileBlocks : components) {
runCpdAnalysis(executorService, fileBlocks.getInputFile(), fileBlocks.getBlocks(), timeout);
count++;
}
progressReport.stopAndLogTotalTime("CPD Executor CPD calculation finished");
} catch (Exception e) {
progressReport.stop("");
throw e;
} finally {
executorService.shutdown();
}
}
void runCpdAnalysis(ExecutorService executorService, DefaultInputFile inputFile, Collection<Block> fileBlocks, long timeout) {
LOG.debug("Detection of duplications for {}", inputFile.absolutePath());
progressReport.message(String.format("%d/%d - current file: %s", count, total, inputFile.absolutePath()));
List<CloneGroup> duplications;
Future<List<CloneGroup>> futureResult = executorService.submit(() -> SuffixTreeCloneDetectionAlgorithm.detect(index, fileBlocks));
try {
duplications = futureResult.get(timeout, TimeUnit.MILLISECONDS);
} catch (TimeoutException e) {
LOG.warn("Timeout during detection of duplications for {}", inputFile.absolutePath());
futureResult.cancel(true);
return;
} catch (Exception e) {
throw new IllegalStateException("Fail during detection of duplication for " + inputFile.absolutePath(), e);
}
List<CloneGroup> filtered;
if (!"java".equalsIgnoreCase(inputFile.language())) {
int minTokens = settings.getMinimumTokens(inputFile.language());
Predicate<CloneGroup> minimumTokensPredicate = DuplicationPredicates.numberOfUnitsNotLessThan(minTokens);
filtered = duplications.stream()
.filter(minimumTokensPredicate)
.collect(Collectors.toList());
} else {
filtered = duplications;
}
saveDuplications(inputFile, filtered);
}
final void saveDuplications(final DefaultInputComponent component, List<CloneGroup> duplications) {
if (duplications.size() > MAX_CLONE_GROUP_PER_FILE) {
LOG.warn("Too many duplication groups on file {}. Keep only the first {} groups.", component, MAX_CLONE_GROUP_PER_FILE);
}
Iterable<ScannerReport.Duplication> reportDuplications = duplications.stream()
.limit(MAX_CLONE_GROUP_PER_FILE)
.map(
new Function<CloneGroup, Duplication>() {
private final ScannerReport.Duplication.Builder dupBuilder = ScannerReport.Duplication.newBuilder();
private final ScannerReport.Duplicate.Builder blockBuilder = ScannerReport.Duplicate.newBuilder();
@Override
public ScannerReport.Duplication apply(CloneGroup input) {
return toReportDuplication(component, dupBuilder, blockBuilder, input);
}
})::iterator;
publisher.getWriter().writeComponentDuplications(component.scannerId(), reportDuplications);
}
private Optional<FileBlocks> toFileBlocks(String componentKey, Collection<Block> fileBlocks) {
DefaultInputFile component = (DefaultInputFile) componentStore.getByKey(componentKey);
if (component == null) {
LOG.error("Resource not found in component store: {}. Skipping CPD computation for it", componentKey);
return Optional.empty();
}
return Optional.of(new FileBlocks(component, fileBlocks));
}
private Duplication toReportDuplication(InputComponent component, Duplication.Builder dupBuilder, Duplicate.Builder blockBuilder, CloneGroup input) {
dupBuilder.clear();
ClonePart originBlock = input.getOriginPart();
blockBuilder.clear();
dupBuilder.setOriginPosition(ScannerReport.TextRange.newBuilder()
.setStartLine(originBlock.getStartLine())
.setEndLine(originBlock.getEndLine())
.build());
int clonePartCount = 0;
for (ClonePart duplicate : input.getCloneParts()) {
if (!duplicate.equals(originBlock)) {
clonePartCount++;
if (clonePartCount > MAX_CLONE_PART_PER_GROUP) {
LOG.warn("Too many duplication references on file " + component + " for block at line " +
originBlock.getStartLine() + ". Keep only the first "
+ MAX_CLONE_PART_PER_GROUP + " references.");
break;
}
blockBuilder.clear();
String componentKey = duplicate.getResourceId();
if (!component.key().equals(componentKey)) {
DefaultInputComponent sameProjectComponent = (DefaultInputComponent) componentStore.getByKey(componentKey);
blockBuilder.setOtherFileRef(sameProjectComponent.scannerId());
}
dupBuilder.addDuplicate(blockBuilder
.setRange(ScannerReport.TextRange.newBuilder()
.setStartLine(duplicate.getStartLine())
.setEndLine(duplicate.getEndLine())
.build())
.build());
}
}
return dupBuilder.build();
}
Future<List<CloneGroup>> futureResult = executorService.submit(() -> SuffixTreeCloneDetectionAlgorithm.detect(index, fileBlocks));
Executors.newSingleThreadExecutor()
It can be seen that a thread pool is used here. Can you increase the scanning speed here? I don't know if this is thread safe.
In addition, for the real implementation of repeated code information, in another module, sonar duplication, we'll see it next time
ReportPublisher
Read the generated scanner report from the scanner report directory, and then compress and upload it.
@Override
public void start() {
reportDir = moduleHierarchy.root().getWorkDir().resolve("scanner-report");
writer = new ScannerReportWriter(reportDir.toFile());
reader = new ScannerReportReader(reportDir.toFile());
contextPublisher.init(writer);
if (!analysisMode.isMediumTest()) {
String publicUrl = server.getPublicRootUrl();
if (HttpUrl.parse(publicUrl) == null) {
throw MessageException.of("Failed to parse public URL set in SonarQube server: " + publicUrl);
}
}
}
public void execute() {
File report = generateReportFile();
if (properties.shouldKeepReport()) {
LOG.info("Analysis report generated in " + reportDir);
}
if (!analysisMode.isMediumTest()) {
String taskId = upload(report);
prepareAndDumpMetadata(taskId);
}
logSuccess();
}
....
private File generateReportFile() {
try {
long startTime = System.currentTimeMillis();
for (ReportPublisherStep publisher : publishers) {
publisher.publish(writer);
}
long stopTime = System.currentTimeMillis();
LOG.info("Analysis report generated in {}ms, dir size={}", stopTime - startTime, humanReadableByteCountSI(FileUtils.sizeOfDirectory(reportDir.toFile())));
startTime = System.currentTimeMillis();
File reportZip = temp.newFile("scanner-report", ".zip");
ZipUtils.zipDir(reportDir.toFile(), reportZip);
stopTime = System.currentTimeMillis();
LOG.info("Analysis report compressed in {}ms, zip size={}", stopTime - startTime, humanReadableByteCountSI(FileUtils.sizeOf(reportZip)));
return reportZip;
} catch (IOException e) {
throw new IllegalStateException("Unable to prepare analysis report", e);
}
}
If sonar.scanner.keeppreport or sonar.verbose is set, the report can be retained, otherwise the report information will be deleted.

There are many kinds of publish here, such as source code, activation rules, change lines, etc. these contents will be written to the variable writer. This variable is the class ScannerReportWriter, which controls and encapsulates the write operation of these information.
We can see that these operations are protobuf operations, that is, finally, SonarScanner encapsulates all the information that needs to be uploaded to the server as protobuf files for transmission.
// ScannerReportWriter
/**
* Metadata is mandatory
*/
public File writeMetadata(ScannerReport.Metadata metadata) {
Protobuf.write(metadata, fileStructure.metadataFile());
return fileStructure.metadataFile();
}
public File writeActiveRules(Iterable<ScannerReport.ActiveRule> activeRules) {
Protobuf.writeStream(activeRules, fileStructure.activeRules(), false);
return fileStructure.metadataFile();
}
public File writeComponent(ScannerReport.Component component) {
File file = fileStructure.fileFor(FileStructure.Domain.COMPONENT, component.getRef());
Protobuf.write(component, file);
return file;
}
public File writeComponentIssues(int componentRef, Iterable<ScannerReport.Issue> issues) {
File file = fileStructure.fileFor(FileStructure.Domain.ISSUES, componentRef);
Protobuf.writeStream(issues, file, false);
return file;
}
Upload Report
It can be seen that the zip compressed package is uploaded through HTTP Protobuf, and then a task id is obtained. The framework used here is OkHttpClient
Part of the code is in the sonar scanner protocol module
/**
* Uploads the report file to server and returns the generated task id
*/
String upload(File report) {
LOG.debug("Upload report");
long startTime = System.currentTimeMillis();
PostRequest.Part filePart = new PostRequest.Part(MediaTypes.ZIP, report);
PostRequest post = new PostRequest("api/ce/submit")
.setMediaType(MediaTypes.PROTOBUF)
.setParam("projectKey", moduleHierarchy.root().key())
.setParam("projectName", moduleHierarchy.root().getOriginalName())
.setPart("report", filePart);
String branchName = branchConfiguration.branchName();
if (branchName != null) {
if (branchConfiguration.branchType() != PULL_REQUEST) {
post.setParam(CHARACTERISTIC, "branch=" + branchName);
post.setParam(CHARACTERISTIC, "branchType=" + branchConfiguration.branchType().name());
} else {
post.setParam(CHARACTERISTIC, "pullRequest=" + branchConfiguration.pullRequestKey());
}
}
WsResponse response;
try {
post.setWriteTimeOutInMs(DEFAULT_WRITE_TIMEOUT);
response = wsClient.call(post).failIfNotSuccessful();
} catch (HttpException e) {
throw MessageException.of(String.format("Failed to upload report - %s", DefaultScannerWsClient.createErrorMessage(e)));
}
try (InputStream protobuf = response.contentStream()) {
return Ce.SubmitResponse.parser().parseFrom(protobuf).getTaskId();
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
long stopTime = System.currentTimeMillis();
LOG.info("Analysis report uploaded in " + (stopTime - startTime) + "ms");
}
}
void prepareAndDumpMetadata(String taskId) {
Map<String, String> metadata = new LinkedHashMap<>();
metadata.put("projectKey", moduleHierarchy.root().key());
metadata.put("serverUrl", server.getPublicRootUrl());
metadata.put("serverVersion", server.getVersion());
properties.branch().ifPresent(branch -> metadata.put("branch", branch));
URL dashboardUrl = buildDashboardUrl(server.getPublicRootUrl(), moduleHierarchy.root().key());
metadata.put("dashboardUrl", dashboardUrl.toExternalForm());
URL taskUrl = HttpUrl.parse(server.getPublicRootUrl()).newBuilder()
.addPathSegment("api").addPathSegment("ce").addPathSegment("task")
.addQueryParameter(ID, taskId)
.build()
.url();
metadata.put("ceTaskId", taskId);
metadata.put("ceTaskUrl", taskUrl.toExternalForm());
ceTaskReportDataHolder.init(taskId, taskUrl.toExternalForm(), dashboardUrl.toExternalForm());
dumpMetadata(metadata);
}
QualityGateCheck
If you don't look at the source code, I absolutely don't know that SonarQube has this function. We can wait for the end of the execution on the Server side.
This class will be executed when the sonar.qualitygate.wait attribute is true
Setting this attribute can be applied to the pipeline. Previously, we couldn't know the end of the scan when executing the Sonar pipeline. We can only do it by callback hook, because the scan is an asynchronous background task. In this way, we can make the pipeline wait in the foreground all the time. Moreover, after reading the document, it is designed in this way. After reading the next version, It is a feature of SonarQube 8.1 and later.
if (properties.shouldWaitForQualityGate()) {
LOG.info("------------- Check Quality Gate status");
getComponentByType(QualityGateCheck.class).await();
}
public void await() {
if (!enabled) {
LOG.debug("Quality Gate check disabled - skipping");
return;
}
if (analysisMode.isMediumTest()) {
throw new IllegalStateException("Quality Gate check not available in medium test mode");
}
LOG.info("Waiting for the analysis report to be processed (max {}s)", properties.qualityGateWaitTimeout());
String taskId = ceTaskReportDataHolder.getCeTaskId();
Ce.Task task = waitForCeTaskToFinish(taskId);
if (!TaskStatus.SUCCESS.equals(task.getStatus())) {
throw MessageException.of(String.format("CE Task finished abnormally with status: %s, you can check details here: %s",
task.getStatus().name(), ceTaskReportDataHolder.getCeTaskUrl()));
}
Status qualityGateStatus = getQualityGateStatus(task.getAnalysisId());
if (Status.OK.equals(qualityGateStatus)) {
LOG.info("QUALITY GATE STATUS: PASSED - View details on " + ceTaskReportDataHolder.getDashboardUrl());
} else {
throw MessageException.of("QUALITY GATE STATUS: FAILED - View details on " + ceTaskReportDataHolder.getDashboardUrl());
}
}
private Ce.Task waitForCeTaskToFinish(String taskId) {
GetRequest getTaskResultReq = new GetRequest("api/ce/task")
.setMediaType(MediaTypes.PROTOBUF)
.setParam("id", taskId);
long currentTime = 0;
while (qualityGateTimeoutInMs > currentTime) {
try {
WsResponse getTaskResultResponse = wsClient.call(getTaskResultReq).failIfNotSuccessful();
Ce.Task task = parseCeTaskResponse(getTaskResultResponse);
if (TASK_TERMINAL_STATUSES.contains(task.getStatus())) {
return task;
}
Thread.sleep(POLLING_INTERVAL_IN_MS);
currentTime += POLLING_INTERVAL_IN_MS;
} catch (HttpException e) {
throw MessageException.of(String.format("Failed to get CE Task status - %s", DefaultScannerWsClient.createErrorMessage(e)));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new IllegalStateException("Quality Gate check has been interrupted", e);
}
}
throw MessageException.of("Quality Gate check timeout exceeded - View details on " + ceTaskReportDataHolder.getDashboardUrl());
}
To sum up, the sonar scanner engine module basically scans the really executed code.
- PicoContainer, a dependency injection framework, is used,
- There are some common design patterns, such as template design pattern and adapter design pattern
- Through the source code, we know that scanner communicates with the server through protobuf
- Finally, the report is compressed into zip format and uploaded to the server
- A parameter sonar.qualitygate.wait that can wait for the server to finish scanning is also found
- Some usage of BitSet, FileChannel#tryLock(), etc
Later, we can look at the design and source code of server module, sonar core module, sonar duplication module and sonar plugin API.
contact us
