1. Sharing-Jdbc Concept and Use Skills
This commentary version is 4.0.0-RC1, and the latest version is released on May 21, 2019.
1.1. Binding table
- Refers to the main table and subtable with consistent fragmentation rules. For example, the t_order table and the t_order_item table are all sliced according to order_id, and the two tables are mutually bound tables. There will be no Cartesian product association in multi-table Association queries between bound tables, and the efficiency of association queries will be greatly improved. For example, if the SQL is:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
- Without configuring the binding table relationship, assuming that the fragment key order_id routes the value 10 to slice 0 and the value 11 to slice 1, then the routed SQL should be four, which appear as Cartesian product:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
- After configuring the binding table relationship, the routing SQL should be 2:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
- Where t_order is on the leftmost side of FROM, ShardingSphere will use it as the main table of the entire binding table. All routing calculations will only use the policy of the primary table, so the fragmentation of the t_order_item table will use the condition of t_order. So the partitioning keys between the bound tables should be exactly the same.
1.2. Piecewise algorithm
The data is fragmented by fragmentation algorithm, which supports fragmentation by=, BETWEEN and IN. The fragmentation algorithm needs to be implemented by the developer of the application side, and the flexibility is very high.
At present, four kinds of slicing algorithms are provided. Because fragmentation algorithm is closely related to business implementation, it does not provide built-in fragmentation algorithm, but extracts various scenarios through fragmentation strategy, provides a higher level of abstraction, and provides interfaces for application developers to implement fragmentation algorithm by themselves.
- Accurate Piecewise Algorithms
Corresponding to Precise Sharing Algorithms, it is used to handle scenarios where a single key is used as a splitting key = splitting with IN. It needs to be used in conjunction with Standard Sharing Strategy.
- Scope slicing algorithm
Corresponding to Range Sharing Algorithms, it is used to deal with the scene of BETWEEN AND using a single key as the splitting key. It needs to be used in conjunction with Standard Sharing Strategy.
- Compound Piecewise Algorithms
Corresponding to ComplexKeys Sharing Algorithms, it is used to deal with the scenario of using multiple keys as splitting keys. The logic of multiple splitting keys is more complex, which requires application developers to handle by themselves. It needs to be used in conjunction with Complex Sharing Strategy.
- Hint fragmentation algorithm
The corresponding Hint Sharing Algorithm is used to handle scenarios using Hint line fragmentation. It needs to be used in conjunction with Hint Sharing Strategy.
1.3. Fragmentation strategy
Including the splitting key and the splitting algorithm, because of the independence of the splitting algorithm, it is separated independently. What can really be used for fragmentation is the fragmentation key + fragmentation algorithm, that is, the fragmentation strategy. At present, five fragmentation strategies are provided.
- Standard Fragmentation Strategy
- Compound Fragmentation Strategy
- Line expression fragmentation strategy
For simple fragmentation algorithm, simple configuration can be used to avoid tedious Java code development, such as: t_user_$-> {u_id%8} which means that the t_user table is divided into eight tables according to u_id module 8, and the table names are t_user_0 to t_user_7.
- Hint Fragmentation Strategy
- Non-fragmentation strategy
1.4. SQL Hint
For scenarios where the fragmentation field is not determined by SQL but determined by other external conditions, SQL Hint can be used to inject the fragmentation field flexibly. Example: Internal system, according to the employee login key sub-database, but the database does not have this field. SQL Hint supports both Java API and SQL annotation (to be implemented).
1.5. SQL Support and Non-Support
- see Here
1.6. Line expression
- ${begin..end} denotes range intervals
- ${[unit1, unit2, unit_x]} represents the enumeration value
- If there are successive ${expression} or $->{expression} expressions in row expressions, the final result of the whole expression will be Cartesian combination according to the result of each sub-expression.
${['online', 'offline']}_table${1..3}The final resolution is
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table3
1.7. Forced Piecewise Routing
Extracting fragmented key columns and values by parsing SQL statements and fragmenting them are the ways ShardingSphere implements zero intrusion of SQL. If there is no fragmentation condition in the SQL statement, it can not be fragmented and needs full routing.
In some application scenarios, fragmentation conditions do not exist in SQL, but in external business logic. So you need to provide a way to specify the result of fragmentation externally, called Hint in Harding Sphere.
ShardingSphere uses ThreadLocal to manage fragment key values. A slicing condition can be programmatically added to HintManager, which only takes effect in the current thread.
SQL with mandatory fragmentation routing will directly route to the designated real data node, ignoring the original fragmentation logic.
1.8. Separation of reading and writing
- In the same thread and in the same database connection, if there are write operations, the subsequent read operations are read from the main library to ensure data consistency.
1.9. Arrangement Governance
- Provides governance capabilities such as registry, configuration dynamics, database fuse disablement, call links, etc.
1.10. Notes
- Excessive paging offset can make the performance of data acquisition of database poor. The reason is that Here
1.11. Custom Extension Interface
1.11.1. Examples of sub-database and sub-table

- Entering the entry function, the right-hand dataSource method is the core of the entry function configured by spring boot, which configures sharding properties, which are derived from the configuration properties in application. properties.
- Configuration with custom algorithms is as follows
####################################
# Sub-database and sub-table configuration
####################################
#actual-data-nodes: a real data node consisting of a data source name + a table name separated by decimal points. Multiple tables are separated by commas, supporting inline expressions
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds${0..1}.t_order_${0..1}
# Custom Subdatabase and Tabulation Algorithms
spring.shardingsphere.sharding.tables.t_order.databaseStrategy.complex.shardingColumns=order_id,user_id
spring.shardingsphere.sharding.tables.t_order.databaseStrategy.complex.algorithmClassName=com.xxx.shardingjdbc\
.cusalgo.algorithm.DbShardingAlgorithm
## Custom Tabulation Algorithms
spring.shardingsphere.sharding.tables.t_order.tableStrategy.complex.shardingColumns=order_id,user_id
spring.shardingsphere.sharding.tables.t_order.tableStrategy.complex.algorithmClassName=com.xxx\
.shardingjdbc.cusalgo.algorithm.TableShardingAlgorithm- Find the corresponding classes as follows
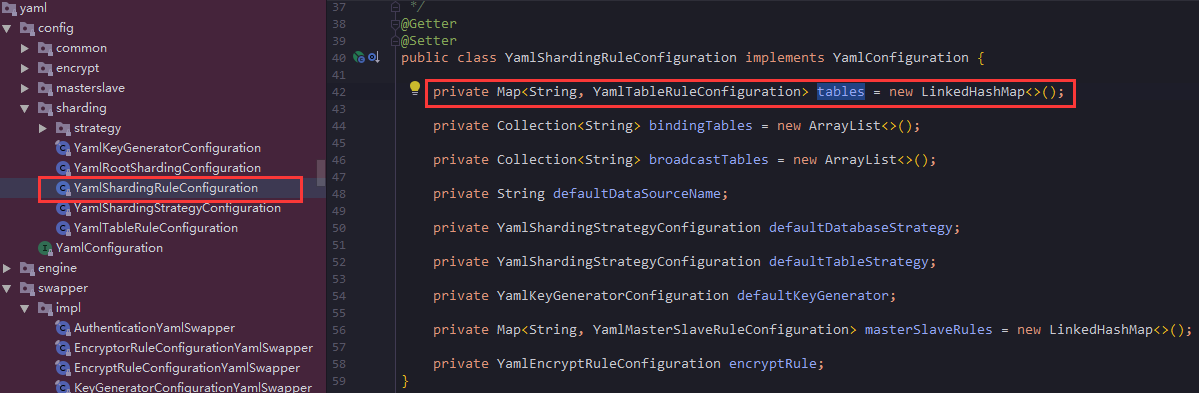
You can see that besides tables, you can configure many other attributes, such as bindingTables, broadcastTables, and so on. You can also see the name of the binding table and broadcast table. As I mentioned in the first chapter of the binding table, the understanding of the broadcast table is very simple. By default, you do not separate the database from the broadcast table, that is, the data in all the sub-database table. Save a copy of each node
Here we focus on the custom configuration class. The above configuration file configures the DbShardingAlgorithm class, which is the custom class. It implements ComplexKeys ShardingAlgorithms.
public class DbShardingAlgorithm implements ComplexKeysShardingAlgorithm {
private static Logger logger = LoggerFactory.getLogger(DbShardingAlgorithm.class);
// Modular factor
public static final Integer MODE_FACTOR = 1331;
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, Collection<ShardingValue> shardingValues) {
List<String> shardingResults = new ArrayList<>();
Long shardingIndex = getIndex(shardingValues) % availableTargetNames.size();
// loop and match datasource
for (String name : availableTargetNames) {
// get logic datasource index suffix
String nameSuffix = name.substring(2);
if (nameSuffix.equals(shardingIndex.toString())) {
shardingResults.add(name);
break;
}
}
logger.info("DataSource sharding index : {}", shardingIndex);
return shardingResults;
}
/**
* get datasource sharding index <p>
* sharding algorithm : shardingIndex = (orderId + userId.hashCode()) % db.size
* @param shardingValues
* @return
*/
private long getIndex(Collection<ShardingValue> shardingValues)
{
long shardingIndex = 0L;
ListShardingValue<Long> listShardingValue;
List<Long> shardingValue;
for (ShardingValue sVal : shardingValues) {
listShardingValue = (ListShardingValue<Long>) sVal;
if ("order_id".equals(listShardingValue.getColumnName())) {
shardingValue = (List<Long>) listShardingValue.getValues();
shardingIndex += Math.abs(shardingValue.get(0)) % MODE_FACTOR;
} else if ("user_id".equals(listShardingValue.getColumnName())) {
shardingValue = (List<Long>) listShardingValue.getValues();
// Here% 1313 is just to prevent spillovers
shardingIndex += Math.abs(shardingValue.get(0).hashCode()) % MODE_FACTOR;
}
}
return shardingIndex;
}
}Continue to track entry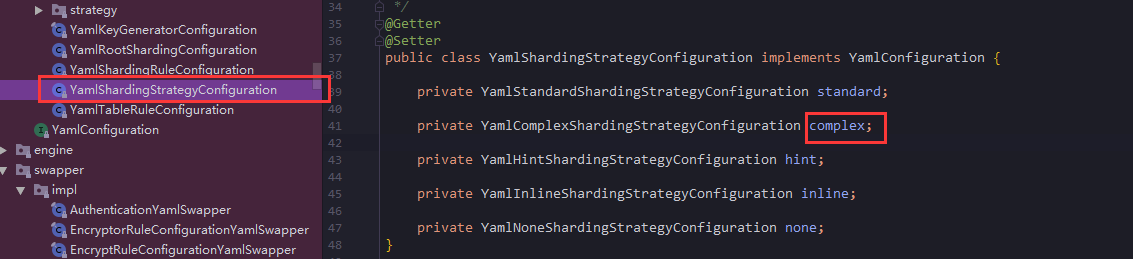
You can see that it implements a total of five interface configurations, and the Complex Keys Sharing Algorithms above are from the complex configuration.
- As for which interfaces to implement, see the following figure
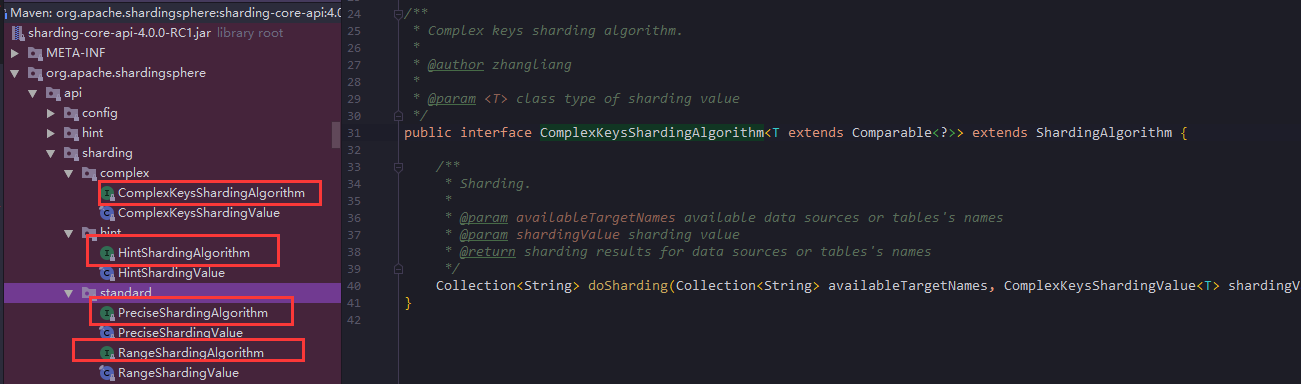
- The four interfaces mentioned above are the interfaces that our users can customize to implement. Once we have written the implementation class, we can configure the whole class name and use it.
To get a full understanding of Sharing-jdbc and its related components, step-by-step Here