
From: FreeBuf.COM
Author: secist
Links:https://www.freebuf.com/sectool/212820.html
Sampler is a tool for shell command execution, visualization, and alerts. It is configured using a simple YAML file.
1. Why do I need it?
You can sample any dynamic process directly from the terminal - watch for changes in the database, monitor MQ dynamic messages, trigger deployment scripts, and get notifications when finished.
If there is a way to get metric s using shell commands, you can use Sampler to visualize them immediately.
2. Installation
macOS
brew cask install sampler
or
sudo curl -Lo /usr/local/bin/sampler https://github.com/sqshq/sampler/releases/download/v1.0.3/sampler-1.0.3-darwin-amd64 sudo chmod +x /usr/local/bin/sampler
Linux
sudo wget https://github.com/sqshq/sampler/releases/download/v1.0.3/sampler-1.0.3-linux-amd64 -O /usr/local/bin/sampler sudo chmod +x /usr/local/bin/sampler
Note: The libasound2-dev system library needs to be installed for Sampler to play trigger sounds. Usually the library is installed in the appropriate location, but if it is not - you can use your customary package manager for installation, such as apt install libasound2-dev
Windows (Experimental)
Recommended for use with advanced console emulators, such as Cmder
Download .exe
3. Use
Specify shell commands that Sampler will execute at the appropriate rate. Output is used for visualization.
Using Sampler is essentially a three-step process:
Define shell commands in the YAML configuration file
Run sampler-c config.yml
Adjust component size and position on UI
There are already many monitoring systems in the market
Sampler is by no means a replacement for monitoring systems, but an easy-to-set development tool.
If spinning up and configuring Prometheus with Grafana are completely redundant tasks, then Sampler may be the correct solution. No server, no database, no deployment required - you specify the shell command and it will work.
Do I need to install it on each server I monitor?
No, you can run Sampler locally, but you can still collect telemetry data from multiple remote computers. Any visualization may have init commands in which you can ssh to the remote server. See SSH example
4. Components
The following is a list of configuration examples for each component type, including macOS-compatible sampling scripts.
Runchart
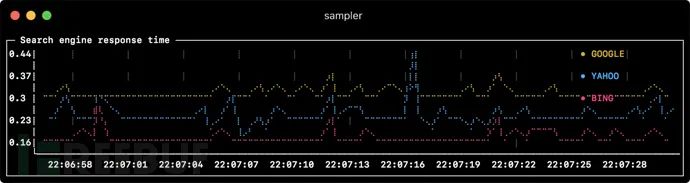
runcharts:
- title: Search engine response time
rate-ms: 500 # sampling rate, default = 1000
scale: 2 # number of digits after sample decimal point, default = 1
legend:
enabled: true # enables item labels, default = true
details: false # enables item statistics: cur/min/max/dlt values, default = true
items:
- label: GOOGLE
sample: curl -o /dev/null -s -w '%{time_total}' https://www.google.com
color: 178 # 8-bit color number, default one is chosen from a pre-defined palette
- label: YAHOO
sample: curl -o /dev/null -s -w '%{time_total}' https://search.yahoo.com
- label: BING
sample: curl -o /dev/null -s -w '%{time_total}' https://www.bing.comSparkline
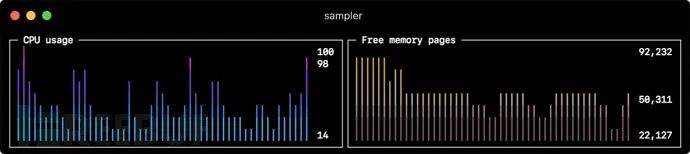
sparklines:
- title: CPU usage
rate-ms: 200
scale: 0
sample: ps -A -o %cpu | awk '{s+=$1} END {print s}'
- title: Free memory pages
rate-ms: 200
scale: 0
sample: memory_pressure | grep 'Pages free' | awk '{print $3}'Barchart
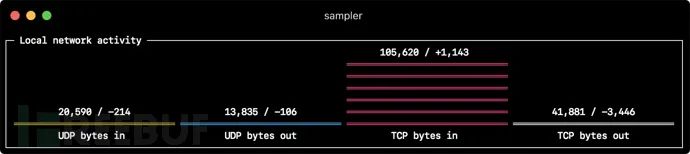
barcharts:
- title: Local network activity
rate-ms: 500 # sampling rate, default = 1000
scale: 0 # number of digits after sample decimal point, default = 1
items:
- label: UDP bytes in
sample: nettop -J bytes_in -l 1 -m udp | awk '{sum += $4} END {print sum}'
- label: UDP bytes out
sample: nettop -J bytes_out -l 1 -m udp | awk '{sum += $4} END {print sum}'
- label: TCP bytes in
sample: nettop -J bytes_in -l 1 -m tcp | awk '{sum += $4} END {print sum}'
- label: TCP bytes out
sample: nettop -J bytes_out -l 1 -m tcp | awk '{sum += $4} END {print sum}'Gauge

gauges: - title: Minute progress rate-ms: 500 # sampling rate, default = 1000 scale: 2 # number of digits after sample decimal point, default = 1 percent-only: false # toggle display of the current value, default = false color: 178 # 8-bit color number, default one is chosen from a pre-defined palette cur: sample: date +%S # sample script for current value max: sample: echo 60 # sample script for max value min: sample: echo 0 # sample script for min value - title: Year progress cur: sample: date +%j max: sample: echo 365 min: sample: echo 0
Textbox
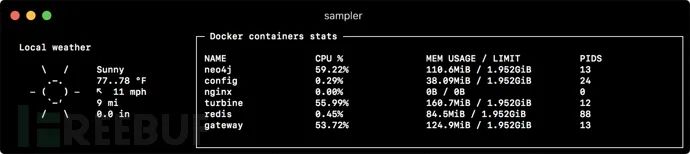
textboxes:
- title: Local weather
rate-ms: 10000 # sampling rate, default = 1000
sample: curl wttr.in?0ATQF
border: false # border around the item, default = true
color: 178 # 8-bit color number, default is white
- title: Docker containers stats
rate-ms: 500
sample: docker stats --no-stream --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.PIDs}}"Asciibox

asciiboxes: - title: UTC time rate-ms: 500 # sampling rate, default = 1000 font: 3d # font type, default = 2d border: false # border around the item, default = true color: 43 # 8-bit color number, default is white sample: env TZ=UTC date +%r
5. Additional functions
Triggers
Triggers allow conditional operations, such as visual/sound alerts or any shell command. The following examples illustrate this concept.
Clock gauge, showing time progress and current time per minute from start
gauges: - title: MINUTE PROGRESS position: [[0, 18], [80, 0]] cur: sample: date +%S max: sample: echo 60 min: sample: echo 0 triggers: - title: CLOCK BELL EVERY MINUTE condition: '[ $label == "cur" ] && [ $cur -eq 0 ] && echo 1 || echo 0' # expects "1" as TRUE indicator actions: terminal-bell: true # standard terminal bell, default = false sound: true # NASA quindar tone, default = false visual: false # notification with current value on top of the component area, default = false script: say -v samantha `date +%I:%M%p` # an arbitrary script, which can use $cur, $prev and $label variables
Search engine delay chart to alert users when delay exceeds threshold
runcharts:
- title: SEARCH ENGINE RESPONSE TIME (sec)
rate-ms: 200
items:
- label: GOOGLE
sample: curl -o /dev/null -s -w '%{time_total}' https://www.google.com
- label: YAHOO
sample: curl -o /dev/null -s -w '%{time_total}' https://search.yahoo.com
triggers:
- title: Latency threshold exceeded
condition: echo "$prev < 0.3 && $cur > 0.3" |bc -l # expects "1" as TRUE indicator
actions:
terminal-bell: true # standard terminal bell, default = false
sound: true # NASA quindar tone, default = false
visual: true # visual notification on top of the component area, default = false
script: 'say alert: ${label} latency exceeded ${cur} second' # an arbitrary script, which can use $cur, $prev and $label variablesInteractive shell support
In addition to the sample command, you can specify the init command (which executes only once before sampling) and the transform command (which postprocesses the output of the sampling command). This includes interactive shell use cases, such as establishing a connection to the database only once, and then polling in an interactive shell session.
Basic mode
textboxes: - title: MongoDB polling rate-ms: 500 init: mongo --quiet --host=localhost test # executes only once to start the interactive session sample: Date.now(); # executes with a required rate, in scope of the interactive session transform: echo result = $sample # executes in scope of local session, $sample variable is available for transformation
PTY mode
In some cases, the interactive shell will not work because its stdin is not a terminal. In this case, we can use PTY mode:
textboxes: - title: Neo4j polling pty: true # enables pseudo-terminal mode, default = false init: cypher-shell -u neo4j -p pwd --format plain sample: RETURN rand(); transform: echo "$sample" | tail -n 1 - title: Top on a remote server pty: true # enables pseudo-terminal mode, default = false init: ssh -i ~/user.pem ec2-user@1.2.3.4 sample: top
The init command executes step by step
Multiple init commands can also be executed individually before starting sampling.
textboxes: - title: Java application uptime multistep-init: - java -jar jmxterm-1.0.0-uber.jar - open host:port # or local PID - bean java.lang:type=Runtime sample: get Uptime
variable
If the configuration file contains duplicate patterns, they can be extracted into the variable section. In addition, variables can be specified at startup using the -v/- variable flag, and any system environment variable can also be used in scripting.
variables:
mongoconnection: mongo --quiet --host=localhost test
barcharts:
- title: MongoDB documents by status
items:
- label: IN_PROGRESS
init: $mongoconnection
sample: db.getCollection('events').find({status:'IN_PROGRESS'}).count()
- label: SUCCESS
init: $mongoconnection
sample: db.getCollection('events').find({status:'SUCCESS'}).count()
- label: FAIL
init: $mongoconnection
sample: db.getCollection('events').find({status:'FAIL'}).count()Color theme

theme: light # default = dark
sparklines:
- title: CPU usage
sample: ps -A -o %cpu | awk '{s+=$1} END {print s}'6. Real Scene
data base
The following are examples of different database connections. It is recommended that you use an interactive shell (init script) to make only one connection and reuse it during sampling.
MySQL
# prerequisite: installed mysql shell variables: mysql_connection: mysql -u root -s --database mysql --skip-column-names sparklines: - title: MySQL (random number example) pty: true init: $mysql_connection sample: select rand();
PostgreSQL
# prerequisite: installed psql shell variables: PGPASSWORD: pwd postgres_connection: psql -h localhost -U postgres --no-align --tuples-only sparklines: - title: PostgreSQL (random number example) init: $postgres_connection sample: select random();
MongoDB
# prerequisite: installed mongo shell variables: mongo_connection: mongo --quiet --host=localhost test sparklines: - title: MongoDB (random number example) init: $mongo_connection sample: Math.random();
Neo4j
# prerequisite: installed cypher shell variables: neo4j_connection: cypher-shell -u neo4j -p pwd --format plain sparklines: - title: Neo4j (random number example) pty: true init: $neo4j_connection sample: RETURN rand(); transform: echo "$sample" | tail -n 1
Kafka
Check the kafka lag value, calculate the sum of each queue lag value, alert above threshold, consumergroup, topic.
variables:
kafka_connection: $KAFKA_HOME/bin/kafka-consumer-groups --bootstrap-server localhost:9092
runcharts:
- title: Kafka lag per consumer group
rate-ms: 5000
scale: 0
items:
- label: A->B
sample: $kafka_connection --group group_a --describe | awk 'NR>1 {sum += $5} END {print sum}'
- label: B->C
sample: $kafka_connection --group group_b --describe | awk 'NR>1 {sum += $5} END {print sum}'
- label: C->D
sample: $kafka_connection --group group_c --describe | awk 'NR>1 {sum += $5} END {print sum}'Docker
Docker Container Statistics (CPU, MEM, O/I)
textboxes:
- title: Docker containers stats
sample: docker stats --no-stream --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemPerc}}\t{{.MemUsage}}\t{{.NetIO}}\t{{.BlockIO}}\t{{.PIDs}}"SSH
TOP commands on remote servers
variables: sshconnection: ssh -i ~/my-key-pair.pem ec2-user@1.2.3.4 textboxes: - title: SSH pty: true init: $sshconnection sample: top
JMX
Example of how Java applications work
# prerequisite: download [jmxterm jar file](https://docs.cyclopsgroup.org/jmxterm)
textboxes:
- title: Java application uptime
multistep-init:
- java -jar jmxterm-1.0.0-uber.jar
- open host:port # or local PID
- bean java.lang:type=Runtime
sample: get Uptime
transform: echo $sample | tr -dc '0-9' | awk '{printf "%.1f min", $1/1000/60}'