Snowflake algorithm
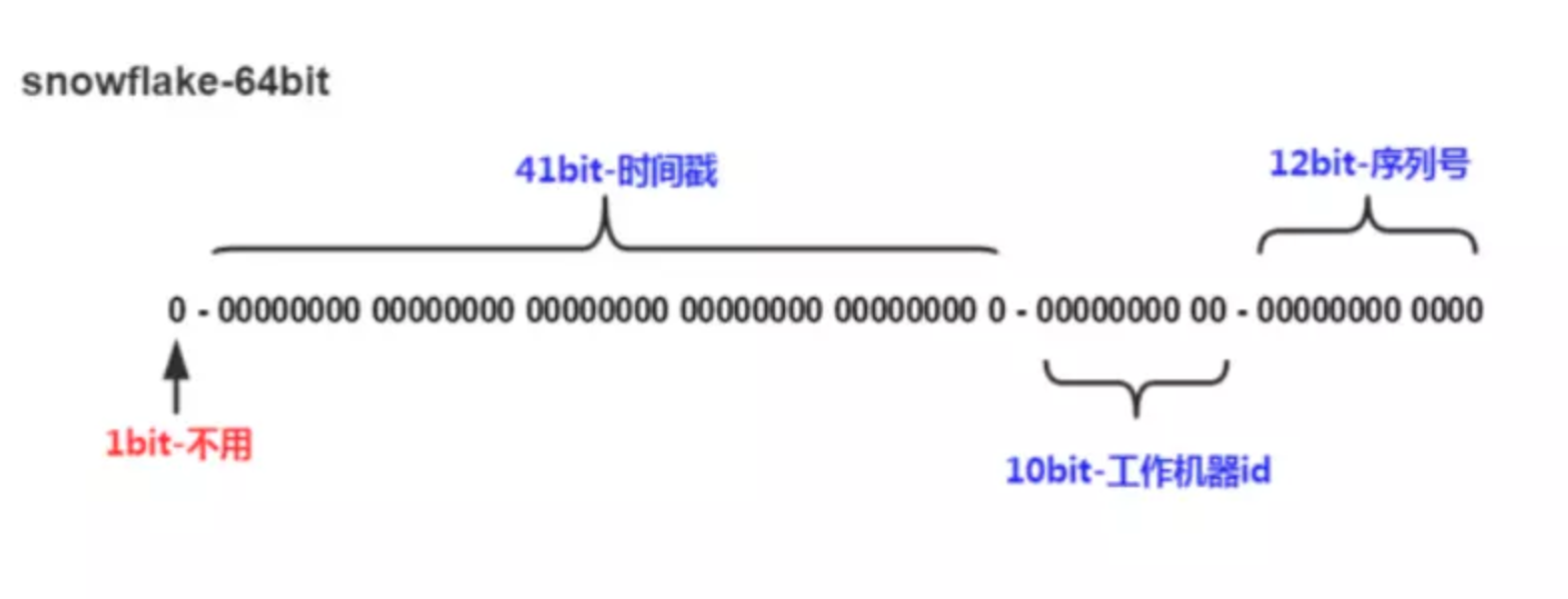
Snowflake is an open source distributed ID generation algorithm based on Twitter. It divides 64-bit bits into several parts in the way of namespace partition, each part represents different meanings. The 64 bit integer in Java is Long type, so the ID generated by SnowFlake algorithm in Java is long to store.
- Bit 1 occupies 1 bit, and its value is always 0, which can be regarded as the symbol bit is not used.
- The first 41 bits are timestamps, and the 41-bit bits represent 2 ^ 41 numbers, each representing milliseconds. Then the time available for snowflake algorithm is (1L < 41)/(1000L360024 * 365)= 69 years.
- The 10-bit bit bit in the middle represents the number of machines, i.e. 2 ^ 10 = 1024 machines, but in general we do not deploy such machines. If we need IDC (Internet Data Center), we can also give IDC 10-bit 5-bit and work machine 5-bit. In this way, 32 IDCs can be represented, each IDC can have 32 machines, specific partition can be defined according to their own needs.
- The last 12-bit bit is a self-increasing sequence, which can represent 2 ^ 12 = 4096 numbers.
Such partitioning is equivalent to generating 4096 orderly, non-repetitive IDs on a machine in a data center in a millisecond. But we certainly have more than one IDC and machine, so the number of ordered IDs that can be generated in milliseconds is doubled.
Snowflake's official Twitter original is written in Scala. Students who have studied Scala can read it. Here's the Java version.
package com.xxx.util; /** * Twitter_Snowflake<br> * SnowFlake The structure is as follows: <br> * 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br> * 1 Bit identifier, because long basic type is symbolic in Java, the highest bit is symbolic bit, positive number is 0, negative number is 1, so id is generally positive, the highest bit is 0 < br > * 41 Bit time cut (in milliseconds), note that the 41-bit time cut is not the time cut for storing the current time, but the difference between the storage time cut (current time cut-start time cut) * The starting time cut here is usually the time when our id generator starts to use, which is specified by our program (as follows: the startTime property of the IdWorker class). The time cut of 41 bits can be used for 69 years, year T = 1 L < 41 / (1000L * 60 * 60 * 24 * 365) = 69 < br > * 10 Bit data machine bits can be deployed at 1024 nodes, including 5-bit data center Id and 5-bit workerId < br>. * 12 Bit sequences, counts in milliseconds, and 12-bit counting sequence numbers support 4096 ID numbers per millisecond (same machine, same time cut) for each node. * It adds up to 64 bits, which is a Long type. <br> * SnowFlake The advantage of SnowFlake is that it can generate about 260,000 IDs per second, because it can be sorted by time, and there is no ID collision (distinguished by data center ID and machine ID) in the whole distributed system. * * @author wsh * @version 1.0 * @since JDK1.8 * @date 2019/7/31 */ public class SnowflakeDistributeId { // ==============================Fields=========================================== /** * Start time cut-off (2015-01-01) */ private final long twepoch = 1420041600000L; /** * Number of digits occupied by machine id */ private final long workerIdBits = 5L; /** * The number of digits occupied by the data identifier id */ private final long datacenterIdBits = 5L; /** * Supported maximum machine id, the result is 31 (this shift algorithm can quickly calculate the maximum decimal number represented by several bits of binary number) */ private final long maxWorkerId = -1L ^ (-1L << workerIdBits); /** * Supported maximum data identifier id, resulting in 31 */ private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); /** * Number of digits in id of sequence */ private final long sequenceBits = 12L; /** * Machine ID moved 12 bits to the left */ private final long workerIdShift = sequenceBits; /** * Data id moved 17 bits to the left (12 + 5) */ private final long datacenterIdShift = sequenceBits + workerIdBits; /** * Time truncation moves 22 bits to the left (5 + 5 + 12) */ private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; /** * The mask of the generated sequence is 4095 (0b111111111111111111111 = 0xfff = 4095) */ private final long sequenceMask = -1L ^ (-1L << sequenceBits); /** * Work Machine ID (0-31) */ private long workerId; /** * Data Center ID (0-31) */ private long datacenterId; /** * Sequences in milliseconds (0-4095) */ private long sequence = 0L; /** * Time cut of last ID generation */ private long lastTimestamp = -1L; //==============================Constructors===================================== /** * Constructor * * @param workerId Work ID (0-31) * @param datacenterId Data Center ID (0-31) */ public SnowflakeDistributeId(long workerId, long datacenterId) { if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId)); } this.workerId = workerId; this.datacenterId = datacenterId; } // ==============================Methods========================================== /** * Get the next ID (this method is thread-safe) * * @return SnowflakeId */ public synchronized long nextId() { long timestamp = timeGen(); //If the current time is less than the time stamp generated by the last ID, the system clock should throw an exception when it falls back. if (timestamp < lastTimestamp) { throw new RuntimeException( String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp)); } //If it is generated at the same time, the sequence in milliseconds is performed. if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; //Sequence overflow in milliseconds if (sequence == 0) { //Blocking to the next millisecond to get a new timestamp timestamp = tilNextMillis(lastTimestamp); } } //Time stamp change, sequence reset in milliseconds else { sequence = 0L; } //Time cut of last ID generation lastTimestamp = timestamp; //Shift and assemble 64-bit ID s together by operation or operation return ((timestamp - twepoch) << timestampLeftShift) // | (datacenterId << datacenterIdShift) // | (workerId << workerIdShift) // | sequence; } /** * Block to the next millisecond until a new timestamp is obtained * * @param lastTimestamp Time cut of last ID generation * @return Current timestamp */ protected long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } /** * Returns the current time in milliseconds * * @return Current time (milliseconds) */ protected long timeGen() { return System.currentTimeMillis(); } }
The code for the test is as follows
public static void main(String[] args) { SnowflakeDistributeId idWorker = new SnowflakeDistributeId(0, 0); for (int i = 0; i < 1000; i++) { long id = idWorker.nextId(); // System.out.println(Long.toBinaryString(id)); System.out.println(id); } }
Snowflake algorithm provides a good design idea. The ID generated by snowflake algorithm is increasing trend, does not depend on third-party systems such as databases, deploys in a service manner, has higher stability, and the performance of ID generation is very high, and it can assign bit bits according to its own business characteristics, which is very flexible.
However, snowflake algorithm strongly depends on machine clock. If the clock is dialed back on the machine, it will result in duplicate calls or the service will be unavailable. If some IDs happen to be generated before the fallback, and the time falls back, the generated IDs are likely to repeat. Officials did not give a solution to this problem, but simply threw out the error processing, which would make the service unavailable during the period before the time was recovered.
Snowflake algorithm - improved version of Snowflake
- Timestamp: Take the number of milliseconds from January 1, 2018 to the present. Assuming that the system runs for at least 10 years, it will take at least 10 years, 365 days, 24 hours, 3600 seconds, 1000 milliseconds = 320*10^ 9. Almost 39 bits are reserved for milliseconds.
- Business Line: 8bit
- Machine: Automatically generated, reserved for 10 bits
- Number in milliseconds: The peak concurrency per second is less than 10W, that is, the average peak concurrency per milliseconds is less than 100, almost 7 bits are reserved for the serial number per milliseconds.
| Timestamp | Business Line | Machine | Serial Number in Milliseconds| | :timestamp | :service | :worker | :sequence | | 39 | 8 | 10 | 7|
The code is as follows:
package com.wsh.common.util; import com.wsh.common.exception.IdsException; import java.net.InetAddress; import java.net.InterfaceAddress; import java.net.NetworkInterface; import java.net.SocketException; import java.util.List; import java.util.Random; /** * Snowflake An improved version of the algorithm * * @author wsh * @version 1.0 * @date 2019/7/31 * @since JDK1.8 */ public class SnowflakeIdGenerator { /** * Number of digits occupied by business line id **/ private final long serviceIdBits = 8L; /** * Maximum data identifier ID supported by line of business identification (this shift algorithm can quickly calculate the maximum decimal number represented by several bits of binary number) */ private final long maxServiceId = -1L ^ (-1L << serviceIdBits); private final long serviceId; /** * Number of digits occupied by machine id **/ private final long workerIdBits = 10L; /** * Maximum machine id supported */ private final long maxWorkerId = -1L ^ (-1L << workerIdBits); private final long workerId; /** * Number of digits in id of sequence **/ private final long sequenceBits = 7L; private final long sequenceMask = -1L ^ (-1L << sequenceBits); /** * Start time stamp (January 1, 2018) **/ private final long twepoch = 1514736000000L; /** * Last timestamp **/ private volatile long lastTimestamp = -1L; /** * Sequence in milliseconds **/ private volatile long sequence = 0L; /** * random number generator **/ private static volatile Random random = new Random(); /** * Left shift number of machine id **/ private final long workerIdShift = sequenceBits; /** * Left shift number of line id **/ private final long serviceIdShift = workerIdBits + sequenceBits; /** * Time stamp left shift number **/ private final long timestampLeftShift = serviceIdBits + workerIdBits + sequenceBits; public SnowflakeIdGenerator(long serviceId) { if ((serviceId > maxServiceId) || (serviceId < 0)) { throw new IllegalArgumentException(String.format("service Id can't be greater than %d or less than 0", maxServiceId)); } workerId = getWorkerId(); if ((workerId > maxWorkerId) || (workerId < 0)) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } this.serviceId = serviceId; } public synchronized long nextId() throws IdsException { long timestamp = System.currentTimeMillis(); if (timestamp < lastTimestamp) { throw new IdsException("Clock moved backwards. Refusing to generate id for " + ( lastTimestamp - timestamp) + " milliseconds."); } //If it is generated at the same time, the sequence in milliseconds is performed. if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; if (sequence == 0) { timestamp = tilNextMillis(lastTimestamp); } } else { //When crossing milliseconds, the serial number always returns to zero, which leads to more IDs with the serial number of 0, resulting in the uneven generation of ID after taking the model, so the random number within 10 is adopted. sequence = random.nextInt(10) & sequenceMask; } //Time Interception of Last ID Generation (Setting Last Time Stamp) lastTimestamp = timestamp; //Shift and assemble 64-bit ID s together by operation or operation return ((timestamp - twepoch) << timestampLeftShift) //time stamp | (serviceId << serviceIdShift) //Business Line | (workerId << workerIdShift) //machine | sequence; //Serial number } /** * Waiting for the next millisecond to arrive, make sure that the number of milliseconds returned is after the parameter lastTimestamp * Keep acquiring time until it is greater than the last time. */ private long tilNextMillis(final long lastTimestamp) { long timestamp = System.currentTimeMillis(); while (timestamp <= lastTimestamp) { timestamp = System.currentTimeMillis(); } return timestamp; } /** * According to the MAC address of the machine, the working process Id can also be obtained by using the machine IP. The last two segments, a total of 10 bit s, can be obtained. * In extreme cases, if the last two segments of the MAC address are the same, the Id of the product will be the same; in extreme cases, if the concurrency is not large, the Id of the product will be repeated just across milliseconds and the random sequence is the same. * * @return * @throws IdsException */ protected long getWorkerId() throws IdsException { try { java.util.Enumeration<NetworkInterface> en = NetworkInterface.getNetworkInterfaces(); while (en.hasMoreElements()) { NetworkInterface iface = en.nextElement(); List<InterfaceAddress> addrs = iface.getInterfaceAddresses(); for (InterfaceAddress addr : addrs) { InetAddress ip = addr.getAddress(); NetworkInterface network = NetworkInterface.getByInetAddress(ip); if (network == null) { continue; } byte[] mac = network.getHardwareAddress(); if (mac == null) { continue; } long id = ((0x000000FF & (long) mac[mac.length - 1]) | (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 11; if (id > maxWorkerId) { return new Random(maxWorkerId).nextInt(); } return id; } } return new Random(maxWorkerId).nextInt(); } catch (SocketException e) { throw new IdsException(e); } } /** * Get the serial number * * @param id * @return */ public static Long getSequence(Long id) { String str = Long.toBinaryString(id); int size = str.length(); String sequenceBinary = str.substring(size - 7, size); return Long.parseLong(sequenceBinary, 2); } /** * Access Machine * * @param id * @return */ public static Long getWorker(Long id) { String str = Long.toBinaryString(id); int size = str.length(); String sequenceBinary = str.substring(size - 7 - 10, size - 7); return Long.parseLong(sequenceBinary, 2); } /** * Acquisition of Business Lines * * @param id * @return */ public static Long getService(Long id) { String str = Long.toBinaryString(id); int size = str.length(); String sequenceBinary = str.substring(size - 7 - 10 - 8, size - 7 - 10); return Long.parseLong(sequenceBinary, 2); } }
Disadvantages:
- In extreme cases, the acquired workerId may be duplicated. See the annotation of getWorkerId, which can be modified to read the configuration file, and then automatically generated if the configuration file cannot be read.
- There is no way to avoid time callbacks, such as moisturizing seconds.
- There is no guarantee that every ID is not wasted