Sensitive word filtering is a technical means to prevent cyber crime and cyber violence developed with the development of Internet community. By screening and screening the possible keywords of cyber crime or cyber violence, we can prevent them from happening in the future and stifle the serious consequences of crime in the budding.
With the popularity of various social platforms, sensitive word filtering has gradually become a very important and important function.So what are the new implementations of Sensitive Word Filtering in Serverless with Python?Can we implement an API for sensitive word filtering in the simplest way?
Understanding Several Methods of Sensitive Filtering
Replace method
If we say sensitive word filtering, it's not really text replacement. Take Python for example, when it comes to word replacement, we have to think of replace. We can prepare a sensitive lexicon and replace it with replace:
def worldFilter(keywords, text): for eve in keywords: text = text.replace(eve, "***") return text keywords = ("Keyword 1", "Keyword 2", "Keyword 3") content = "This is an example of keyword substitution, involving keyword 1, keyword 2, and finally keyword 3." print(worldFilter(keywords, content))
But if you think about it, you will find that this method has serious performance problems when the text and sensitive lexicon are very large.For example, I'll modify the code to perform basic performance tests:
import time def worldFilter(keywords, text): for eve in keywords: text = text.replace(eve, "***") return text keywords =[ "Key word" + str(i) for i in range(0,10000)] content = "This is an example of keyword substitution, involving keyword 1, keyword 2, and finally keyword 3." * 1000 startTime = time.time() worldFilter(keywords, content) print(time.time()-startTime)
The output at this point is 0.12426114082336426, and you can see that the performance is very poor.
Regular expression
Rather than using replace, it is faster to regularly express re.sub.
import time import re def worldFilter(keywords, text): return re.sub("|".join(keywords), "***", text) keywords =[ "Key word" + str(i) for i in range(0,10000)] content = "This is an example of keyword substitution, involving keyword 1, keyword 2, and finally keyword 3." * 1000 startTime = time.time() worldFilter(keywords, content) print(time.time()-startTime)
We also added performance tests, following the above method of transformation testing, the output result is 0.24773502349853516.Through such an example, we can find that its performance is not great, but as the amount of text increases, the performance of regular expression will be much higher.
DFA Filter Sensitive Words
This method is relatively more efficient.For example, if we think bad people, bad children and bad people are sensitive words, their tree relationships can be expressed:
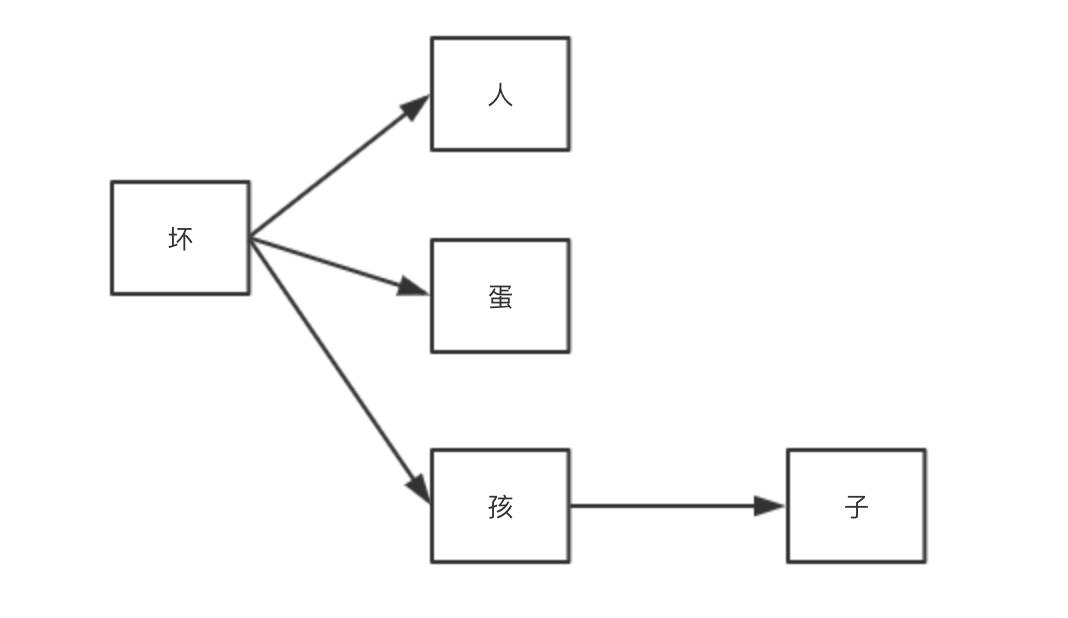
Expressed in a DFA dictionary:
{ 'bad': { 'egg': { '\x00': 0 }, 'people': { '\x00': 0 }, 'Child': { 'son': { '\x00': 0 } } } }
The best benefit of using this tree to represent a problem is to reduce the number of retrievals, improve the efficiency of retrieval, and implement basic code:
import time class DFAFilter(object): def __init__(self): self.keyword_chains = {} # Keyword Chain List self.delimit = '\x00' # limit def parse(self, path): with open(path, encoding='utf-8') as f: for keyword in f: chars = str(keyword).strip().lower() # Keyword English becomes lowercase if not chars: # Return directly if the keyword is empty return level = self.keyword_chains for i in range(len(chars)): if chars[i] in level: level = level[chars[i]] else: if not isinstance(level, dict): break for j in range(i, len(chars)): level[chars[j]] = {} last_level, last_char = level, chars[j] level = level[chars[j]] last_level[last_char] = {self.delimit: 0} break if i == len(chars) - 1: level[self.delimit] = 0 def filter(self, message, repl="*"): message = message.lower() ret = [] start = 0 while start < len(message): level = self.keyword_chains step_ins = 0 for char in message[start:]: if char in level: step_ins += 1 if self.delimit not in level[char]: level = level[char] else: ret.append(repl * step_ins) start += step_ins - 1 break else: ret.append(message[start]) break else: ret.append(message[start]) start += 1 return ''.join(ret) gfw = DFAFilter() gfw.parse( "./sensitive_words") content = "This is an example of keyword substitution, involving keyword 1, keyword 2, and finally keyword 3." * 1000 startTime = time.time() result = gfw.filter(content) print(time.time()-startTime)
Here our dictionary library is:
with open("./sensitive_words", 'w') as f: f.write("\n".join( [ "Key word" + str(i) for i in range(0,10000)]))
Execution results:
0.06450581550598145
You can see further performance improvements.
AC Automation Filter Sensitive Words Algorithm
Next, let's take a look at the AC Automation Filter Sensitive Words algorithm:
AC Automation: A common example is to give n words and then an article containing m characters to find out how many words have appeared in the article.
Simply put, an AC automaton is a dictionary tree + kmp algorithm + mismatched pointer
Code implementation:
import time class Node(object): def __init__(self): self.next = {} self.fail = None self.isWord = False self.word = "" class AcAutomation(object): def __init__(self): self.root = Node() # Find Sensitive Word Function def search(self, content): p = self.root result = [] currentposition = 0 while currentposition < len(content): word = content[currentposition] while word in p.next == False and p != self.root: p = p.fail if word in p.next: p = p.next[word] else: p = self.root if p.isWord: result.append(p.word) p = self.root currentposition += 1 return result # Load Sensitive Lexicon Function def parse(self, path): with open(path, encoding='utf-8') as f: for keyword in f: temp_root = self.root for char in str(keyword).strip(): if char not in temp_root.next: temp_root.next[char] = Node() temp_root = temp_root.next[char] temp_root.isWord = True temp_root.word = str(keyword).strip() # Sensitive Word Substitution Function def wordsFilter(self, text): """ :param ah: AC automata :param text: text :return: Filter text after sensitive words """ result = list(set(self.search(text))) for x in result: m = text.replace(x, '*' * len(x)) text = m return text acAutomation = AcAutomation() acAutomation.parse('./sensitive_words') startTime = time.time() print(acAutomation.wordsFilter("This is an example of keyword substitution, involving keyword 1, keyword 2, and finally keyword 3."*1000)) print(time.time()-startTime)
The lexicon is the same:
with open("./sensitive_words", 'w') as f: f.write("\n".join( [ "Key word" + str(i) for i in range(0,10000)]))
Using the above method, the test result is 0.017391204833984375.
Summary of Sensitive Word Filtering Methods
You can see that among all the above basic algorithms, DFA filter sensitive words has the highest performance, but in fact, no one is better for the latter two algorithms. Perhaps sometimes, AC automatic filter sensitive words algorithm will get better performance, so in the production life, it is recommended to use both algorithms, which can be done according to your specific business needs.
Implement Sensitive Word Filtering API
Deploying code to the Serverless architecture allows you to choose an API gateway to combine with function calculation, taking the AC Automation Filter Sensitive Words algorithm as an example: We only need to add a few lines of code, the complete code is as follows:
# -*- coding:utf-8 -*- import json, uuid class Node(object): def __init__(self): self.next = {} self.fail = None self.isWord = False self.word = "" class AcAutomation(object): def __init__(self): self.root = Node() # Find Sensitive Word Function def search(self, content): p = self.root result = [] currentposition = 0 while currentposition < len(content): word = content[currentposition] while word in p.next == False and p != self.root: p = p.fail if word in p.next: p = p.next[word] else: p = self.root if p.isWord: result.append(p.word) p = self.root currentposition += 1 return result # Load Sensitive Lexicon Function def parse(self, path): with open(path, encoding='utf-8') as f: for keyword in f: temp_root = self.root for char in str(keyword).strip(): if char not in temp_root.next: temp_root.next[char] = Node() temp_root = temp_root.next[char] temp_root.isWord = True temp_root.word = str(keyword).strip() # Sensitive Word Substitution Function def wordsFilter(self, text): """ :param ah: AC automata :param text: text :return: Filter text after sensitive words """ result = list(set(self.search(text))) for x in result: m = text.replace(x, '*' * len(x)) text = m return text def response(msg, error=False): return_data = { "uuid": str(uuid.uuid1()), "error": error, "message": msg } print(return_data) return return_data acAutomation = AcAutomation() path = './sensitive_words' acAutomation.parse(path) def main_handler(event, context): try: sourceContent = json.loads(event["body"])["content"] return response({ "sourceContent": sourceContent, "filtedContent": acAutomation.wordsFilter(sourceContent) }) except Exception as e: return response(str(e), True)
Finally, to facilitate local testing, we can add:
def test(): event = { "requestContext": { "serviceId": "service-f94sy04v", "path": "/test/{path}", "httpMethod": "POST", "requestId": "c6af9ac6-7b61-11e6-9a41-93e8deadbeef", "identity": { "secretId": "abdcdxxxxxxxsdfs" }, "sourceIp": "14.17.22.34", "stage": "release" }, "headers": { "Accept-Language": "en-US,en,cn", "Accept": "text/html,application/xml,application/json", "Host": "service-3ei3tii4-251000691.ap-guangzhou.apigateway.myqloud.com", "User-Agent": "User Agent String" }, "body": "{\"content\":\"This is a test text, so I will.\"}", "pathParameters": { "path": "value" }, "queryStringParameters": { "foo": "bar" }, "headerParameters": { "Refer": "10.0.2.14" }, "stageVariables": { "stage": "release" }, "path": "/test/value", "queryString": { "foo": "bar", "bob": "alice" }, "httpMethod": "POST" } print(main_handler(event, None)) if __name__ == "__main__": test()
Once we've finished, we can test and run it, for example, my dictionary is:
Ha-ha test
Results after execution:
{'uuid': '9961ae2a-5cfc-11ea-a7c2-acde48001122', 'error': False, 'message': {'sourceContent': 'This is a test text, so I will.', 'filtedContent': 'This is a**Text, so do I**Yes'}}
Next, we deploy the code to the cloud and create a new serverless.yaml:
sensitive_word_filtering: component: "@serverless/tencent-scf" inputs: name: sensitive_word_filtering codeUri: ./ exclude: - .gitignore - .git/** - .serverless - .env handler: index.main_handler runtime: Python3.6 region: ap-beijing description: Sensitive Word Filtering memorySize: 64 timeout: 2 events: - apigw: name: serverless parameters: environment: release endpoints: - path: /sensitive_word_filtering description: Sensitive Word Filtering method: POST enableCORS: true param: - name: content position: BODY required: 'FALSE' type: string desc: Sentences to be filtered
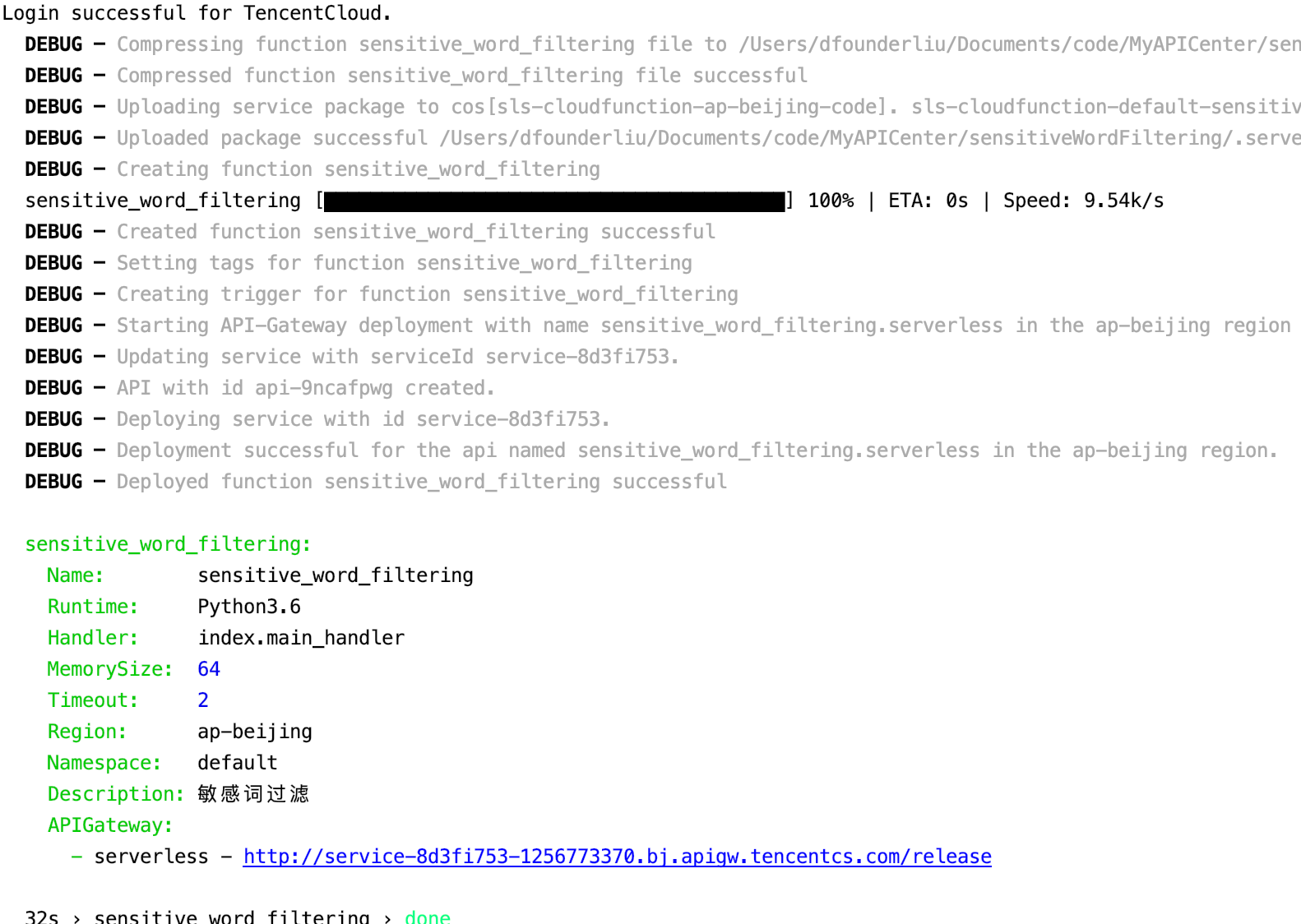
Then deploy through sls --debug, deploying the result:
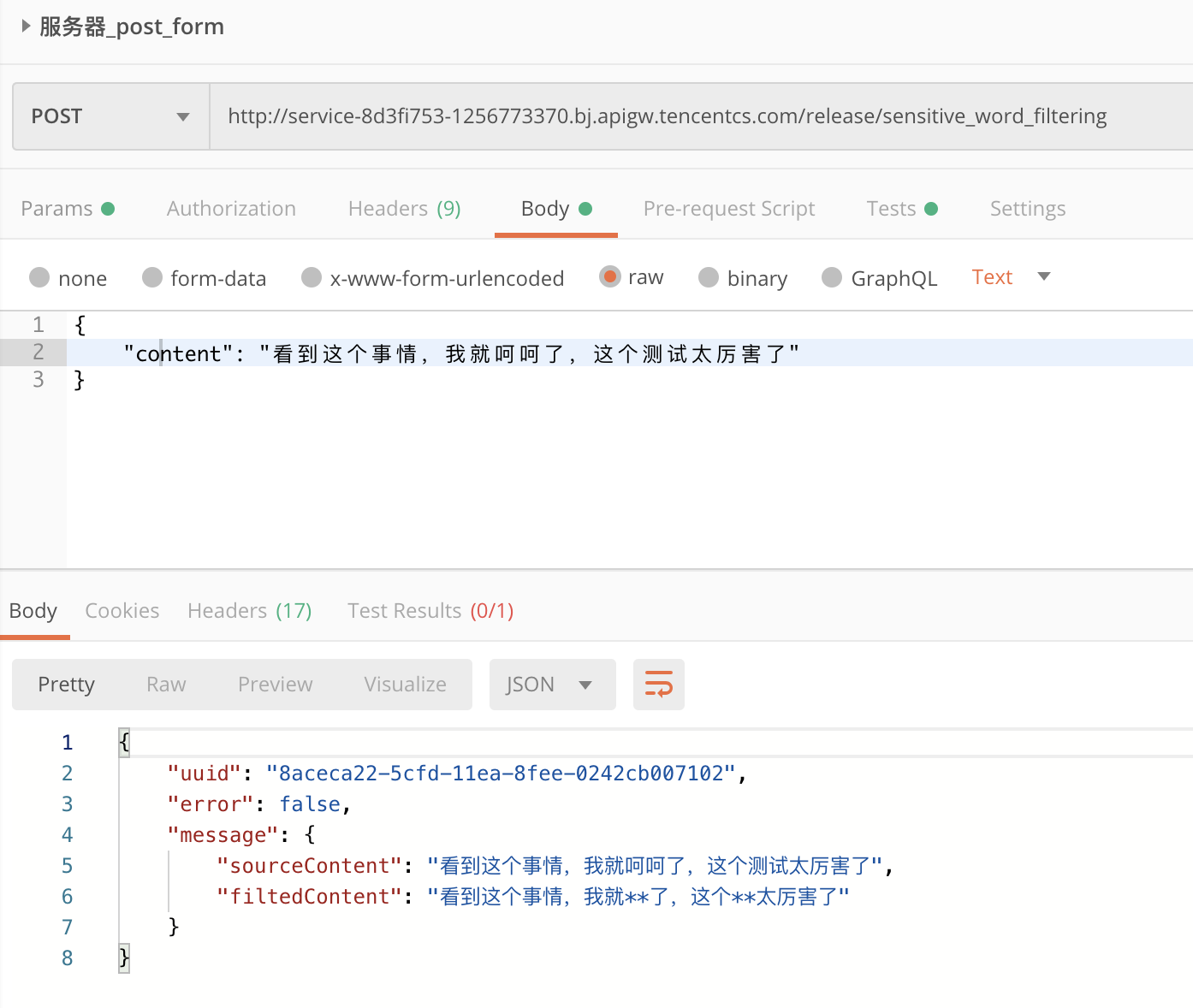
Finally, test with PostMan:
summary
Sensitive word filtering is a very common requirement/technology at present. By using sensitive word filtering, we can reduce the appearance of malicious or illegal speech to a certain extent. In the above practice process, there are two points:
- For the sensitive lexicon size issue: There are many on Github, you can search and download by yourself, because there are many sensitive words in the sensitive lexicon, so I can not put them directly on this for everyone to use, so you also need to search and use them on Github by yourself;
- Problem with this API usage scenario: It can be completely placed in our community posting system/commenting system/blog publishing system to prevent sensitive vocabulary and reduce unnecessary hassles.
Serverless Framework 30-day Trial Plan
We invite you to experience the most convenient way to develop and deploy Serverless.During the trial period, the associated products and services provide free resources and professional technical support to help your business achieve Serverless quickly and easily!
Details are available: Serverless Framework Trial Plan
One More Thing
What can you do in 3 seconds?Have a drink of water, see an email, or - deploy a complete Serverless Apply?
Copy Link to PC Browser Access: https://serverless.cloud.tencent.com/deploy/express
Fast deployment in 3 seconds for the fastest ever experience Serverless HTTP Actual development!
Port:
- GitHub: github.com/serverless
- Official website: serverless.com
Welcome to: Serverless Chinese Network , you can Best Practices Experience more development of Serverless apps here!
Recommended reading: Serverless Architecture: From Principles, Design to Project Practice