Introduction
Due to the need to write a java program and an existing c program (AFL) for local communication in the near future, the efficiency of sending data using udp is not very high. In addition, AFL itself uses shm to share the physical memory to obtain the execution path information of the subroutine to be tested, while the shared memory of Java program only has the way of file mapping memory, similar to mmap in c. Therefore, consider changing the shared memory mechanism of AFL to mmap. This paper will test the performance of mmap, shm and java nio MappedByteBuffer in linux c to evaluate whether modifying the shared memory mode of AFL will affect its own performance.
Shared memory background
mmap and shm
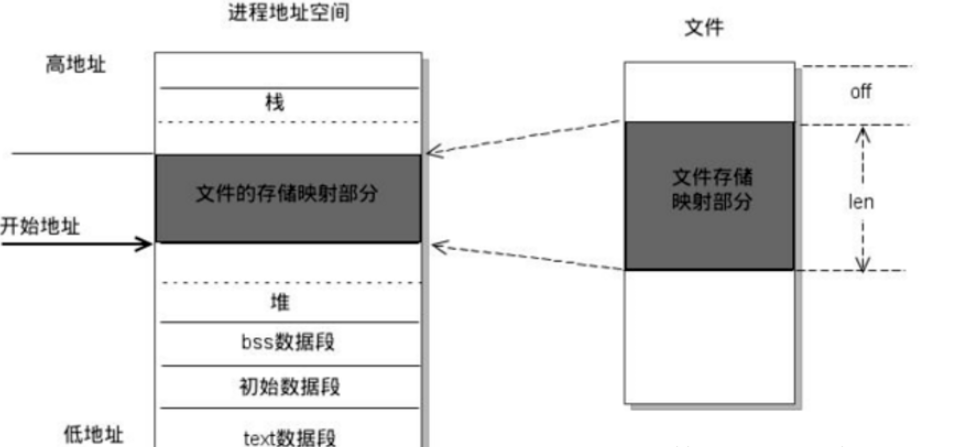
The memory mapping function mmap maps the contents of a file to a section of memory (to be exact, virtual memory). By reading and modifying this section of memory, the file can be read and modified. The mmap() system call enables processes to share memory by mapping an ordinary file. After the ordinary file is mapped to the process address space, the process can access the file in the way of accessing memory without other system calls (read, write).
Example of mmap chart:
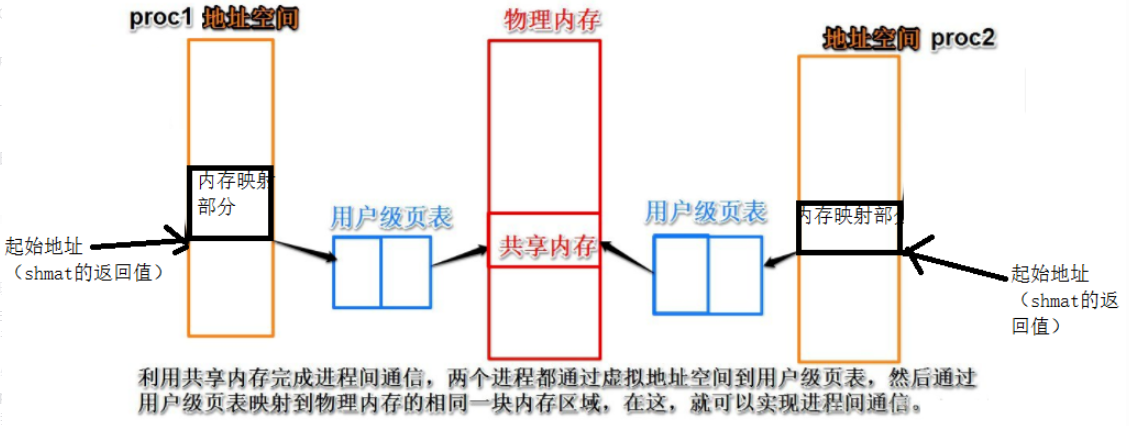
shm directly maps the virtual memory of the process space to the actual physical memory.
shm legend:
Summary mmap and shm:
- mmap is to create a file on disk and open up a space in each process address space for mapping. For shm, each process of shm will eventually map to the same piece of physical memory. shm is stored in physical memory, so the reading and writing speed is faster than that of disk in theory (the reason will be analyzed in combination with the experimental results later), but the storage capacity is not very large.
- Compared with shm, mmap is simpler and more convenient to call, so this is why everyone likes to use it.
- Another advantage of mmap is that when the machine restarts, because mmap saves the file on the disk, and this file also saves the image of operating system synchronization, mmap will not be lost, but shmget will be lost.
test
Experimental environment
linux servers use kvm virtual machines, so the actual test may not be particularly accurate. Other virtual machines run another experiment in 24h.
4-core 16G memory
Test item
- Random write 1 byte
- Clear shared memory
64KB shared memory size no load
| gcc + mmap | gcc + shm | gcc O3 + mmap | gcc O3 + shm | java MappedByteBuffer | |
|---|---|---|---|---|---|
| 1e9 random writes | 9.535s | 9.716s | 8.761s | 9.548s | 11.672s |
| Reset for 1e7 times | 20.621s | 19.952s | 20.537s | 20.362s | 160.178s |
It can be seen that under the size of 64K shared memory, there is no significant difference in performance between random write mmap and shm, and MappedByteBuffer will be nearly 20% slower. However, MappedByteBuffer is inefficient in clearing large memory.
64KB shared memory size, about 25% CPU load
An additional program is run, which is stable at about 25% of the cpu using top.
| gcc + mmap | gcc + shm | gcc O3 + mmap | gcc O3 + shm | java MappedByteBuffer | |
|---|---|---|---|---|---|
| 1e9 random writes | 9.478s | 9.616s | 8.262s | 9.634s | 11.036s |
| Reset for 1e7 times | 20.097s | 20.239s | 19.713s | 19.252s | 142.245s |
In this experiment, I expected that shm would be better than mmap, because I thought that the memory of mmap test program might be replaced by other programs. If this situation is found later, shm test program can't avoid it. However, the overall experimental results are faster than those without load, which still makes me feel strange. I can only attribute it to the operation of virtual machines, which can not completely isolate resources. I suggest you run on your computer to see the results.
1G shared memory size
| gcc + mmap | gcc + shm | java MappedByteBuffer | |
|---|---|---|---|
| 1e9 random writes | 758.426s | 149.275s | 805.912s |
According to the experimental results, the performance of shm is much better than that of mmap. MappedByteBuffer is less than 10% slower than that of mmap, which is an improvement over before. Maybe JIT has been running for a long time and slowly optimized.
The reason why shm is so much better than mmap is that the cache must be far from 1G, so a large number of cache replacement operations are involved. Because shm directly puts the contents of physical memory into the cache, the speed must be much faster than the contents of file mapping into the cache.
summary
According to the experimental results, the following conclusions are drawn
- Shared memory is very efficient when the mapping size is small. mmap, shm and even MappedByteBuffer are very efficient. The time cost of circulating 1e9 random write operations is about 10s. Assuming that the cpu frequency is 2GHz, it takes only 20 machine cycles to cycle operations (i + +, i < 1e9), generate random numbers and write operations in one cycle.
- When the mapping size of shared memory is large, shm is more efficient than mmap. However, shm directly occupies physical memory, which may affect the efficiency of other programs, because less physical memory can be used, increasing the probability of page change. However, because mmap maps virtual memory, it can open up a higher space limit than shm, and will be saved to a file, which is more operable than shm.
Attached test code
// test_mmap.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/time.h>
#include<sys/mman.h>
#include<fcntl.h>
#define SIZE (1 << 16) // 64KB
#define TEST_NUM 10000000 // 1e7
int main() {
int fd = open("share-memory-file", O_RDWR | O_CREAT | O_TRUNC, 0644);
ftruncate(fd, SIZE);
// In one byte
char *p = mmap(NULL, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
close(fd);
struct timeval start, end;
double during_time;
// test random write
gettimeofday(&start, NULL);
char to_write = 0b01010101;
for (long long i = 0; i < TEST_NUM * 100; i++) {
int pos = rand() % SIZE;
memcpy(p + pos, &to_write, sizeof(char));
}
gettimeofday(&end, NULL);
during_time = end.tv_sec - start.tv_sec + (double)end.tv_usec / 1000000 - (double)start.tv_usec / 1000000;
printf("test random write cost %lf sec\n", during_time);
// test set zero
gettimeofday(&start, NULL);
for (long long i = 0; i < TEST_NUM; i++) {
memset(p, 0, SIZE);
}
gettimeofday(&end, NULL);
during_time = end.tv_sec - start.tv_sec + (double)end.tv_usec / 1000000 - (double)start.tv_usec / 1000000;
printf("test set zero cost %lf sec\n", during_time);
int ret = munmap(p, SIZE);
if(ret < 0) {
perror("mmumap");
exit(1);
}
return 0;
}
// test_shm.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/time.h>
#include<sys/shm.h>
#include<sys/types.h>
#include<sys/mman.h>
#include<fcntl.h>
#define SIZE (1 << 16) // 64KB
#define TEST_NUM 10000000 // 1e7
int main() {
int shm_id = shmget(IPC_PRIVATE, SIZE, IPC_CREAT | IPC_EXCL | 0600);
char* p = shmat(shm_id, NULL, 0);
struct timeval start, end;
double during_time;
// test random write
gettimeofday(&start, NULL);
char to_write = 0b01010101;
for (long long i = 0; i < TEST_NUM * 100; i++) {
int pos = rand() % SIZE;
memcpy(p + pos, &to_write, sizeof(char));
}
gettimeofday(&end, NULL);
during_time = end.tv_sec - start.tv_sec + (double)end.tv_usec / 1000000 - (double)start.tv_usec / 1000000;
printf("test random write cost %lf sec\n", during_time);
// test set zero
gettimeofday(&start, NULL);
for (long long i = 0; i < TEST_NUM; i++) {
memset(p, 0, SIZE);
}
gettimeofday(&end, NULL);
during_time = end.tv_sec - start.tv_sec + (double)end.tv_usec / 1000000 - (double)start.tv_usec / 1000000;
printf("test set zero cost %lf sec\n", during_time);
shmctl(shm_id, IPC_RMID, NULL);
return 0;
}
// ShareMemory.java
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.util.Random;
public class ShareMemory {
int mapSize = 1 << 16;
String shareFileName="mem"; //Shared memory file name
String sharePath="sm"; //Shared memory path
MappedByteBuffer mapBuf = null; //Define shared memory buffers
FileChannel fc = null; //Define the corresponding file channel
RandomAccessFile RAFile = null; //Define a random access file object
byte[] buff = new byte[1];
public static Random rand = new Random();
public ShareMemory() {
File folder = new File(sharePath);
if (!folder.exists()) {
folder.mkdirs();
}
this.sharePath+=File.separator;
try {
File file = new File(this.sharePath + this.shareFileName+ ".sm");
if(file.exists()){
RAFile = new RandomAccessFile(this.sharePath + this.shareFileName + ".sm", "rw");
fc = RAFile.getChannel();
}else{
RAFile = new RandomAccessFile(this.sharePath + this.shareFileName + ".sm", "rw");
//Get the corresponding file channel
fc = RAFile.getChannel();
byte[] bb = new byte[mapSize];
//Create byte buffer
ByteBuffer bf = ByteBuffer.wrap(bb);
bf.clear();
//Set the file location for this channel.
fc.position(0);
//Writes a sequence of bytes from the given buffer to this channel.
fc.write(bf);
fc.force(false);
//Map the file area of this channel directly to memory.
}
mapBuf = fc.map(FileChannel.MapMode.READ_WRITE, 0, mapSize);
} catch (IOException e) {
e.printStackTrace();
}
}
public void closeSMFile() {
if (fc != null) {
try {
fc.close();
} catch (IOException e) {
e.printStackTrace();
}
fc = null;
}
if (RAFile != null) {
try {
RAFile.close();
} catch (IOException e) {
e.printStackTrace();
}
RAFile = null;
}
mapBuf = null;
}
public int reset(){
try {
mapBuf.position(0);
mapBuf.put(new byte[mapSize], 0, mapSize);
return 1;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
public static void main(String[] argv) {
ShareMemory sm = new ShareMemory();
byte to_write = 0b01010101;
long startTime;
long endTime;
// test random write
startTime = System.currentTimeMillis();
for (int i = 0; i <1000000000; i++) {
int pos = rand.nextInt(sm.mapSize);
sm.mapBuf.position(pos);
sm.mapBuf.get(sm.buff, 0, 1);
sm.buff[0] = to_write;
sm.mapBuf.position(pos);
sm.mapBuf.put(sm.buff, 0, 1);
}
endTime = System.currentTimeMillis();
System.out.println("test random write cost: " + (endTime - startTime) + "ms");
// test set zero
startTime = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
sm.reset();
}
endTime = System.currentTimeMillis();
System.out.println("test set zero cost: " + (endTime - startTime) + "ms");
}
}