Preface
1. What is cross-validation?
Its basic idea is to group the original data (dataset), one part as a training set to train the model, the other part as a test set to evaluate the model.
2. Why use cross-validation?
Cross-validation is used to assess the predictive performance of models, especially the performance of trained models on new data.Cross-validation itself can only be used for evaluation, but it can compare the impact of different Model s or parameters on structural accuracy.It can then be adjusted based on the data validated, or it can reduce the over-fit to some extent.
Cross Validation in Sklearn is very helpful in choosing the right Model and Model parameters. With its help, we can visually see the impact of different models or parameters on structural accuracy.
1. Basic Validation
from sklearn.datasets import load_iris # iris dataset from sklearn.model_selection import train_test_split # Split Data Module from sklearn.neighbors import KNeighborsClassifier # K-Nearest Neighbor classification algorithm #Loading iris datasets iris = load_iris() X = iris.data y = iris.target #Split data and X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4) #Modeling knn = KNeighborsClassifier() #Training model knn.fit(X_train, y_train) #Print out accuracy print(knn.score(X_test, y_test)) # 0.973684210526
You can see here that we use KNN to classify the training data, then test it with a test set, and then call knn.score directly. The accuracy rate is 0.973684210526 through the basic validation provided by KNN.
2. Model Cross Validation
The main purpose is to use the sklearn.cross_validation module
1. sklearn.model_selection.cross_val_score
File:
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs') Evaluate a score by cross-validation
cross_val_score is used for cross-validation.It has the following parameters:
- estimator: a predictor that implements the fit interface, our model
- X: The data to be fitted
- y: label
- groups: the group label for each group of split data
- cv: Cross-validation generator that determines the strategy for splitting validation.There are four optional values: None (default 3-fold cross validation), integer (specifying the k-value size of StratifiedKFold), object, iteration.
- n_jobs: Number of CPUs used for calculation, default 1, if -1 means all CPUs used
- verbose : The verbosity level.
- fit_params: Parameters passed from the predictor to the fitting method
- pre_dispatch: Number of tasks
Example:
from sklearn.cross_validation import cross_val_score # K-fold cross-validation module #Using the K-fold cross validation module, the parameter cv is 5, which means that the 5-fold StratifiedKFold cross validation is used directly scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy') #Print out 5 times prediction accuracy print(scores) # [ 0.96666667 1. 0.93333333 0.96666667 1. ] #Print out the average prediction accuracy for five times print(scores.mean()) # 0.973333333333
You can see that the average accuracy of cross-validation is 0.97333333
2. class sklearn.model_selection.KFold
In addition, we can construct a K-fold cross validator by ourselves using the KFold class.
File:
class sklearn.model_selection.KFold(n_splits=3, shuffle=False, random_state=None) K-Folds cross-validator Provides train/test indices to split data in train/test sets. Split dataset into k consecutive folds (without shuffling by default). Each fold is then used once as a validation while the k - 1 remaining folds form the training set.
Clearly, the KFold class is used to separate data.You can say that the data set is divided into k-1 training set and 1 test set.It has three parameters:
- n_splits: Represents divided into several subsets of data
- shuffle: Do you want to disrupt the data order? False is the default
- random_state: The seed used to disrupt the data order, not used by default
Example:
# Instantiate a k-fold splitter kfold = model_selection.KFold(n_splits=10, random_state=7) print(kfold) # Validate model results = model_selection.cross_val_score(knn, X_test, y_test, cv=kfold) print(results.mean()) # 0.9
You can see that the accuracy average of 10-fold cross-validation is 0.9
3. Judging by Accuracy
The above validation only gives the performance of the model under certain parameters. If you want to compare the performance of the model horizontally with different parameters, you need to validate and compare them several times.
The KNN classifier is used here as an example. Generally speaking, accuracy is used to judge whether a classification model is good or bad.
from sklearn import model_selection
import matplotlib.pyplot as plt
#Loading iris datasets
iris = load_iris()
X = iris.data
y = iris.target
#Set up test parameters
k_range = range(1, 31)
k_scores = []
#The impact of different parameters on the model is calculated iteratively and the average accuracy after cross-validation is returned.
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k) # Here we test the classification accuracy by changing the K value of KNN
scores = model_selection.cross_val_score(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
#Visualizing data
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
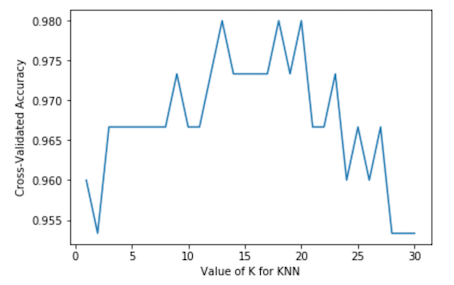
As you can see from the graph, the k value of 12-20 is the best choice.After more than 20 years, the accuracy begins to decline because of the problem of over fitting.
In fact, this is to adjust the classification performance of KNN by adjusting different K values, and then use cross-validation to visually display the accuracy of classification, so that you can find an optimal K value to make KNN perform best.
Of course, the scoring parameter of the model_selection.cross_val_score method can also use mean_squared_error (mean variance).The result is similar to using accuracy.
Reference resources:
[1]. Cross-validation
THE END.