First, the string abcdabcdef finds the first character that appears once. What would you do?
Ordinary solution uses pointer traversal to define a pointer P to point to a character a, and then defines a pointer Q to traverse the following pointer. This solution can be found, but the time complexity is O (n^2).
Is there a way to make the time complexity O (n)?
Here we define an array.
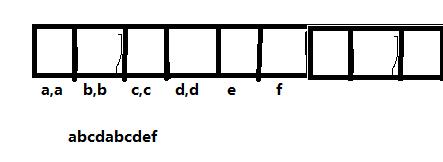
.png)
Use a method to traverse, and then store it in a table (array), define it as K, V type with template, for example, we use multimap to implement (a,2);
This method is called counting sort method. Here we introduce hashtable to solve such problems
Bihash table
1, concept
HashTable-hash table/hash table is a data structure that directly accesses memory storage locations based on key words.
It accesses data by mapping the required data to the location of the table through a function of key values, which is called a hash function and an array of records is called a hash table.
2, build
Next, if we define a large number to store, for example: 1000000-1000099, we can't open 1000099 and data, so we need a function Hash (key) to get the subscript of the array.
Several Methods of Constructing Hash Table
1. Direct addressing method - Hash (Key) = Key or Hash (Key) = A*Key + B, A and B are constant.
2. The method of dividing the residue by a number p whose key value is not greater than the length of the hash table is the hash address. Hash (Key) = Key% p.
3. The Square Method
4. fold method
5. Random Number Method
6. Mathematical Analysis
3. Hash conflict
Question: We open up ten locations, and then find the address of the table (array) according to the Hash(key) generated by the key, but there will be a problem, then the address already has elements, resulting in a "hash conflict";
.png)
Different key values may produce the same value hash address after hash function Hash(Key) processing, which we call hash conflict. Any hash function can not avoid production
Conflict of life.
Closed Hash Conflict Handling Method-Open Location Method
1. Linear detection
2. Secondary detection
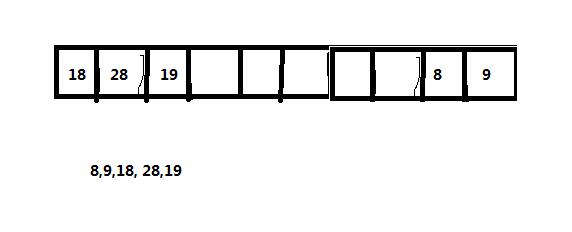
As shown in the figure above, it is a method of processing hash retransmissions, called linear detection. Here we just need to implement this method.
4. If the hash table is full?
Insert hash tables one at a time will always be full, but hash tables are not only for storage, but mainly for search. If the hash table is full, the search efficiency will be low.

.png)
Having said so much, what are we using as the basic elements of this table? vector is the best way to store value, insert number and capacity. But write this not only insert, but also delete, delete words can not guarantee that the continuity of the stored elements, can not find the next element, then we need to use a state to express this. ” Existence, empty, deleted.
5. String processing
Hash tables do not only deal with shaping numbers, but how do we deal with subscripts = Hash(key)?
You must have thought of operator ()! But how do you write this? What should you do with adc, cda?
Here's a great scientific study!
You must have known!
6. Before the source code, there was no secret!
#pragma once
#include <vector>
#include <string>
#include <assert.h>
#include <iostream>
using namespace std;
enum Status
{
EXIST,
DELETE,
EMPTY,
};
template<class K, class V>
struct HashNode
{
K _key;
V _value;
Status _status;
HashNode(const K& key = K(), const V& value = V())
:_key(key)
,_value(value)
,_status(EMPTY)
{}
};
template<class K>
struct __HashFunc
{
size_t operator()(const K& key)
{
return key;
}
};
template<>
struct __HashFunc<string> //For convenience and simplicity, we implement specialization to solve string Problems
{
size_t BKDRHash(const char* str)
{
register size_t hash = 0;
while (*str)
{
hash = hash * 131 + *str;
++str;
}
return hash;
}
size_t operator()(const string& s)
{
return BKDRHash(s.c_str());
}
};
template<class K, class V, class _HashFunc = __HashFunc<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
HashTable(size_t size)
:_size(0)
{
assert(size > 0);
_tables.resize(size);
}
pair<Node*, bool> Insert(const K& key, const V& value) //Closed Hash Method-Open Location Method for Linear Detection
{
CheckCapcity();
size_t index = 0;
index = HashFunc(key);
while(_tables[index]._status == EXIST) //No!= EMPTY because it may be deleted and inserted into DELETE
{
if (_tables[index]._key == key)
{
return make_pair(&_tables[index], true);
}
++index;
if (index == _tables.size())
{
index = 0;
}
}
_tables[index]._key = key;
_tables[index]._value = value;
_tables[index]._status = EXIST;
++_size;
return make_pair(&_tables[index], true);
}
bool Remove(const K& key)
{
Node* ret = Find(key);
if(ret)
{
ret->_status = DELETE;
--_size;
return true;
}
return false;
}
Node* Find(const K& key)
{
size_t index = HashFunc(key);
while (_tables[index]._status != EMPTY)
{
if (_tables[index]._key == key)
{
if(_tables[index]._status != DELETE)
return &_tables[index];
}
++index;
if (index == _tables.size())
index = 0;
}
cout<<"not find"<<endl;
return (Node*)NULL;
}
size_t HashFunc(const K& key)
{
_HashFunc hf;
size_t hash = hf(key);
return hash % _tables.size();
}
void CheckCapcity() //Check alpha factor
{
if (_tables.empty())
{
_tables.resize(7);
return ;
}
if ((_size * 10)/_tables.size() > 7)
{
size_t newsize = _tables.size() * 2;
HashTable<K, V, _HashFunc> temp(newsize);
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i]._status == EXIST)
{
temp.Insert(_tables[i]._key, _tables[i]._value);
}
}
this->Swap(temp);
}
}
void Swap(HashTable<K, V>& temp)
{
_tables.swap(temp._tables);
swap(_size, temp._size);
}
protected:
vector<Node> _tables;
size_t _size;
};
void testhash()
{
HashTable<int, int> h1(7);
h1.Insert(5,0);
h1.Insert(8,0);
h1.Insert(7,0);
h1.Insert(6,0);
h1.Insert(9,0);
h1.Insert(1,0);
h1.Insert(2,0);
h1.Find(5);
h1.Remove(5);
h1.Find(10);
h1.Find(11);
h1.Find(8);
HashTable<string, string> h2(20);
h2.Insert("ab","cd");
h2.Find("ab");
h2.Find("cd");
}