Let's talk about data analysis:
- Data collection: responsible for data collection
- Data cleaning: responsible for data filtering
- Data analysis: data operation and sorting
- Data display: output results in chart or table mode
shell script data processing
1) Data retrieval: grep tr cut
2) Data processing: uniq sort tee paste xargs
In the previous scripts, we used grep, cut, tr, uniq, sort and other commands to retrieve strings through pipes, and then obtained the results through the corresponding operations in the shell. You may also experience the hard work and poor performance in the process of data retrieval. No way, that's all. We still need to complete the task.
Disadvantages: complex command combinations
Multiple operations
It's hard to get started
terms of settlement
Well, after learning this lesson, all your previous pains can be solved. Today I want to introduce you to a more powerful command awk. It allows you to retrieve the data you need from the output stream without using a large number of command combinations as before. It can be completed with only one command awk. It can also process data through awk without additional shell operations.
Application scenarios of awk
String interception
Data operation
Such as memory usage scripts
shell processing of output stream awk
1. awk introduction
In daily computer management, there will always be a lot of data output to the screen or file. These outputs include standard output and standard error output. By default, all this information is output to the default output device - screen. However, only a small part of the large amount of data output is what we need to focus on. We need to filter or extract the information we need or pay attention to for subsequent calls. In the previous study, we learned to use grep to filter these data and use cut and tr commands to propose some fields, but they do not have the ability to extract and process data. They must first filter, then extract and transfer them to variables, and then process them through variable extraction, such as:
Statistical steps for memory usage 1) adopt free -m Extract the total memory and assign it to the variable memory_totle 2)adopt free -m Extract n Memory usage, assigned to variable memory_use 3)Calculate memory usage through mathematical operations
You need to execute multiple steps to get the memory utilization. Is there a command that integrates filtering, extraction and operation? Of course, it's the command I'm going to introduce to you today: awk
Parallel commands include gawk, pgawk and dgawk
awk is a powerful language that can process data and generate formatted reports. awk considers that each line in the file is a record, the separator between records is a newline character, and each column is a field. The separator between fields is one or more spaces or tab characters by default
awk works by reading data, treating each row of data as a record. Each record is divided into several fields with field separators, and then the values of each field are output
2. awk syntax
awk [options] '[BEGIN]{program}[END]' [FILENAME]
Common command options
-F fs Specifies that the file separator that depicts the data field in a row defaults to a space
-f file Specifies the file name of the reader
-v var=value definition awk Variables and defaults used in the program
be careful: awk The procedure is defined by the left brace and the right brace. Program commands must be placed between two braces. because awk The command line assumes that the program is a single text string, so you must include the program in single quotes.
1)The program must be enclosed in curly braces
2)The program must be enclosed in single quotes
awk Program running priority is:
1)BEGIN: Execute before starting processing the data stream, optional
2)program: How to process data flow is required
3)END: Execute after processing the data stream. Optional
3. Basic application of awk
Be able to skillfully use awk to intercept rows, columns and strings of standard output
Learning use cases [root@zutuanxue ~]# cat test 1 the quick brown fox jumps over the lazy cat . dog 2 the quick brown fox jumps over the lazy cat . dog 3 the quick brown fox jumps over the lazy cat . dog 4 the quick brown fox jumps over the lazy cat . dog 5 the quick brown fox jumps over the lazy cat . dog
3.1) awk extraction of fields (columns)
Field extraction: extract a column of data in a text and print it out
Field related built-in variables
$0 represents the entire line of text
$1 represents the first data field in the text line
$2 represents the second data field in the text line
$N represents the nth data field in the text line
$NF represents the last data field in the text line
Read in test Each line of data and print out each line of data
[root@zutuanxue ~]# awk '{print $0}' test
1 the quick brown fox jumps over the lazy cat . dog
2 the quick brown fox jumps over the lazy cat . dog
3 the quick brown fox jumps over the lazy cat . dog
4 the quick brown fox jumps over the lazy cat . dog
5 the quick brown fox jumps over the lazy cat . dog
Print test Sixth field
[root@zutuanxue ~]# awk '{print $6}' test
jumps
jumps
jumps
jumps
jumps
Print test Last field
[root@zutuanxue ~]# awk '{print $NF}' test
dog
dog
dog
dog
dog
3.2) detailed explanation of command options
-F: Specifies the separator between fields
When the output data stream field format is not the awk default field format, we can use the - F command option to redefine the data stream field separator. For example:
The processed file is / etc/passwd. You want to print the first column, the third column and the last column
[root@zutuanxue ~]# awk -F ':' '{print $1,$3,$NF}' /etc/passwd
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/halt
mail 8 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
nobody 99 /sbin/nologin
systemd-network 192 /sbin/nologin
dbus 81 /sbin/nologin
polkitd 999 /sbin/nologin
postfix 89 /sbin/nologin
chrony 998 /sbin/nologin
sshd 74 /sbin/nologin
ntp 38 /sbin/nologin
tcpdump 72 /sbin/nologin
nscd 28 /sbin/nologin
mysql 997 /sbin/nologin
www 996 /sbin/nologin
apache 48 /sbin/nologin
tss 59 /sbin/nologin
zabbix 995 /sbin/nologin
saslauth 994 /sbin/nologin
grafana 993 /sbin/nologin
You can see, awk The default separator for the output field is also a space
-f file: if the awk command repeats daily work without too many changes, you can write the program to the file. It's good to use - f to call the program file every time, which is convenient and efficient.
[root@zutuanxue ~]# cat abc
{print $1,$3,$NF}
[root@zutuanxue ~]# awk -f abc test
1 quick dog
2 quick dog
3 quick dog
4 quick dog
5 quick dog
-v defines variables. Since the author writes awk according to the language, the most important element in the language - variables must not be absent, so you can use the - v command option to define variables
[root@zutuanxue ~]# awk -v name='baism' 'BEGIN{print name}'
baism
A variable is defined name=baism,The variables are then read out.
3.3) awk extraction of records (lines)
Record extraction: extract a line in a text and print it out
There are two methods to extract records: a. by line number b. by regular matching
Record related built-in variables
NR: specify line number number row
extract test Third row data
Specify a line number of 3
[root@zutuanxue ~]# awk 'NR==3{print $0}' test
3 the quick brown fox jumps over the lazy cat . dog
The exact match string for the first field of the specified line is 3
[root@zutuanxue ~]# awk '$1=="3"{print $0}' test
3 the quick brown fox jumps over the lazy cat . dog
3.4) awk string extraction
The point where records and fields meet is a string
Print test The sixth field in the third row
[root@zutuanxue ~]# awk 'NR==3{print $6}' test
jumps
4. Priority of awk program
Priority of awk code block
As for the execution priority of awk PROGRAM, BEGIN is the code block with the highest priority, which is executed before executing PROGRAM. There is no need to provide data source, because it does not involve any data processing and does not depend on PROGRAM code blocks; PROGRAM is a required code block and the default code block for data flow. Therefore, the data source must be provided during execution; END is the operation after processing the data stream. If the END code block needs to be executed, it must be supported by PROGRAM. A single code block cannot be executed.
BEGIN: what to do before processing the data source? It can be executed without the data source
PROGRAM: what to do with the data source [required by default]
END: what to do after processing the data source? The program needs the data source
Priority display
[root@zutuanxue ~]# awk 'BEGIN{print "hello zutuanxue"}{print $0}END{print "bye zutuanxue"}' test
hello zutuanxue
1 the quick brown fox jumps over the lazy cat . dog
2 the quick brown fox jumps over the lazy cat . dog
3 the quick brown fox jumps over the lazy cat . dog
4 the quick brown fox jumps over the lazy cat . dog
5 the quick brown fox jumps over the lazy cat . dog
bye zutuanxue
No data source is required and can be executed directly
[root@zutuanxue ~]# awk 'BEGIN{print "hello world"}'
hello world
No data stream was provided, so it cannot be executed successfully
[root@zutuanxue ~]# awk '{print "hello world"}'
[root@zutuanxue ~]# awk 'END{print "hello world"}'
5. awk advanced applications
awk is a language, so it will conform to the characteristics of the language. In addition to defining variables, it can also define arrays, perform operations and process control. Let's take a look next.
5.1) awk define variables and arrays
Define variables
[root@zutuanxue ~]# awk -v name='baism' 'BEGIN{print name}'
baism
[root@zutuanxue ~]# awk 'BEGIN{name="baism";print name}'
baism
Array definition method: array name [index] = value
Define array array,There are two elements, respectively 100200, to print array elements.
[root@zutuanxue ~]# awk 'BEGIN{array[0]=100;array[1]=200;print array[0],array[1]}'
100 200
[root@zutuanxue ~]# awk 'BEGIN{a[0]=100;a[1]=200;print a[0]}'
100
[root@zutuanxue ~]# awk 'BEGIN{a[0]=100;a[1]=200;print a[1]}'
200
5.2) awk operation
- Assignment operation=
- Comparison operation > > = = < < ==
- Mathematical operations + - * /% * * + –
- Logical operation & & |!
- Matching operation ~~ Exact match = ==
a. Assignment operation: it mainly assigns values to variables or arrays, such as:
Variable assignment name = "baism" school = "zutuanxue"
Array assignment array[0]=100
[root@zutuanxue ~]# awk -v name='baism' 'BEGIN{print name}'
baism
[root@zutuanxue ~]# awk 'BEGIN{school="zutuanxue";print school}'
zutuanxue
[root@zutuanxue ~]# awk 'BEGIN{array[0]=100;print array[0]}'
100
b. Comparison operation. If the comparison is a string, it is compared according to the ascii coding sequence table. If the result returns true, it is represented by 1, and if the result returns false, it is represented by 0
ascii
[root@zutuanxue ~]# awk 'BEGIN{print "a" >= "b" }'
0
[root@zutuanxue ~]# awk 'BEGIN{print "a" <= "b" }'
1
[root@zutuanxue ~]# awk '$1>4{print $0}' test
5 the quick brown fox jumps over the lazy cat . dog
[root@zutuanxue ~]# awk 'BEGIN{print 100 >= 1 }'
1
[root@zutuanxue ~]# awk 'BEGIN{print 100 == 1 }'
0
[root@zutuanxue ~]# awk 'BEGIN{print 100 <= 1 }'
0
[root@zutuanxue ~]# awk 'BEGIN{print 100 < 1 }'
0
[root@zutuanxue ~]# awk 'BEGIN{print 100 != 1 }'
1
c. Mathematical operation
[root@zutuanxue ~]# awk 'BEGIN{print 100+3 }'
103
[root@zutuanxue ~]# awk 'BEGIN{print 100-3 }'
97
[root@zutuanxue ~]# awk 'BEGIN{print 100*3 }'
300
[root@zutuanxue ~]# awk 'BEGIN{print 100/3 }'
33.3333
[root@zutuanxue ~]# awk 'BEGIN{print 100**3 }'
1000000
[root@zutuanxue ~]# awk 'BEGIN{print 100%3 }'
1
[root@zutuanxue ~]# awk -v 'count=0' 'BEGIN{count++;print count}'
1
[root@zutuanxue ~]# awk -v 'count=0' 'BEGIN{count--;print count}'
-1
d. Logical operation
And operation:True is true, true is false, false is false
[root@zutuanxue ~]# awk 'BEGIN{print 100>=2 && 100>=3 }'
1
[root@zutuanxue ~]# awk 'BEGIN{print 100>=2 && 1>=100 }'
0
Or operation:True is true, true is false, false is false
[root@zutuanxue ~]# awk 'BEGIN{print 100>=2 || 1>=100 }'
1
[root@zutuanxue ~]# awk 'BEGIN{print 100>=200 || 1>=100 }'
0
Non operation
[root@manage01 resource]# awk 'BEGIN{print ! (100>=2)}'
0
e. Matching operation
[root@zutuanxue ~]# awk -F ':' '$1 ~ "^ro" {print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@zutuanxue ~]# awk -F ':' '$1 !~ "^ro" {print $0}' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:997:User for polkitd:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
nscd:x:28:28:NSCD Daemon:/:/sbin/nologin
mysql:x:997:995::/home/mysql:/sbin/nologin
www:x:996:994::/home/www:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
zabbix:x:995:993:Zabbix Monitoring System:/var/lib/zabbix:/sbin/nologin
saslauth:x:994:76:Saslauthd user:/run/saslauthd:/sbin/nologin
grafana:x:993:992:grafana user:/usr/share/grafana:/sbin/nologin
5.3) awk environment variables
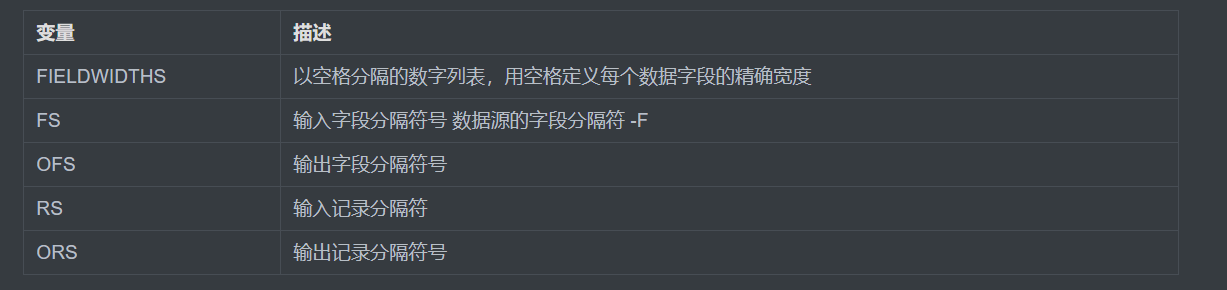
FIELDWIDTHS:Redefine the column width and print. Note that it cannot be used $0 Print all because $0 This is to print the full content of the line, not the fields you defined
[root@zutuanxue ~]# awk 'BEGIN{FIELDWIDTHS="5 2 8"}NR==1{print $1,$2,$3}' /etc/passwd
root: x: 0:0:root
FS:Specify the field separator in the data source, similar to command options-F
[root@zutuanxue ~]# awk 'BEGIN{FS=":"}NR==1{print $1,$3,$NF}' /etc/passwd
root 0 /bin/bash
OFS:Specifies the separator for the field after output to the screen
[root@zutuanxue ~]# awk 'BEGIN{FS=":";OFS="-"}NR==1{print $1,$3,$NF}' /etc/passwd
root-0-/bin/bash
RS:Specifies the separator for the record
[root@zutuanxue ~]# awk 'BEGIN{RS=""}{print $1,$13,$25,$37,$49}' test
1 2 3 4 5
After changing the record separator to an empty line, all lines will become one line, so all fields will be on one line.
ORS:The separator of the record after output to the screen. The default is enter
[root@zutuanxue ~]# awk 'BEGIN{RS="";ORS="*"}{print $1,$13,$25,$37,$49}' test
1 2 3 4 5*[root@zutuanxue ~]#
As you can see, the prompt and output are on the same line, because the default carriage return is changed to*
5.4) process control
if judgment statement
Learning use cases
[root@zutuanxue ~]# cat num
1
2
3
4
5
6
7
8
9
single if sentence
Print $1 Rows greater than 5
[root@zutuanxue ~]# awk '{if($1>5)print $0}' num
6
7
8
9
if...else sentence
If $1 If greater than 5, divide by 2 output, otherwise multiply by 2 output
[root@zutuanxue ~]# awk '{if($1>5)print $1/2;else print $1*2}' num
2
4
6
8
10
3
3.5
4
4.5
for loop statement
Learning use cases
[root@zutuanxue ~]# cat num2
60 50 100
150 30 10
70 100 40
Add up all the data in a row $1+$2+$3
[root@zutuanxue ~]# awk '{sum=0;for (i=1;i<4;i++){sum+=$i}print sum}' num2
210
190
210
If you don't understand, you can see the following format
[root@zutuanxue ~]# awk '{
> sum=0
> for (i=1;i<4;i++) {
> sum+=$i
> }
> print sum
> }' num2
210
190
210
while loop statement – judge before execute
Learning use cases
[root@zutuanxue ~]# cat num2
60 50 100
150 30 10
70 100 40
Accumulate the values of each line in the file, and stop accumulating when the sum is greater than or equal to 150
[root@zutuanxue ~]# awk '{sum=0;i=1;while(sum<150){sum+=$i;i++}print sum}' num2
210
150
170
If you don't understand, you can see the following format
[root@zutuanxue ~]# awk '{
sum=0
i=1
while (sum<150) {
sum+=$i
i++
}
print sum
}' num2
210
150
170
do... while loop statement – execute before Judge
Learning use cases
[root@zutuanxue ~]# cat num2
60 50 100
150 30 10
70 100 40
Accumulate the values of each line in the file, and stop accumulating when the sum is greater than or equal to 150
[root@zutuanxue ~]# awk '{sum=0;i=1;do{sum+=$i;i++}while(sum<150);print sum}' num2
210
150
170
If you don't understand, you can see the following format
[root@zutuanxue ~]# awk '{
> sum=0
> i=1
> do {
> sum+=$i
> i++
> }while (sum<150)
> print sum
> }' num2
210
150
170
Loop control statement
break jumps out of the loop and continues to execute subsequent statements
Learning use cases
[root@zutuanxue ~]# cat num2
60 50 100
150 30 10
70 100 40
Accumulate the value of each line, and stop accumulation when the sum is greater than 150
[root@zutuanxue ~]# awk '{
> sum=0
> i=1
> while (i<4){
> sum+=$i
> if (sum>150){
> break
> }
> i++
> }
> print sum
> }' num2
210
180
170