This paper introduces how to use Canal to realize asynchronous and decoupled architecture. Later, I will write an article to analyze the principle and source code of Canal.
Introduction to Canal
Canal is a middleware used to obtain database changes.
Disguise yourself as a MySQL slave database, pull the main database binlog, analyze and process it. The processing results can be sent to MQ to facilitate other services to obtain database change messages, which is very useful. Some typical uses are described below.
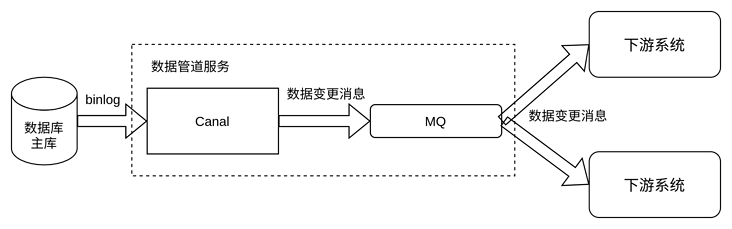
Among them, Canal+MQ as a whole is a data pipeline service from the outside, as shown in the figure below.
Typical use of Canal
Heterogeneous data (e.g. ES, HBase, DB with different routing key s)
Through the adapter provided by Canal, heterogeneous data can be synchronized to ES and HBase without cumbersome data conversion and synchronization. The adapter here is a typical adapter mode, which converts the data into the corresponding format and writes it to the heterogeneous storage system.
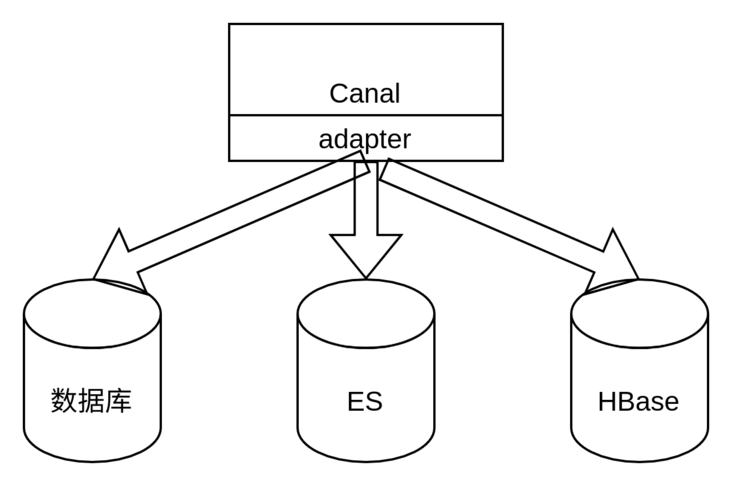
Of course, you can also synchronize the data to the DB, or even build a database with piecemeal routing according to different fields.
For example, when placing an order, the order record is divided into database and table by user id, and then with the help of the Canal data channel, an order record divided into database and table by merchant id is constructed for B-end business (for example, merchants query which orders they receive).

Cache refresh
The conventional method of cache refresh is to update the DB first, then delete the cache, and then delay the deletion (i.e. cache side pattern + delayed double deletion). This multi-step operation may fail and the implementation is relatively complex. With the help of Canal cache refresh, the main service and main process do not need to care about the consistency problems such as cache update, so as to ensure the final consistency.
Important business news such as price change
Downstream services can immediately perceive price changes.
The general practice is to modify the price before sending the message. The difficulty here is to ensure that the message is sent successfully and how to deal with it if it is not sent successfully. With Canal, you don't have to worry about message loss at the business level.
Database migration
- Multi machine room data synchronization
- Dismantling Library
Although you can implement double write logic in the code and then process the historical data, the historical data may also be updated, which requires continuous iterative comparison and update. In short, it is very complex.
Real time reconciliation
The routine practice is that regular tasks run the reconciliation logic, with low timeliness, and inconsistency can not be found in time. With Canal, reconciliation logic can be triggered in real time.
The general process is as follows:
- Receive data change message
- Write hbase as pipeline record
- After a period of window time, trigger the comparison and compare the opposite end data
Canal client demo code analysis
The following example is an example of a client connecting to Canal. It is modified from the official github example. The landlord has made some optimizations and added comments to the key code lines. If Canal sends the data change message to MQ, the writing method is different. The difference is that one is to subscribe to Canal and the other is to subscribe to MQ, but the parsing and processing logic are basically the same.
`
public void process() {
// Number of pieces processed per batch
int batchSize = 1024;
while (running) {
try {
// Connect to Canal service
connector.connect();
// Subscribe to data (such as a table)
connector.subscribe("table_xxx");
while (running) {
// Batch acquisition of data change records
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
// Unexpected situation, exception handling is required
} else {
// Print data change details
printEntry(message.getEntries());
}
if (batchId != -1) {
// ack with batchId: indicates that the batch processing is completed and the consumption progress on the Canal side is updated
connector.ack(batchId);
}
}
} catch (Throwable e) {
logger.error("process error!", e);
try {
Thread.sleep(1000L);
} catch (InterruptedException e1) {
// ignore
}
// Processing failed, rollback progress
connector.rollback();
} finally {
// Disconnect
connector.disconnect();
}
}
}
private void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
long executeTime = entry.getHeader().getExecuteTime();
long delayTime = new Date().getTime() - executeTime;
Date date = new Date(entry.getHeader().getExecuteTime());
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// Only care about the type of data change
if (entry.getEntryType() == EntryType.ROWDATA) {
RowChange rowChange = null;
try {
// Parse data change object
rowChange = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("parse event has an error , data:" + entry.toString(), e);
}
EventType eventType = rowChange.getEventType();
logger.info(row_format,
new Object[] { entry.getHeader().getLogfileName(),
String.valueOf(entry.getHeader().getLogfileOffset()), entry.getHeader().getSchemaName(),
entry.getHeader().getTableName(), eventType,
String.valueOf(entry.getHeader().getExecuteTime()), simpleDateFormat.format(date),
entry.getHeader().getGtid(), String.valueOf(delayTime) });
// Don't care about queries and DDL changes
if (eventType == EventType.QUERY || rowChange.getIsDdl()) {
logger.info("ddl : " + rowChange.getIsDdl() + " , sql ----> " + rowChange.getSql() + SEP);
continue;
}
for (RowData rowData : rowChange.getRowDatasList()) {
if (eventType == EventType.DELETE) {
// When the data change type is delete, the column value before the change is printed
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
// When the data change type is insert, the changed column value is printed
printColumn(rowData.getAfterColumnsList());
} else {
// When the data change type is other (i.e. update), the column values before and after the change are printed
printColumn(rowData.getBeforeColumnsList());
printColumn(rowData.getAfterColumnsList());
}
}
}
}
}
// Print column values
private void printColumn(List<Column> columns) {
for (Column column : columns) {
StringBuilder builder = new StringBuilder();
try {
if (StringUtils.containsIgnoreCase(column.getMysqlType(), "BLOB")
|| StringUtils.containsIgnoreCase(column.getMysqlType(), "BINARY")) {
// get value bytes
builder.append(column.getName() + " : "
+ new String(column.getValue().getBytes("ISO-8859-1"), "UTF-8"));
} else {
builder.append(column.getName() + " : " + column.getValue());
}
} catch (UnsupportedEncodingException e) {
}
builder.append(" type=" + column.getMysqlType());
if (column.getUpdated()) {
builder.append(" update=" + column.getUpdated());
}
builder.append(SEP);
logger.info(builder.toString());
}
}`