Hong Kong Radio's program quality is quite good. One of the programs "five thousand years of China" shows historical stories in the form of sitcoms and narratives. From the legendary era to the Republic of China, it was first broadcast in 1983 to 2000. It is a very long-lived program. The voice of the version that can be found online is very fuzzy, but all the programs can be listened to online on its website of "five thousand years of China online". Although you can listen online, you need science to go online, and you can't continue listening after the online listening is interrupted. It's hard. Therefore, I think of using the crawler from Python to download all the programs and listen slowly.

Analyze Html page
Open the review element in the browser to find the link tag of the audio, and find that the links are all in the a tag of class. Listen button. Just navigate to the tag, take out text as the file name, and use href as the download url.
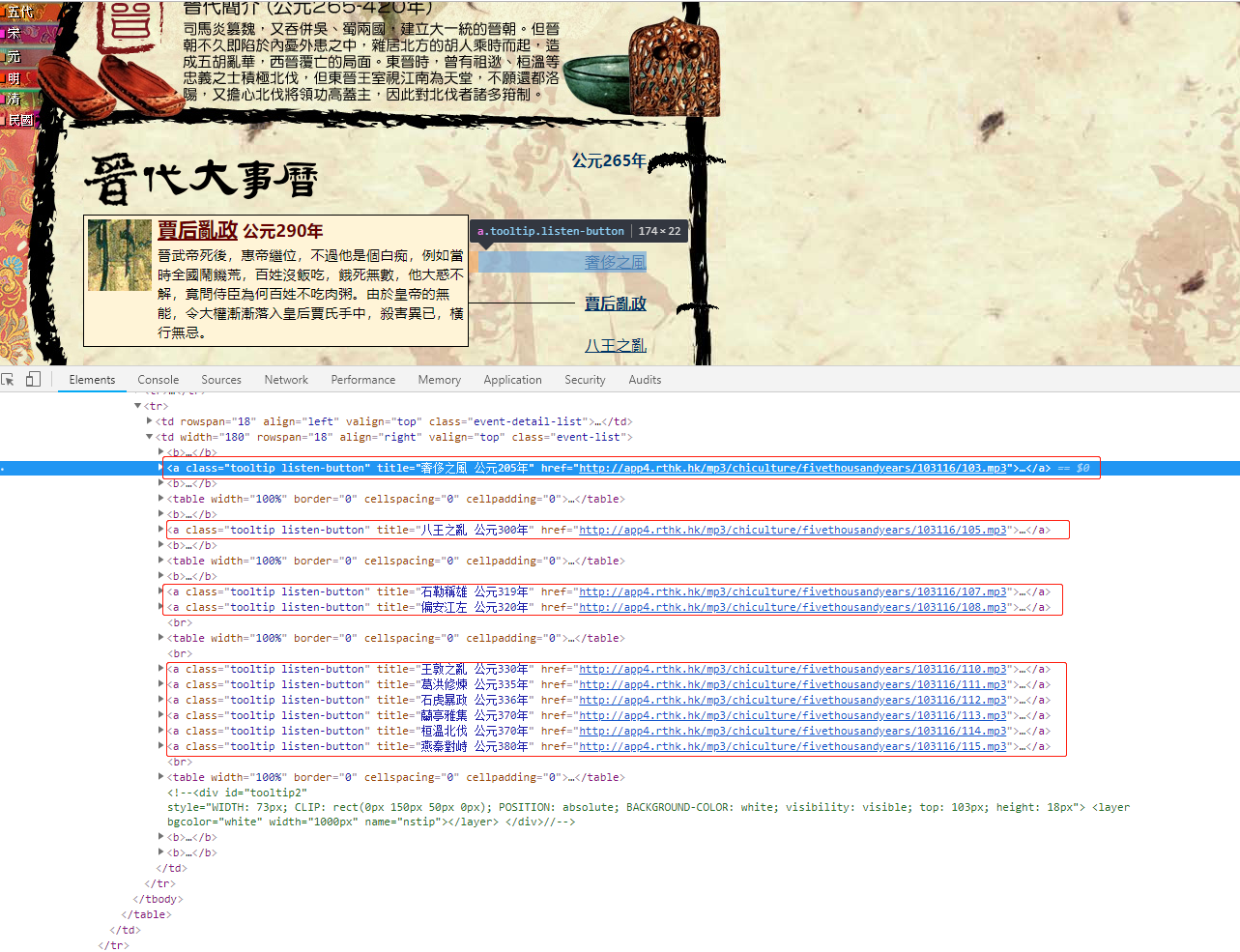
code implementation
The code is very simple. First, the main structure is as follows:
''' //Download 5000 years of China ''' from bs4 import BeautifulSoup import requests,urllib,re import time import aiohttp import asyncio import os async def main(): start_page = 1 while True: url = 'http://rthk9.rthk.hk/chiculture/fivethousandyears/subpage{0}.htm'.format(start_page) soup = await getUrl(url) #take html content if not soup.title: return #Until nothing exits title = soup.title.text title = title[title.rfind(' ')+1:] listenbutton = soup.select(".listen-button") #Find out all.listen-button Class labels #according to title Create the corresponding folder rootPath = './Five thousand years of China/' if not os.path.exists(rootPath + title): os.makedirs(rootPath + title) for l in listenbutton: if l.text != "": href = l['href'] filename = str(title) +'_' + str(l.text) if filename.find('Ad') > -1 await download(filename=filename,url=href,title=title) #Download voice
start_page += 1 #next page asyncio.run(main())
Where asynchronous function (coroutine) getUrl:
async def getUrl(url): async with aiohttp.ClientSession() as session: #Due to need science Online, so you need a local agent async with session.get(url,proxy='http://127.0.0.1:1080') as resp: wb_data = await resp.text() soup = BeautifulSoup(wb_data,'lxml') return soup
download voice function asynchronously:
async def download(url,filename,title): file_name = './Five thousand years of China/{0}/{1}'.format(title,filename + '.mp3') async with aiohttp.ClientSession() as session: async with session.get(url,proxy='http://127.0.0.1:1080') as resp: with open(file_name, 'wb') as fd: while True: chunk = await resp.content.read() if not chunk: break fd.write(chunk)
Thanks to the asynchronous IO mode, you can download one page soon.