Thread Basics
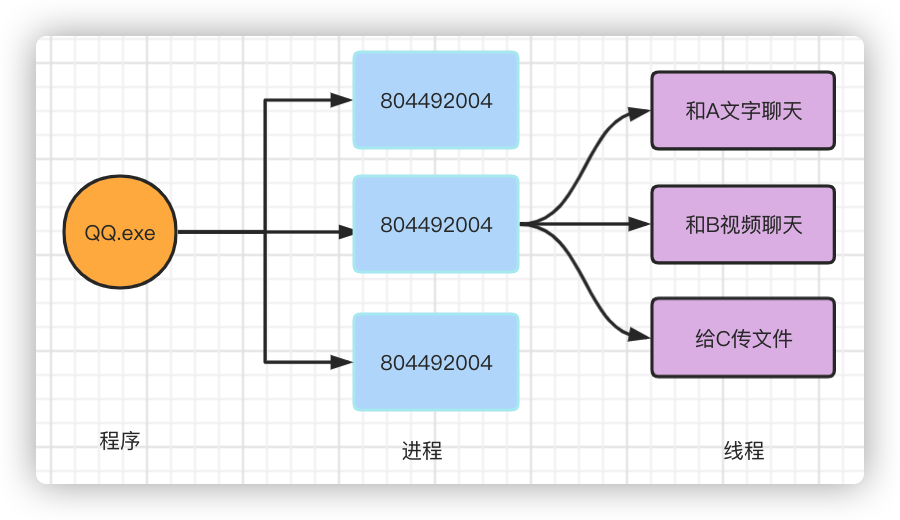
Programs, Processes, Threads, Fibers (Programs)
-
Program: The.exe executable that was initially lying quietly on disk, load ed into memory by the system when we clicked Run, and executed by the cpu
-
Processes: The basic unit for operating system resource allocation. (A program can be run by multiple processes, such as a computer can log in to multiple qq s, which are multiple processes.)
-
Threads: The basic unit for dispatching execution. Threads are different execution paths within a program, and multiple threads share resources in the same process.
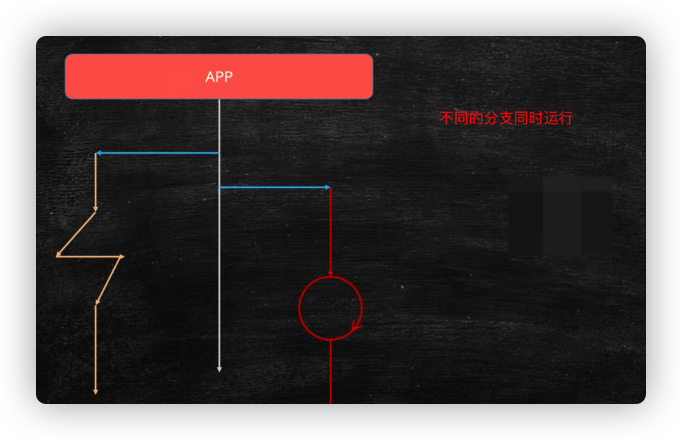
Fiber (protocol)
Fibers and threads essentially work the same way. Threads switch through stacks, and so do fibers, which are records and switches of stacks. Fibers are threads in user space.
Threads are managed by the operating system kernel (in the kernel state), and collaborations are controlled by programs (in the user state)
Difference:
- Thread switching takes place through kernel space, and fiber switching takes place through user space. Thread switching takes place through the kernel stack, and process switching takes place through the user stack. No thread switching is expensive for a process.
- Fibers can start much more than threads
The benefit of using fibers is to simplify thread switching
When to recommend using a protocol: In a large number of short-term operations, we use a protocol to replace threads, which works best, first reduces system memory, second reduces system switching overhead, and improves system performance
Use of Fibers in Java
JVM does not support fibers, Java needs to use fibers through the external library: Quaser Fiber Library
Vernacular Interpreter Process Threads
-
For example, when using Intelligent Idea programs, the entire idea that is started is a process, the entire process of the idea has a grammar check thread, and the code intelligently prompts the thread.
-
JDK has compilation threads in one process, garbage auto-collection threads
-
With QQ, there must be a process of QQexe to view the process. I can chat with Qq and A, with B video, pass files to C, send a language to D, and QQ supports the search of input information.
-
When I was in my senior year, I wrote papers with word, played music with QQ music, and chatted with QQ. This is a multi-process.
-
word can restore previously unsaved documents if it is not saved, shut down after power failure, and open word after power failure. word also checks your spelling. There are two threads: Disaster Tolerance Backup, Grammar Check
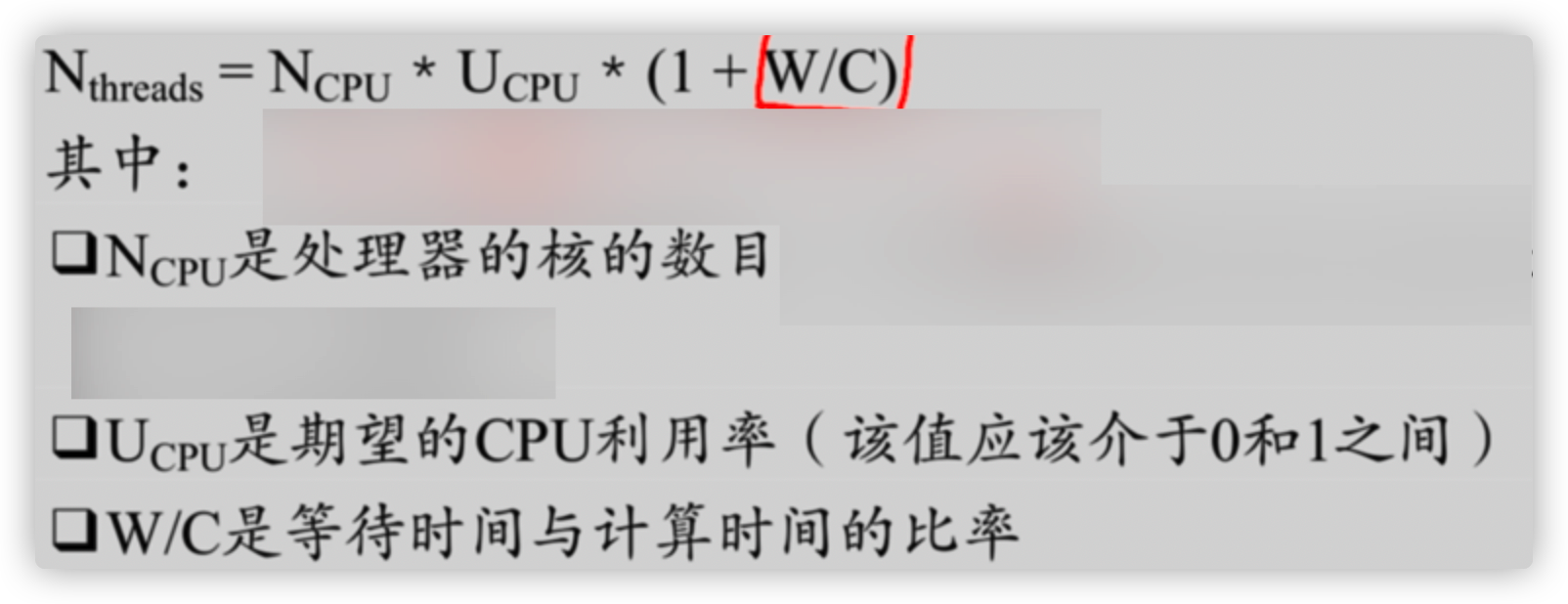
Is more worker threads better or less appropriate
Work threads are not as many as possible, because switching threads consumes system resources
How many threads are appropriate depends on the machine configuration, the number of processor cores, the combination of formulas, and a strong pressure test.
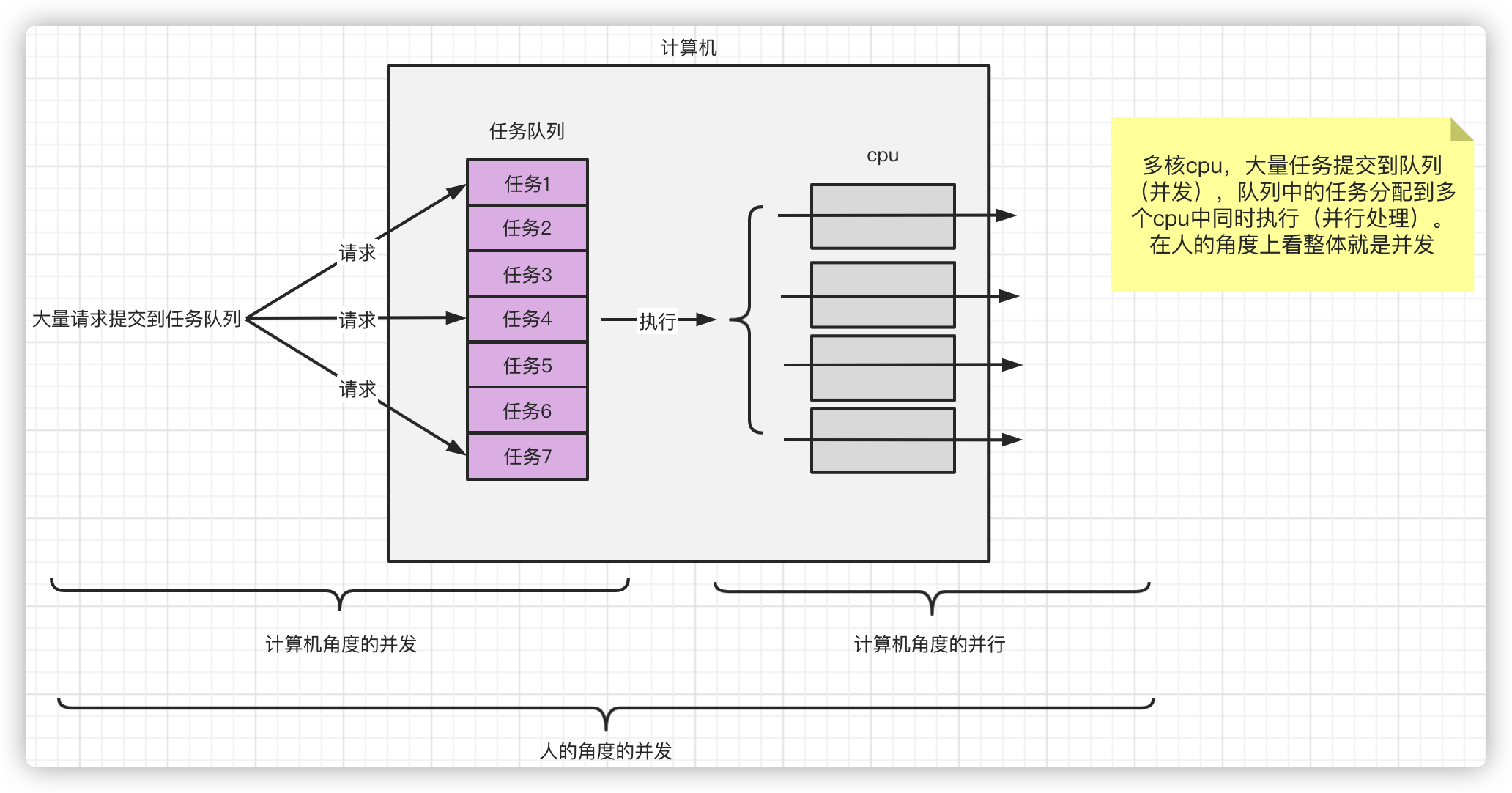
Concurrent concurrent and parallel
Concurrency refers to the submission of tasks, and concurrency refers to the execution of tasks.
Parallelism is a subset of concurrency.
From a human perspective, a bunch of tasks are submitted together and the machine can execute them at the same time. But from a computer perspective, concurrency means that many tasks are submitted at the same time. Ultimately, tasks are executed by multiple CPUs in parallel.
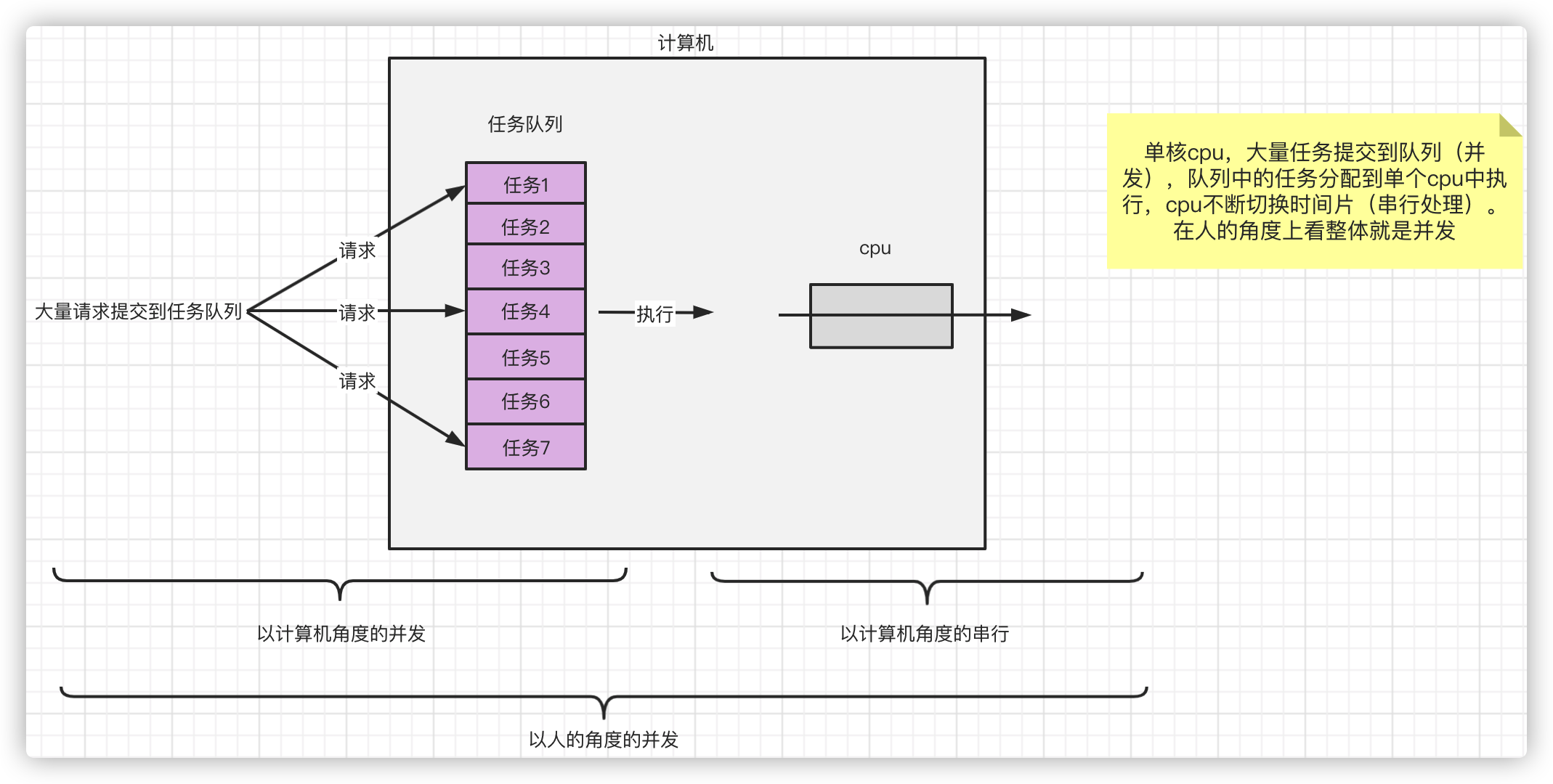
Introduction to Locks
The essence of a lock is not a lock on operating system resources, but which thread gets the lock and holds the lock
The object header contains 8 bits (64bit), where 2 bits represent the state of the lock
synchornized
A brief introduction to synchornized
synchronized guarantees both atomicity and visibility
Exception locks will be released in the program
A synchronized decorated code block or method automatically releases the lock when execution ends
Synchronized static void m() ==> class lock, equivalent to T.class
Synchronized void m() ==> object lock, equivalent to this
synchornized lock object must have final
For example, synchornized(o) {} must have final Object o = new Object();Because if one object is not final, the lock will become invalid when another thread changes the o lock. (The flag bits of the lock in the object header will be lost when the object is changed)
String type cannot be used as lock
Because of the character of the string constant pool: the same string is the same object. If a String is used as a lock, it is likely that synchronous code in different classes will hold the same lock
Reentrant of synchornized lock
There are two synchronized methods, with the same lock, which can be called from one thread to another
synchronized void m1(){
m2();
}
synchronized void m2(){
}
m1 calls m2, and when M2 is executed, the same lock is found and the same object is locked, no further locks are needed
Refinement of synchornized locks
Sometimes there is no need to lock on a method because there may be a lot of execution logic on a method and the granularity of the lock on the method is too large. Sometimes there is no need to synchronize the whole method. For locking, the code can lock as little as possible. So you can optimize the lock more finely by adding a synchronization code block to the method.
synchornized Lock Upgrade
Early synchronized was heavy, and any synchronized setting was a heavy system lock. It was inefficient (before JDK1.5).
The synchronized improvements followed by lock upgrade mechanisms
- Lockless state
- When the first thread accesses a resource, it has a bias lock, a thread ID marked on the object header, and a thread-only record object. The next time the first thread accesses the object, it will be biased toward the first thread (it's not really a lock, it's just a flag bit set!) --- biased lock
- Later threads visit and find that the thread ID and the first thread are not equal, that is, the lock is upgraded to a spin lock. --- Spin lock
- Upgrade to heavy lock when a thread spins more than 10 times

Note: Lock cannot be downgraded after upgrading
The reason for this lock upgrade is:
- Most of the time, there is no lock competition, and often a thread acquires the same lock multiple times, so competing for a lock each time increases the unnecessary cost by introducing a biased lock to reduce the cost of acquiring a lock.
- A spin lock does not access the operating system. It is user state and does not access the kernel state. It improves response speed. Therefore, a spin lock is introduced.
When to use a spin lock and when to use a heavy lock
Threads take an especially long time to execute and heavy locks are recommended.
Threads have a short execution time and a small number of threads. Spin locks are recommended. --- Because spin locks switch quickly based on user state, fewer threads with spin locks do not waste CPU resources.
Volatile
- Ensure orderliness of instructions
- Ensure visibility between threads
- Atomicity is not guaranteed
See JVM Notes
ReentraintLock
Both synchornized and Lock are re-lockable
Attempting to lock using tryLock requires a specified time, after which the method will continue executing regardless of whether the lock is locked or not
The return value of tryLock can be used to determine whether a lock is present.
You can also specify a time for tryLock, since tryLock(time) throws exceptions, be aware that unclock processing must be placed in finally to unlock
The difference between synchronized and Lock
- Lock is based on CAS and AQS, and Synchornized has a lock upgrade process.
- Lock can use tryLock to determine if it has acquired a lock
- Lock can be interrupted by interrupt while competing for locks
- synchornized is an unfair lock, Lock achieves fairness and unfairness
- The synchronized system automatically releases locks (which are automatically released when a program completes execution or an exception occurs), Lock needs to be manually locked, and unlock() is used in finally to manually unlock
Fair and unfair locks
There is a waiting queue at the bottom of a fair lock. When a thread comes in, it checks to see if there is a waiting queue. If there is a waiting queue, it is a fair lock, and queues obligingly. If there is no waiting queue, it is an unfair lock, and it is possible to get a lock directly.
ReentrantLock lock = new ReentrantLock(true); //The parameter true denotes a fair lock. Compare the output
CountDownLatch
CountDownLatch has a numeric parameter. Threads counted by countDown() execute first, then by calling await().
Be careful:
- countDown() and await() must be used together.
- And the number of countDown s must be equal to the number of threads, otherwise subsequent threads cannot execute
public class CloseDoorDemo {
public static void main(String[] args) {
Thread[] threads = new Thread[100];
CountDownLatch countDownLatch = new CountDownLatch(threads.length);
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
System.out.println("the student number of " + Thread.currentThread().getName() + " left the classroom");
countDownLatch.countDown();
}, String.valueOf(i + 1));
}
// Guaranteed that students will close the door before they leave. guaranteed that main method will be followed by execution
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("the classmate open the door last");
}
}
public class TestCountDownLatch {
public static void main(String[] args) {
usingCountDownLatch();
usingJoin();
}
private static void usingCountDownLatch() {
Thread[] threads = new Thread[10];
CountDownLatch latch = new CountDownLatch(threads.length);
Lock lock = new ReentrantLock(true);
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
try {
lock.lock();
int result = 0;
System.out.println(Thread.currentThread().getName() + "\t" + result);
latch.countDown();
} finally {
lock.unlock();
}
});
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("end latch");
}
private static void usingJoin() {
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
int result = 0;
System.out.println(Thread.currentThread().getName() + "\t" + result);
}, "thread" + i);
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
// Add a join for each thread in the main method so that the threads execute before the main method
for (int i = 0; i < threads.length; i++) {
try {
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("end join");
}
}
CyclicBarrier
Principle: CyclicBarrier literally means a barrier (Barrier) used by Cyclic. What it does is get a set of threads to a barrier (also known as a synchronization point)The barrier is blocked until the last thread reaches the barrier, and all the threads blocked by the barrier continue to work. Threads enter the barrier and pass through the CyclicBarrier's await() method.
public class TestCyclicBarrier {
public static void main(String[] args) {
//CyclicBarrier barrier = new CyclicBarrier(20);
CyclicBarrier barrier = new CyclicBarrier(20, () -> {
System.out.println("Full, depart");
});
for (int i = 0; i < 100; i++) {
new Thread(() -> {
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
}
ReadWriteLock
-
Read Lock - Shared Lock
If a read thread is reading data, it can read to other read threads. The write thread does not give
-
Write Lock - Exclusive Lock
The first write thread will lock the resource when it comes in, and neither the other read nor write threads will give it
Ultimate goal: read-write separation
class MyCache {
private volatile Map<String, Object> map = new HashMap<>();
private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
public void put(String key, Object value) {
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\tstart to write~~~");
SleepHelper.sleep(1);
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "\tend write~~~");
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.writeLock().unlock();
}
}
public void get(String key) {
readWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\tstart read~~~");
Object result = map.get(key);
System.out.println(Thread.currentThread().getName() + "\tread end~~~" + result);
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.readLock().unlock();
}
}
}
public class ReadWriteDemo {
public static void main(String[] args) {
MyCache myCache = new MyCache();
for (int i = 1; i <= 5; i++) {
final int tempInt = i;
new Thread(() -> {
myCache.put(String.valueOf(tempInt), Thread.currentThread().getName());
}, String.valueOf(i)).start();
}
for (int i = 1; i <= 5; i++) {
final int tempInt = i;
new Thread(() -> {
myCache.get(String.valueOf(tempInt));
}, String.valueOf(i)).start();
}
}
}
The bottom level of ReentraintLock is based on volatile state + AQS + CAS
LockSupport
There are two ways:
- park(): Blocks the thread
- Unpark (Thread thread): unblock the specified thread
Semaphore
Mainly used for flow-limiting operations to limit how many threads can run simultaneously
- acquire signal, the number of incoming signals per thread + 1 until the number set by itself is added. The following threads do not execute. Wait for these threads to finish executing
- Release signal. Threads that do not release subsequent batches will not execute
public class SemaphoreDemo {
public static void main(String[] args) {
// Allow up to five threads to execute simultaneously
Semaphore semaphore = new Semaphore(5, true);
for (int i = 0; i < 10; i++) {
new Thread(()->{
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + " is Running.....");
SleepHelper.sleep(2);
System.out.println(Thread.currentThread().getName() + " is end.....");
} catch (Exception e) {
e.printStackTrace();
} finally {
semaphore.release();
}
},"thread" + i).start();
}
}
}
Spin lock
Later introduced with CAS
Seven states of a thread
Three ways to control thread state
sleep
Thread is in TIMED WAITING state after sleep (lock will not be released)
yield
Essentially, you let the cpu execute for other threads, which are running -> read ready. You don't care what happens next (you won't release the lock)
join
After t2.join() occurs in the t1 thread, the t1 thread becomes Waiting, and the thread T2 executes. After the thread T2 executes, the previous thread t1 executes (releases the lock because the underlying layer is wait and the wait releases the lock).
wait/notify
The first three are methods in the Thread class, while wait/notify is a method in the Object class that controls the thread holding the object lock to wait and notify other threads.
Note: wait() releases the current object lock, but notify() only notifies other threads to wake up without releasing the lock
Interview Question: How to ensure the execution order of threads?
Method 1: Call t1.join(), t2.join(), and t3.join(), respectively, in the main method
Method 2:t2 calls t1.join(), and t3 calls t2.join()
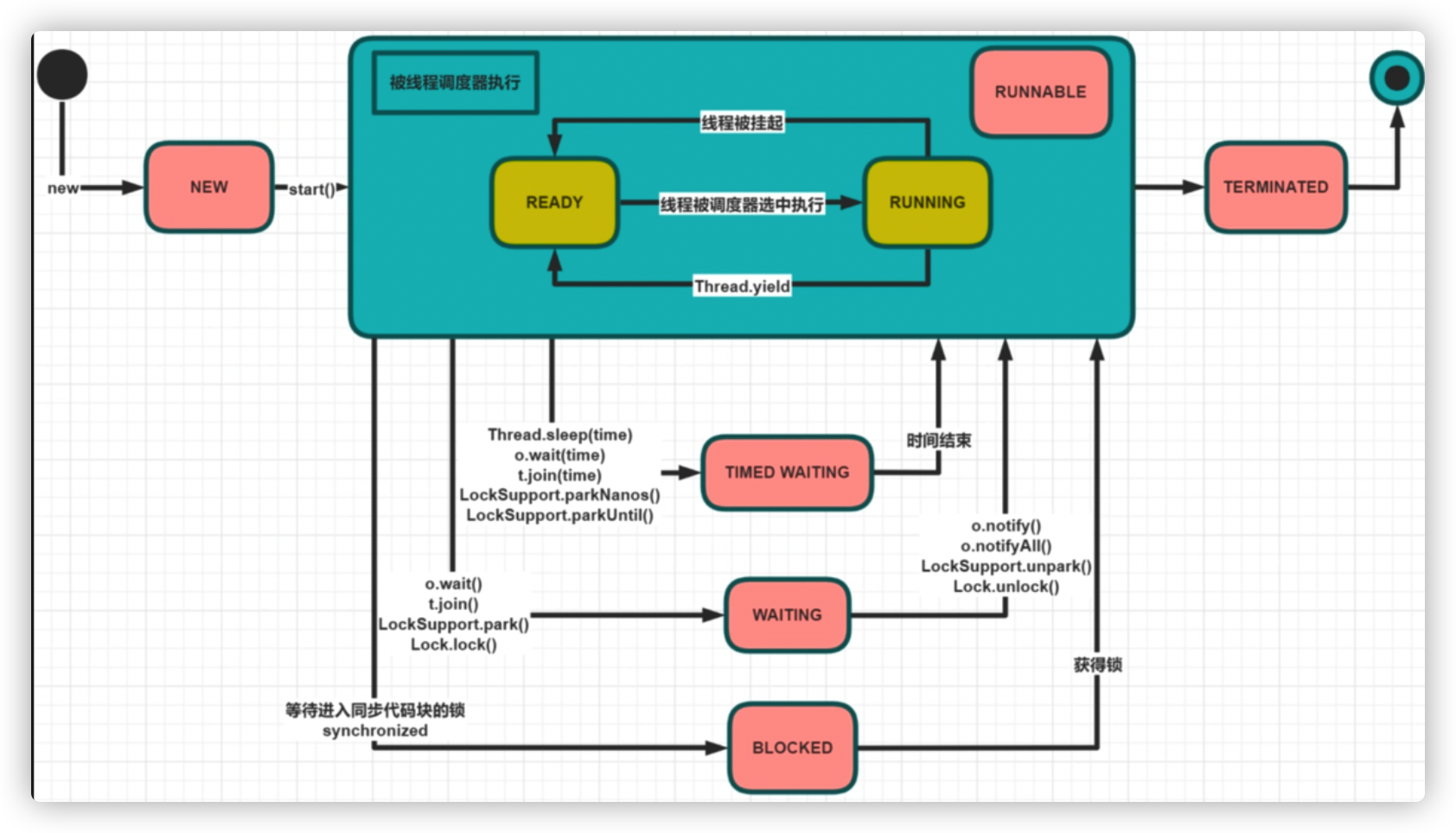
- Thread Ready: Threads are dropped into the waiting queue of the CPU
- After the thread terminated, it can no longer start
- block status: Threads are blocked while waiting to acquire synchronized locks, and others are blocked. Synchronized is scheduled by the operating system, and blocked is only scheduled by the operating system
- timedwaiting: A specified wait time, such as sleep
Differences between sleep and wait
- sleep belongs to the Thread class; wait belongs to the Object class
- The sleep does not release the lock and resumes after the specified wait time. The wait releases the lock and must wake up through notify
- sleep can be called in both synchronous and asynchronous states, wait can only be called in synchronous code
How threads are created
-
Inherit Thread Class
-
Implement Runnable Interface
Variant: Use lambda expression - >, commonly used
-
Implement callable with return value. Used with FutureTask
public static void main(String[] args) throws Exception { FutureTask<String> futureTask = new FutureTask<>(() -> { System.out.println(Thread.currentThread().getName() + "----------Implements Callable,use lambda..........."); return "callable"; }); new Thread(futureTask, "lambdaCallable").start(); System.out.println("Acquired Callable In interface call The return value of the method is:" + futureTask.get()); } -
Thread Pool
public static void main(String[] args) throws Exception { //================================The way ordinary thread pools work================= ExecutorService executorService = Executors.newFixedThreadPool(10); for (int i = 0; i < 10; i++) { executorService.execute(() -> { System.out.println(Thread.currentThread().getName() + "----------use ThreadPool..........."); }); } //=====================Thread pool combined with FutureTask, Callable use=============== FutureTask<String> futureTask1 = new FutureTask<>(() -> { System.out.println(Thread.currentThread().getName() + "----------Use Callable In ThreadPool..........."); return "callableInThreadPool"; }); executorService.execute(futureTask1); System.out.println(futureTask1.get()); executorService.shutdown(); }
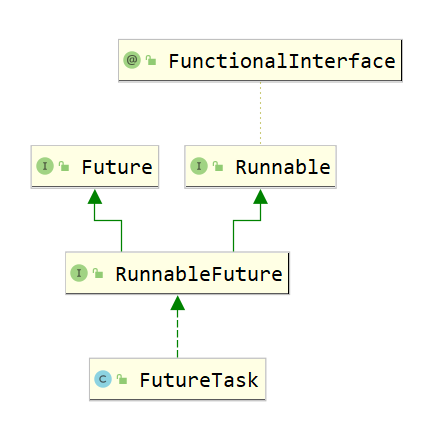
Interview question: What is the difference between the callable interface and the runnable interface?
Answer: (1) Is there a return value
(2) Whether to throw an exception
(3) The landing methods are different, one is run, the other is call.
Ultimately, it's essentially a way for new to create a Thread() object and then call start().
Method to Stop Threads
-
stop( ) :
Abandoned, not recommended. Thread stop s do not roll back to their original state due to data inconsistencies
-
suspend() suspend thread with resume() resume thread:
Not recommended, pausing a thread locks it, and if you forget to restore it, it will lock it forever
-
Use volatile keyword to control flag bits
Controlled by public static volatile boolean running = true. It is possible not to rely on an explicit state of neutral execution.
public class ThreadInterrupt { public static volatile boolean RUNNING = true; public static void main(String[] args) { Thread t1 = new Thread(() -> { System.out.println("thread is start"); while (RUNNING) { } System.out.println("thread is end"); }, "thread1"); t1.start(); SleepHelper.sleep(3); RUNNING = false; } } -
Setting flags using interrupt
public class ThreadInterrupt { public static void main(String[] args) { Thread t1 = new Thread(() -> { System.out.println("thread is start"); while (!Thread.currentThread().isInterrupted()) { // Query if the thread is interrupted } System.out.println("thread is end"); }, "thread1"); t1.start(); SleepHelper.sleep(3); t1.interrupt(); } }The difference between volatile and volatile: volatile is a marker we set manually, interrupt is the system's own marker, interrupt is more elegant
CAS
CAS is an implementation of optimistic locking, a lightweight lock, and the implementation of many tool classes in JUC is based on CAS.
There are many classes that use CAS at the bottom, CAS is lock-free optimization.
CAS Principle
Threads do not lock when reading data. When preparing to write back data, they query the original value first, compare whether the original value is modified during operation, write back if it is not modified by other threads, and re-execute the reading process if it has been modified. This is lock-free optimization.
Understanding CAS through database operations
Take the database operation as an example: modify the data name in a database, first find the name = "handsome group", get the value and then modify it. Before modifying, judge if it is "handsome group"? If it is not "handsome group", the description has been modified by other threads, the modification failed. If it is "handsome group", change it to "Zexi".
Note: The above is just an analogy of CAS through mysql operation. In fact, comparing + updating in CAS is an atomic operation supported by CPU primitive
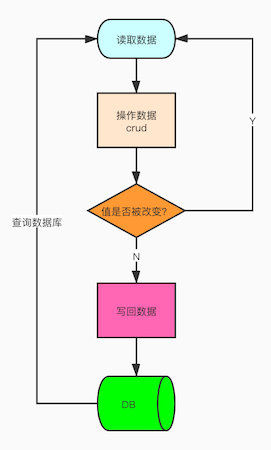
Principle of CAS in Java
Three basic operands are used in the CAS mechanism: the memory address V, the old expected value A, and the new value B to be modified.
When updating A variable, the value corresponding to the memory address V will only be changed to B if the expected value of the variable and the actual value of the memory address V are the same.
When you modify a value, it changes to a new value when you find that the expected value is the same as the value in the modified memory address; if the expected value is different from the value in the modified memory address, the value has been modified by another thread, and the thread failed to modify the value.
For example, change a number from 1 to 2, and before changing, see if 1, 1 is the expected value
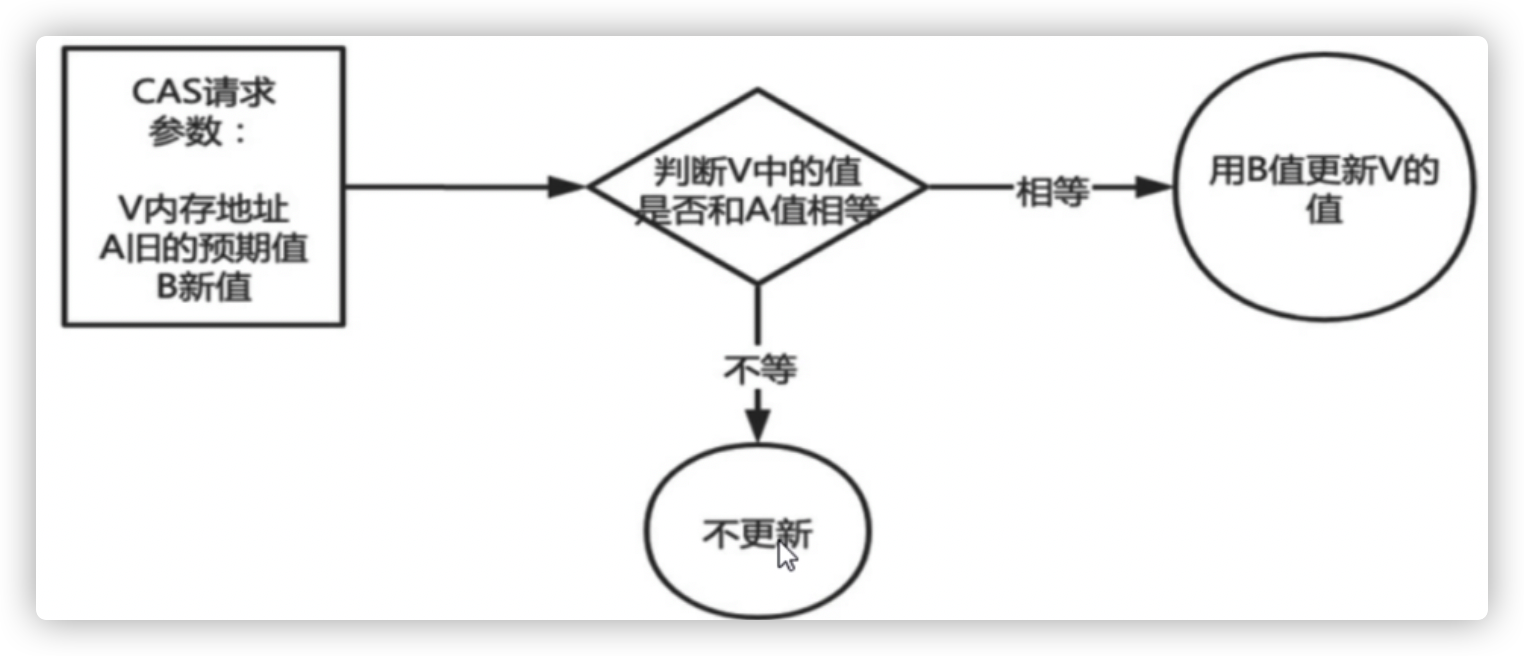
CAS example: AtomicInteger
AtomicInger is a common atomic class that supports concurrent modification of values. It is implemented internally based on CAS. With it, concurrent modification of values does not require a synchornized lock, which speeds up the response.
incrementAndGet() method call graph in AtomicInger
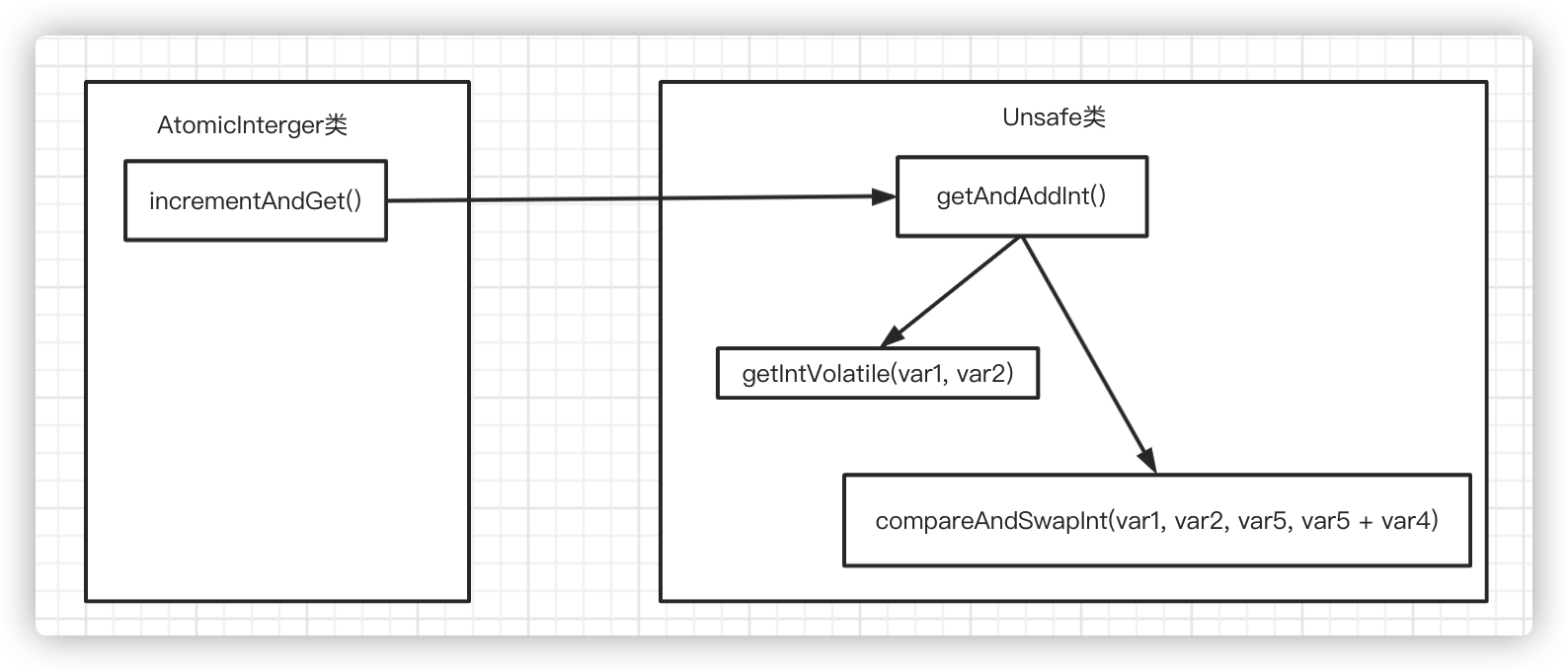
AtomicInteger Code
// AtomicInteger-------------------
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
// Unsafe class---------------------------------
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
// Cyclic judgment (spin) if the value to be modified is not equal to the expected value
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
// The first parameter is the object that needs to be changed, and the second parameter is the offset
public native int getIntVolatile(Object var1, long var2);
// The first parameter is the object that needs to be changed, the second parameter is the offset, the third parameter is the expected value, and the fourth parameter is the updated value
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
Note: Judgment and modification are atomic operations, supported by the cpu source language
Spin lock
The spin lock is not a physical lock, but a logical lock. It is based on the CAS feature. It enters a deadlock through the CAS feature, and ultimately must be compared and exchanged successfully before exiting. The deadlock process is logically locked.
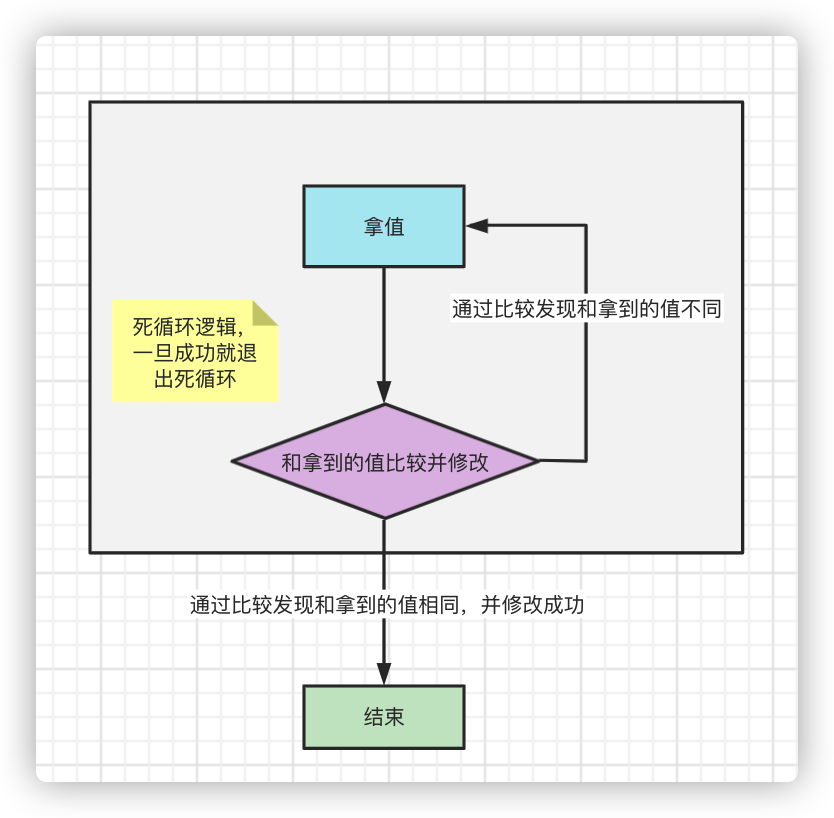
Spin operation: take value + compare value and judge (atom)
The spin operation is achieved by CAS mechanism + dead-cycle judgment.
This is how spin locks work, allowing thread safety
When to use a spin lock and when to use a heavy lock
Threads take an especially long time to execute and heavy locks are recommended.
Thread execution time is short, but the number of threads cannot be too large. Spin locks are recommended because spin operations consume cpu resources
Make your own handwritten lock
public class MyLockDemo {
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public static volatile int count = 0;
public void myLock(){
Thread thread = Thread.currentThread();
while (!atomicReference.compareAndSet(null,thread)){
}
}
public void myUnlock(){
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread,null);
}
public static void main(String[] args) {
MyLockDemo spinLockDemo = new MyLockDemo();
for (int i = 0; i < 100; i++) {
new Thread(()->{
for (int j = 0; j < 10000; j++) {
spinLockDemo.add();
}
}).start();
}
SleepHelper.sleep(3);
System.out.println(count);
}
public void add(){
myLock();
count++;
myUnlock();
}
}
Pessimistic Lock and Optimistic Lock
Ideologically, synchronized is a pessimistic lock. Pessimistic considers that the concurrency in the program is serious. If one word or no action is required, lock it, so guard against deadlock. CAS is an optimistic lock, optimistically considers that the concurrency in the program is not so serious, so let the thread keep retrying the update.
In addition to the Atomic and Lock family classes mentioned above, the CAS mechanism is used in java even before JAVA1.6 or above turns synchronized into a heavy lock.
Disadvantages of CAS:
- CPU overhead
In the case of high concurrency, many threads try to check and update a variable repeatedly, but they are not expected. If the update is unsuccessful for a long time, they will spin all the time, which is equivalent to a dead cycle and will put a lot of pressure on the CPU.
-
ABA Question
This is the biggest problem with CAS mechanisms.
ABA Question
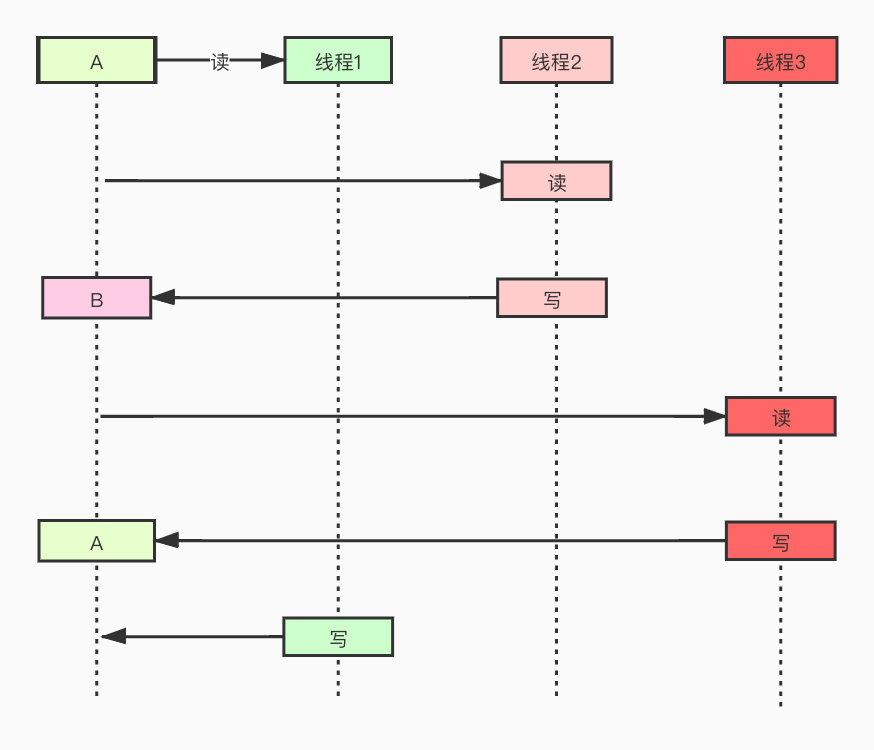
That is to say, a thread has changed the value back to B, and another thread has changed the value back to A. For a thread that is judged at this time, it will find out whether its value is A, so he will not know if it has been changed. In fact, many scenarios have nothing to do if only the final result is correct.
However, in the actual process, you still need to record the process of modification, such as what the funds modify. Every time you modify, you should have a record to facilitate backtracking.
-
Solution 1, plus the stamp version number. With the AtomicStampedReference class, each operation validates not only the expected value but also the expected version
private static AtomicInteger atomicInt = new AtomicInteger(100); private static AtomicStampedReference atomicStampedRef = new AtomicStampedReference(100, 0); public static void main(String[] args) throws InterruptedException { Thread intT1 = new Thread(new Runnable() { @Override public void run() { atomicInt.compareAndSet(100, 101); atomicInt.compareAndSet(101, 100); } }); Thread intT2 = new Thread(() -> { SleepHelper.sleep(1); boolean c3 = atomicInt.compareAndSet(100, 101); System.out.println(c3); // true }); intT1.start(); intT2.start(); intT1.join(); intT2.join(); Thread refT1 = new Thread(() -> { SleepHelper.sleep(1); atomicStampedRef.compareAndSet(100, 101, atomicStampedRef.getStamp(), atomicStampedRef.getStamp() + 1); System.out.println(atomicStampedRef.getReference() + "\t" + atomicStampedRef.getStamp()); atomicStampedRef.compareAndSet(101, 100, atomicStampedRef.getStamp(), atomicStampedRef.getStamp() + 1); System.out.println(atomicStampedRef.getReference() + "\t" + atomicStampedRef.getStamp()); }); Thread refT2 = new Thread(() -> { int stamp = atomicStampedRef.getStamp(); SleepHelper.sleep(2); boolean c3 = atomicStampedRef.compareAndSet(100, 101, stamp, stamp + 1); System.out.println(c3); // false }); refT1.start(); refT2.start(); } } -
Solution 2: Timestamp
Check the time stamp together when querying, modify the update time together when the value is updated and the top of the pair. This also ensures that there are many methods but they are the same as the version number.
Unsafe
The Java language does not have direct access to the underlying operating system like C and C++, but JVM provides us with a unsafe class that calls many c++ methods.
It can
-
Direct Operation Memory
For example allocateMemory(), put(), freeMemory()...
-
Generate instances of classes directly
allocateInstance( )
-
Direct manipulation of class or instance variables
getInt( ),getObject( )
-
Operation on CAS
CompeAndSwapObject (). It is unsafe's compareAndSwapInt method that guarantees atomic operation between Compare and Wap operations
AQS
Core: There is a shared state value + threads grabbing each other (threadqueue)
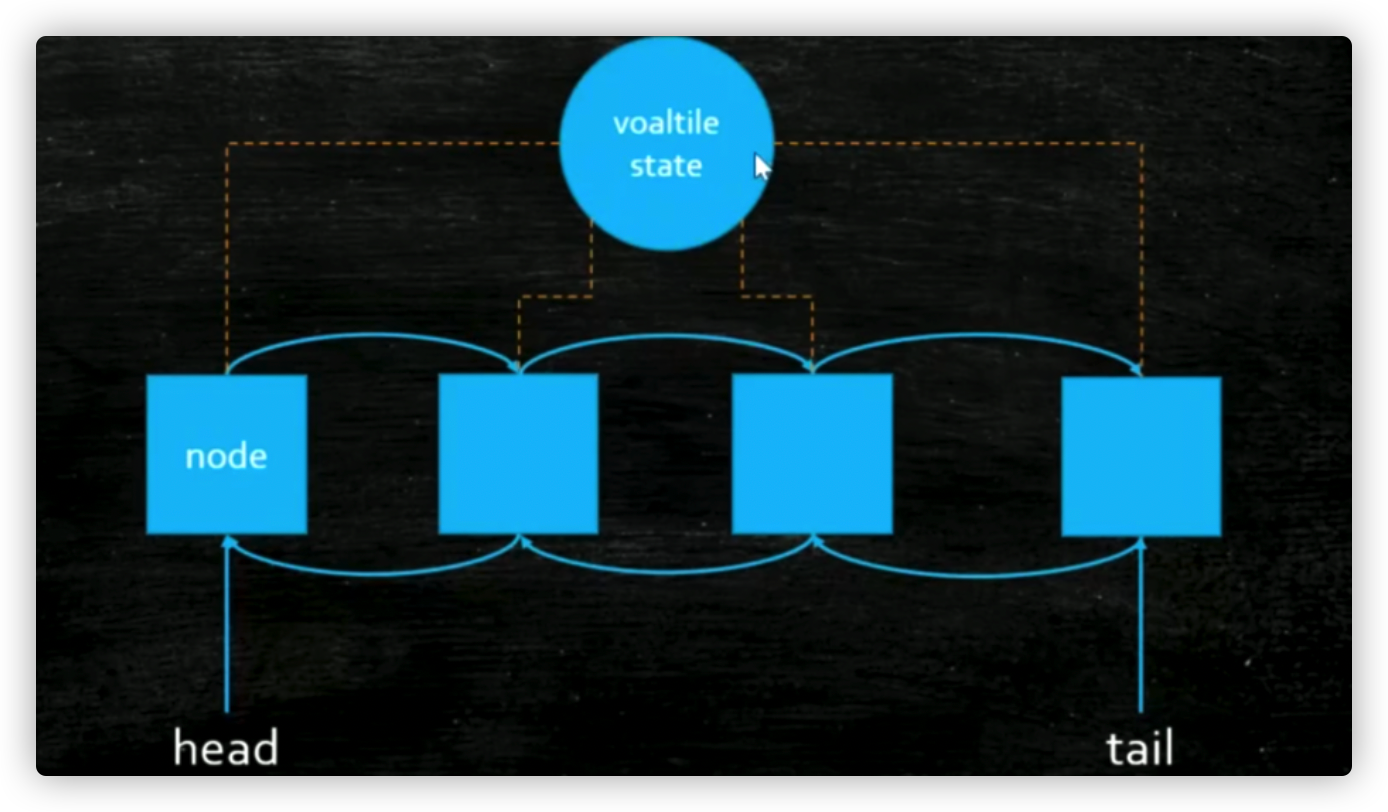
Form:
-
ThreadQueue: A two-way Chain of nodes of type Thread, where each thread node contends for state and the lock is acquired by whoever gets the state.
-
state: Different implementations of AQS represent different meanings
For example, ReentrantLock releases locks 3->2->1->0 by state representing reentry times 0->1->2->3.
AQS Interpretation with ReentrantLock as an Example
public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) {
selfInterrupt();
}
}
// tryAcquire: A new thread tried to acquire a lock
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
// addWaiter: Add a thread to the end of the queue
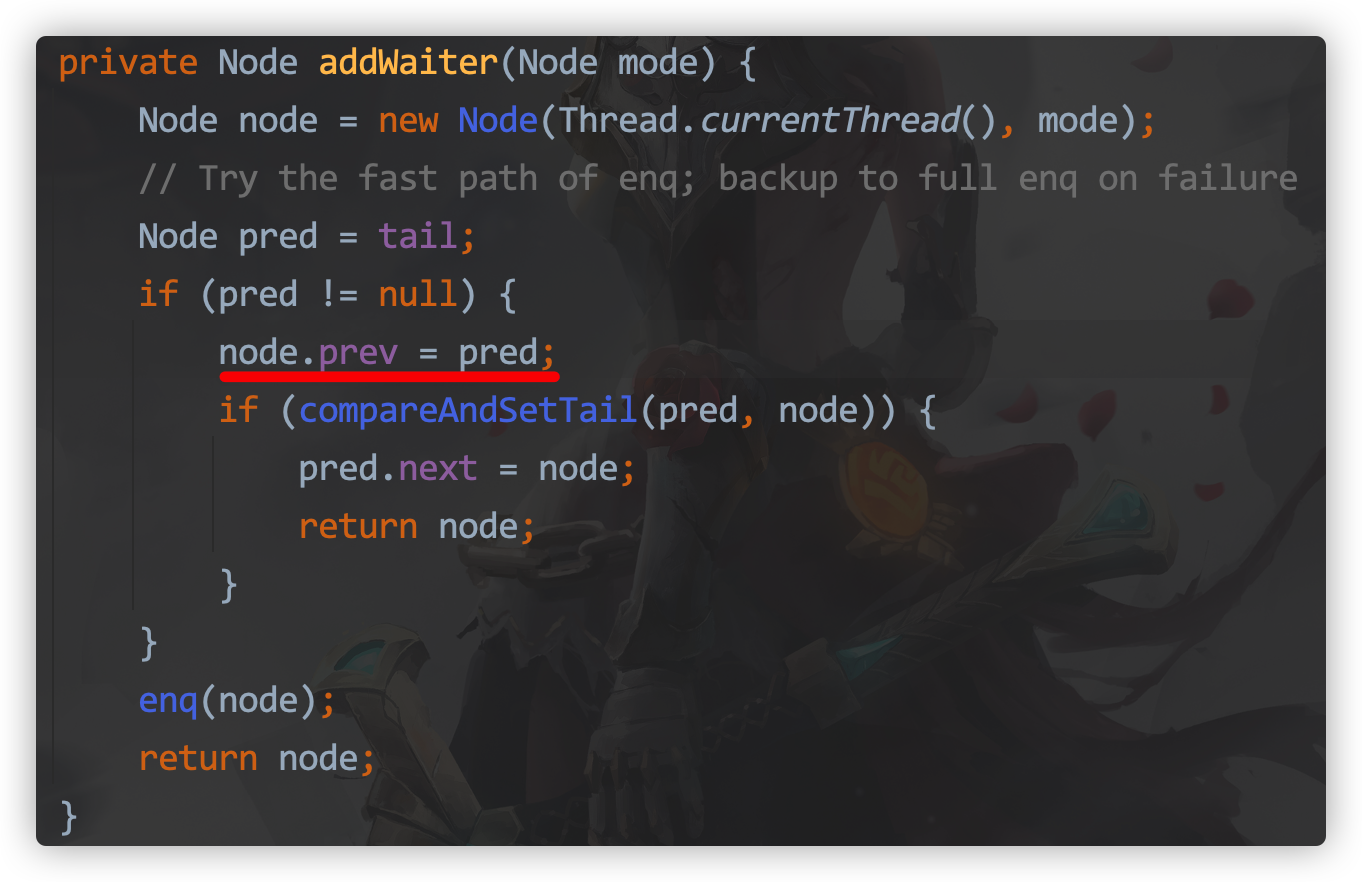
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) { // Adding threads to the end of the queue via CAS
pred.next = node;
return node;
}
}
enq(node);
// Insert node into queue and initialize if necessary
return node;
}
// Threads in the acquireQueued queue attempt to acquire locks
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
// Constantly obtain the precursor nodes of a node
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) { // If the precursor node is the first node, try locking through tryAcquire
setHead(node); // Once the precursor node is found, set the node as the head node.
p.next = null; // Remove references to previous headers and garbage collect
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
addWaiter: Add a thread to the end of the queue
A new thread executes a task to try to acquire a lock first. If it cannot acquire a lock, it joins the end of the AQS queue. The process of joining the queue is based on CAS. Purpose: If CAS is not used, the entire chain table will be locked, which is inefficient.
Threads in the acquireQueued queue attempt to acquire locks
Dead loop, from the end of the queue, each node gets the node in front of it until the head node finally gets the lock to end the cycle. The head node is garbage collected.
VarHandle
Can point to the same reference as a variable
For example, new has an Object, Object o = new Object(), O points to an Object object. You can create an Object object that VarHandle points to o.
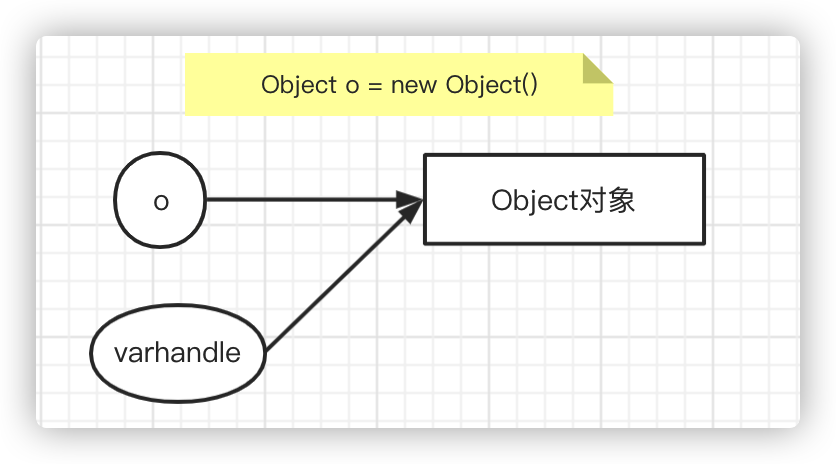
You can do things that reference itself cannot do, such as CAS atomic operations
handle implementation C++, since JDK1.9
Example: addWaiter in CAS was implemented based on VarHandle after jdk9



jdk1.8:
ThreadLocal
Thread local variable, with which each thread can have its own unique local variable, is actually a map.
Basic Use
Local variables are not shared
public class ThreadLocalTest {
static ThreadLocal<Person> tl = new ThreadLocal<>();
public static void main(String[] args) {
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(tl.get());
}).start();
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
tl.set(new Person());
}).start();
}
static class Person {
String name = "zhangsan";
}
}
The end result is null because the threadLocal variable set on thread 2 is not the same as the threadLocal variable set on thread 1
Local variable sharing
static ThreadLocal tl = ThreadLocal.withInitial(() -> {
return ...;
});
ThreadLocal principle
ThreadLocal is a map inside the current thread
K is the current Thread Local object in the KV of this map, and V is the set value
The set and get for ThreadLocal are as follows
public void set(T value) {
Thread t = Thread.currentThread(); // Get Current Thread
ThreadLocalMap map = getMap(t); // Gets the Map of the current thread
if (map != null) // Add map to current thread if there is one
map.set(this, value);
else
createMap(t, value); // Create and add values to threadLocal if there is no map for the current thread
}
// Gets the map for the specified thread
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) { // Pass in the current thread and value to create the ThreadLocal object
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
// Constructor for ThreadLocal
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY]; // INITIAL_CAPACITY = 16;Initialization capacity is 16
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
// =========================================
public T get() {
//Get the current thread
Thread t = Thread.currentThread();
//Each thread has its own ThreadLocalMap.
//ThreadLocalMap holds all ThreadLocal variables
ThreadLocalMap map = getMap(t);
if (map != null) {
//The key of the ThreadLocalMap is the current ThreadLocal object instance.
//Multiple ThreadLocal variables are placed in this map
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
//The value from the map is the ThreadLocal variable we need
T result = (T)e.value;
return result;
}
}
// If map is not initialized, initialize it here
return setInitialValue();
}
Purpose of ThreadLocal
Declarative transaction management. For example, to get every database connection, it is not possible to call the connection method to connect to the database for every operation. When this thread first calls the connection, the database connection information it gets is placed in threadLocal. The thread later does not need to call the connection method, and then it wants to get the database connection directly from ThreadLocalTake it.
Weakness and Strength
A reference is a variable pointing to an object
Strong Reference
A normal reference is a strong reference, which calls the finalize method when garbage is collected
SoftReference
When an object is pointed to by a soft reference, it will not be reclaimed unless there is enough memory. When there is enough memory, it will not be reclaimed even if System.gc() is called through FGC
The role of soft references: as caches
WeakReference
Weak references are recycled whenever they encounter GC.
Role of weak references: commonly used in containers
Typical applications in ThreadLoacal
Found pits in ThreadLocal by weak references
The relationship between ThreadLocal and Thread and ThreadLocalMap is shown in the diagram. Each thread has a ThreadLocalMap specified so that each thread has a unique local variable
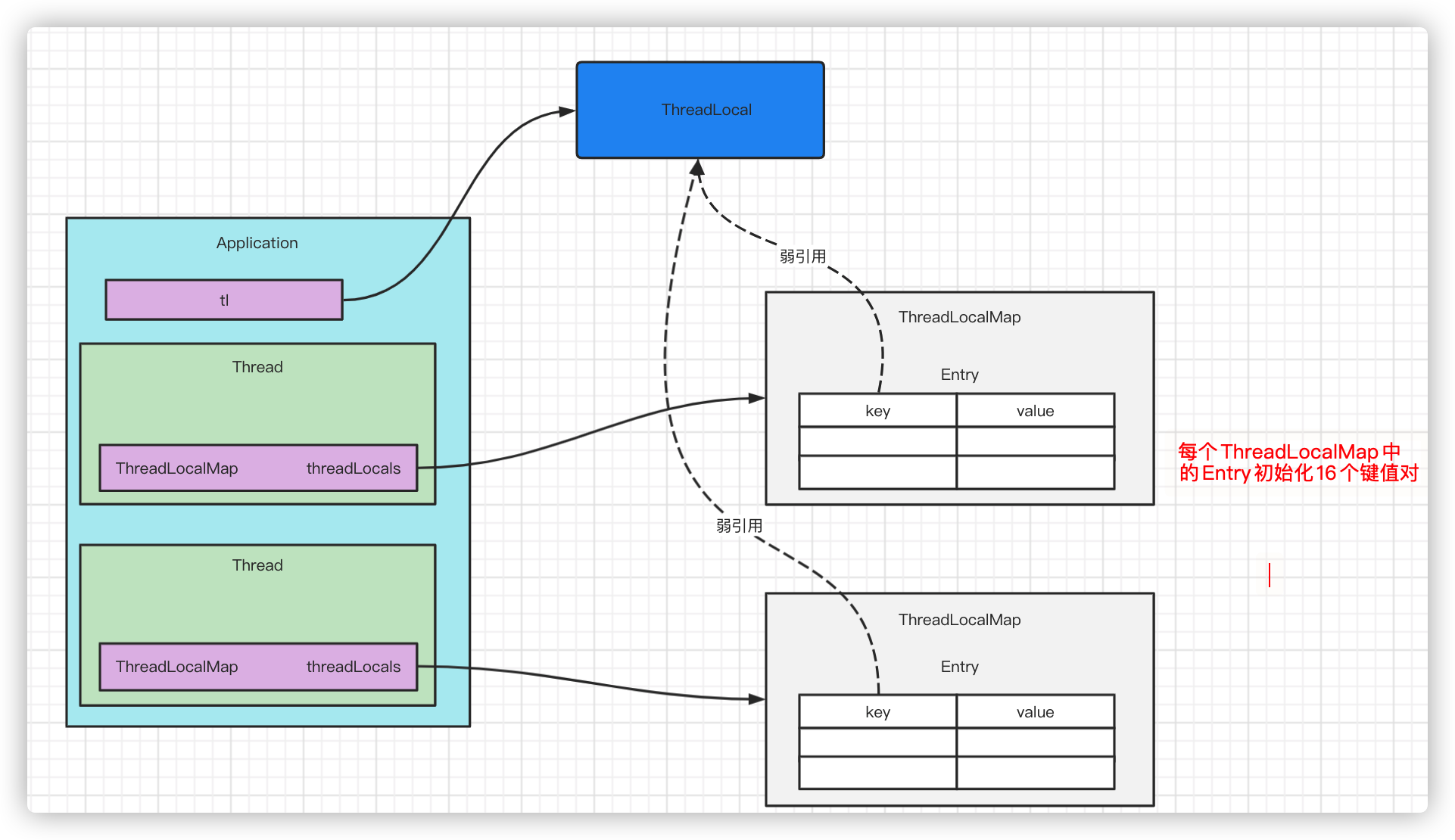
ThreadLocal.ThreadLocalMap is a special Map, and each key in its Entry is a weak reference: although our new out reference to the ThreadLocal object points to the ThreadLocal object, the key in Entry also points to the ThreadLocal object by a weak reference
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
//key is a weak reference
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
ThreadLocal Memory Leak Problem
Question 1: Why should I set a reference to a threadlocal object?
Think about it with your thighs and combine the above illustration. If there is no reference to a threadLocal object, the new ThreadLocal() is a fiction.
For strong references, even if tl = null, the key's reference still points to the ThreadLocal object, and ThreadLocal will never be recycled, so there will be memory leaks. Using weak references solves the problem that ThreadLocal will never recycle.
Question 2:
If ThreadLocal is recycled, the value of the key becomes null, causing the entire value to no longer be accessible, so there is still a memory leak
Solution: ThreadLocal is exhausted, make sure to remove it manually! Otherwise, it will cause memory leak.
PhantomReference
Used to manage out-of-heap memory.
There is a queue outside. When a dummy reference is recycled, the dummy reference is put in the queue. If one of the queues is detected to exist, it is proved that the dummy reference has been recycled.
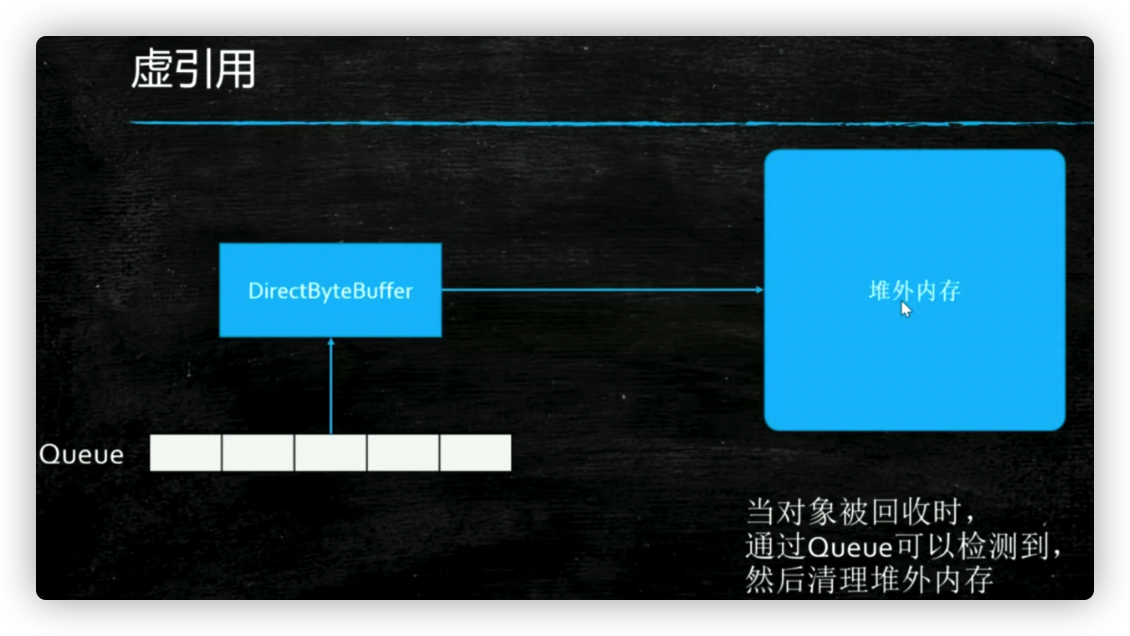
Note:
- Virtual references are for people writing JVM
- PhantomReference (object o, QUEUE) must have a queue parameter when used
- The value used is not available
- directbytebuffer in NIO, direct memory, out-of-heap memory
- Out-of-heap memory recycling in Java uses the Unsafe class, which you can get by reflection at 1.8
Concurrent Container
HashMap has thread security issues in a multi-threaded environment. What do you normally do?
- Use HashTable
- Using Collections.synchornizedMap(map)
- Using ConcurrentHashMap
Concurrent Modification Exception
public class TestConcurrentModification {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
for (int i = 0; i < 30; i++) {
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);
},"AA").start();
}
}
}
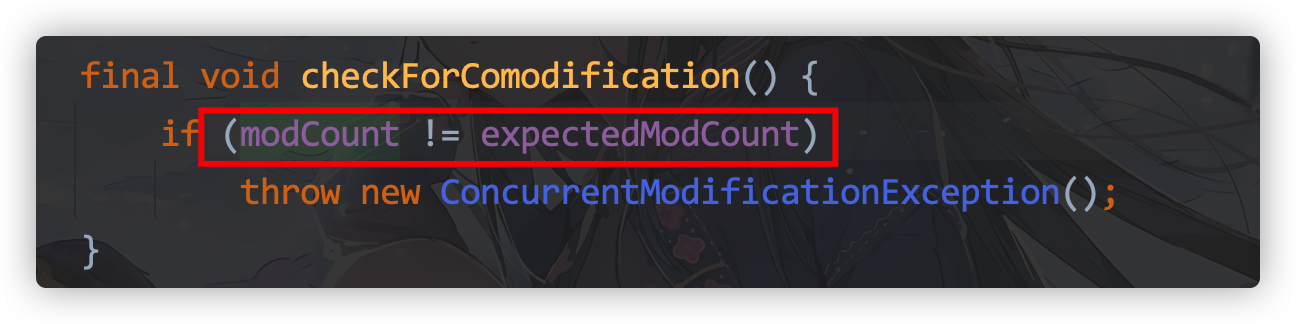
A concurrent modification exception occurred after running: ConcurrentModificationException
Because ArrayList will throw a java.util.ConcurrentModificationException exception if it is modified at the same time during iteration: concurrent modification exception
ThreadSafetyMap (Thread SafetyMap)
HashTable
Hashtable locks all operations compared to Hashmap
synchornizedMap
Created from Collections.synchronizedMap (Map<K, V> m)
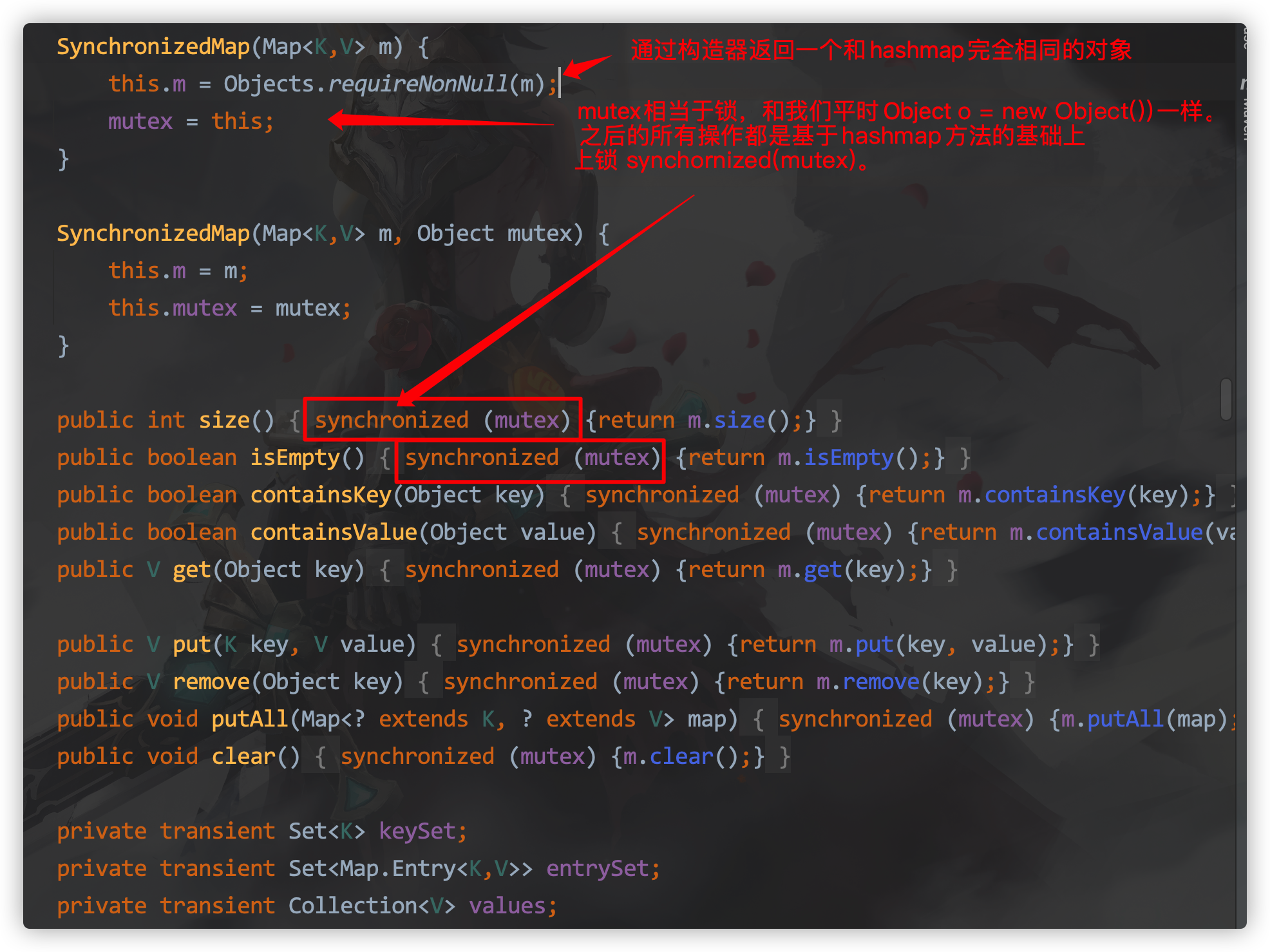
Mutex is equivalent to a lock, just like Object o = new Object (). All subsequent operations are based on synchornized(mutex) on the hashmap method.
ConcurrentHashMap
The underlying structure of ConcurrentHashMap is an array + Chain table.
put operation
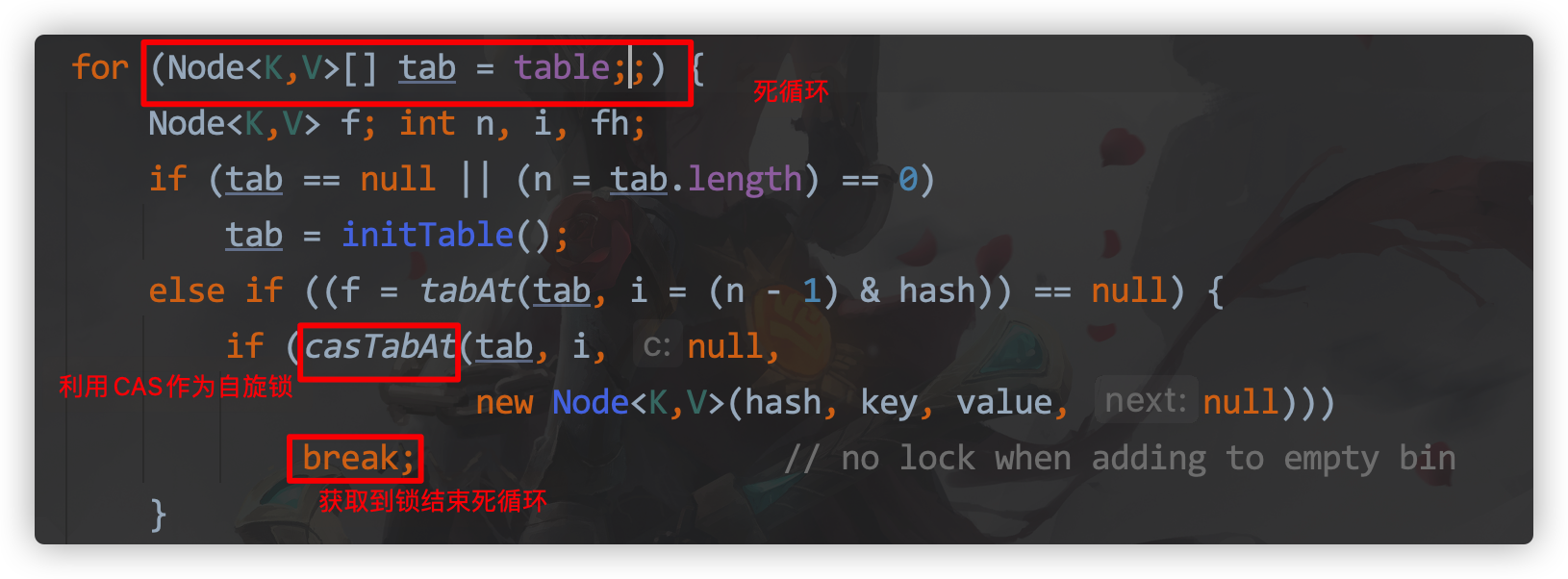
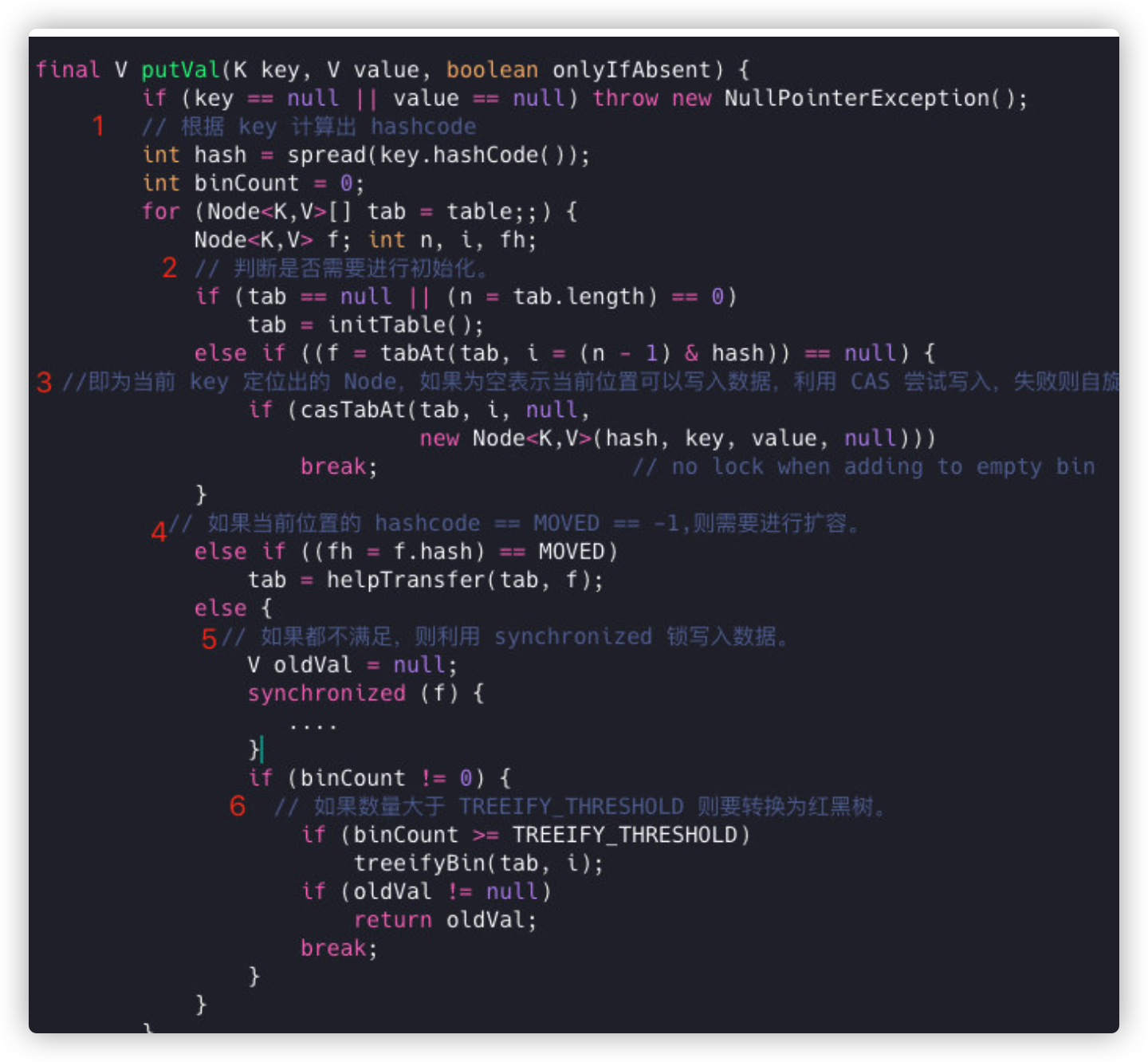
ConcurrentHashMap is a more complex put operation, which can be roughly divided into the following steps:
- hashcode is calculated from key.
- Determines whether initialization is required. A Node located for the current key, if empty indicates that the current location is writable, attempts to write using CAS will guarantee success if it fails.
- If the hashcode == MOVED == -1 at the current location, an expansion is required.
- If none is satisfied, the synchronized lock is used to write data.
- If the number is greater than TREEIFY_THRESHOLD, it will be converted to a red-black tree.
ConcurrentHashMap is also thread-safe Map, which is more efficient than HashTable because it uses spin-lock + segmented-lock when writing, and concurrenthashmap with a smaller granularity of locks is mainly read because the read method is not locked.
get operation
- Based on the calculated hashcode addressing, return the value directly if it's on a bucket.
- If it's a red-black tree, get the value the way the tree does.
- If it's not satisfied, then iterate through the list to get the value.
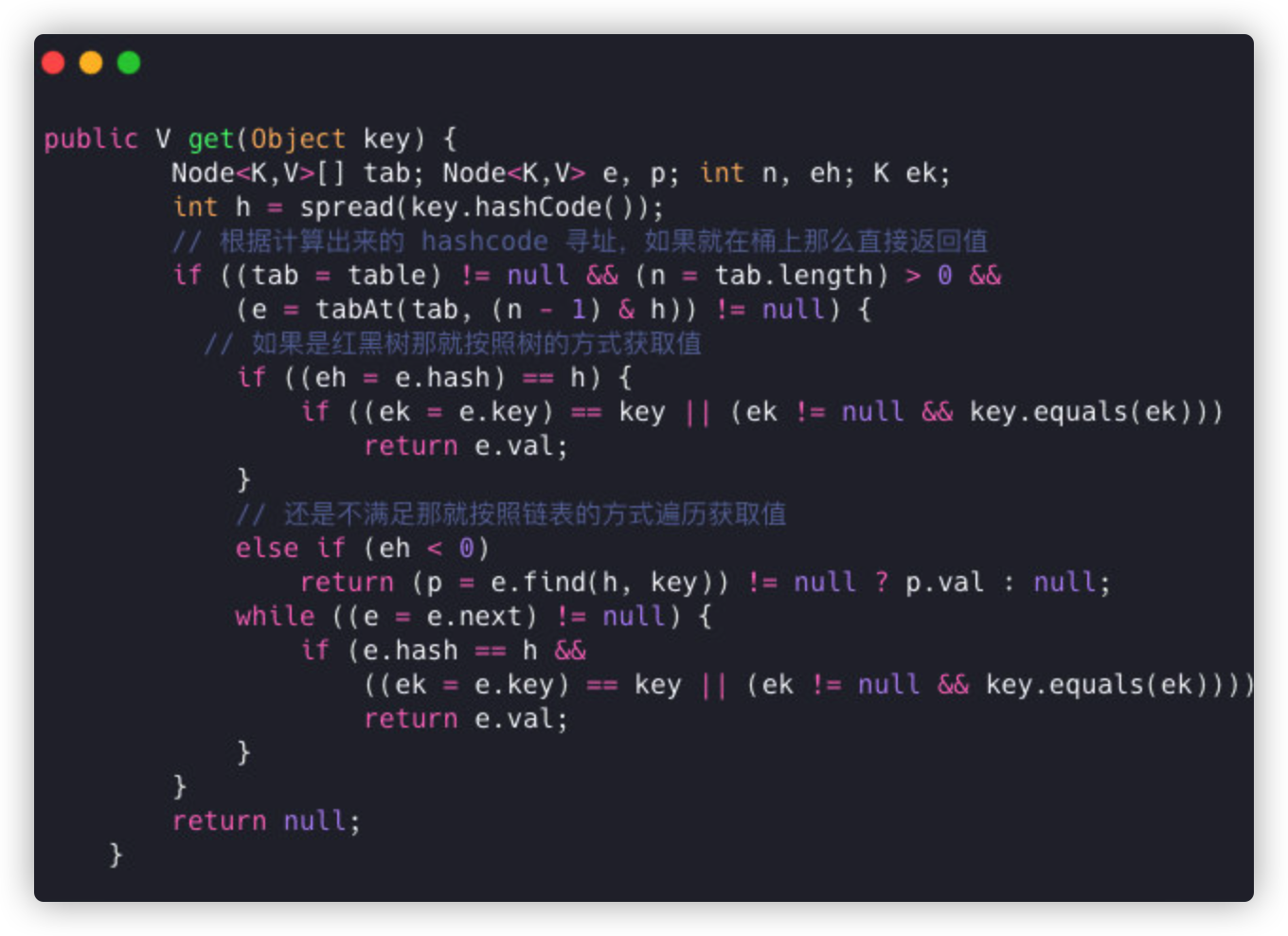
**Note:**TreeMap uses red and black trees, which are efficient for searching
The reason there is no ConcurrenTreeMap is that CAS is too complex to use in a tree structure
Therefore, a concurrent map: ConcurrentSkipListMap jump table implementation based on the jump table structure is proposed.
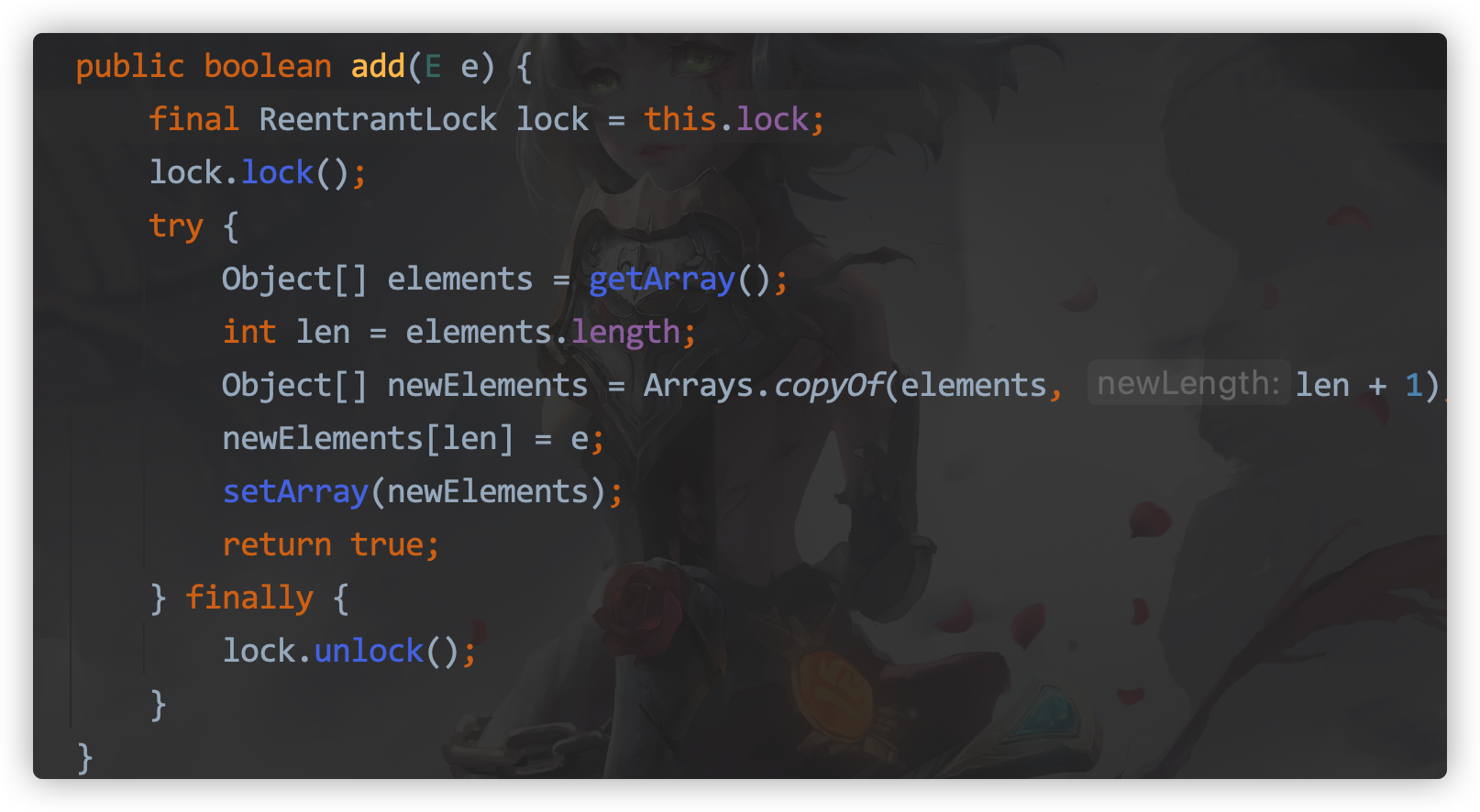
CopyOnWrite
CopyOnWriteArrayList/CopyOnWriteArraySet is recommended when there are more write operations than read operations.
Read without locking, write with a new ArrayList copied, add it later, and replace the old reference.
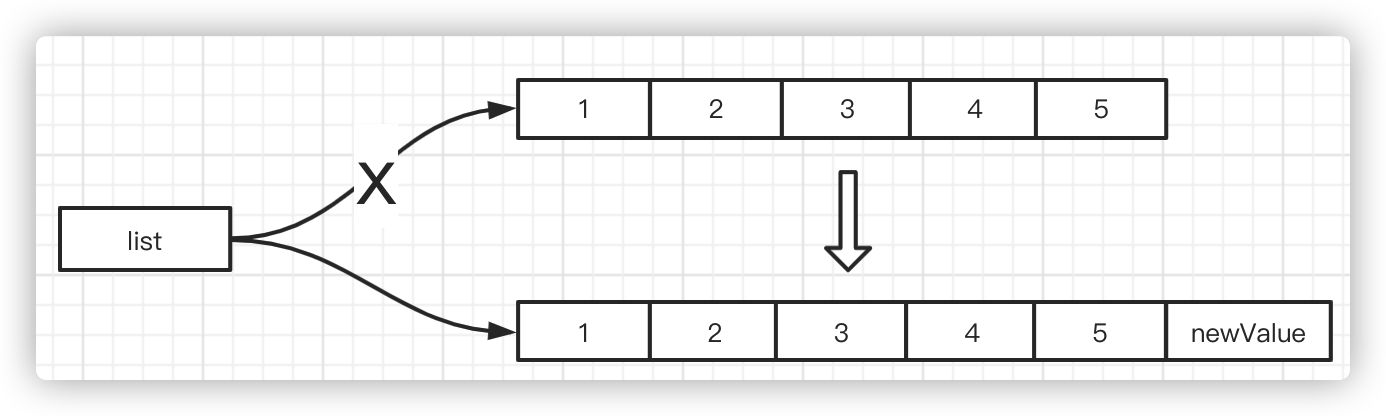
**Note: **Hashtable and Concurrent HashMap do not allow keys to be null or null compared to HashMap; HashMap allows keys to be null. It is unclear whether keys are null or not in multithreaded situations
Queue
Queue interface is a new container interface after List and Set to solve high concurrency problems
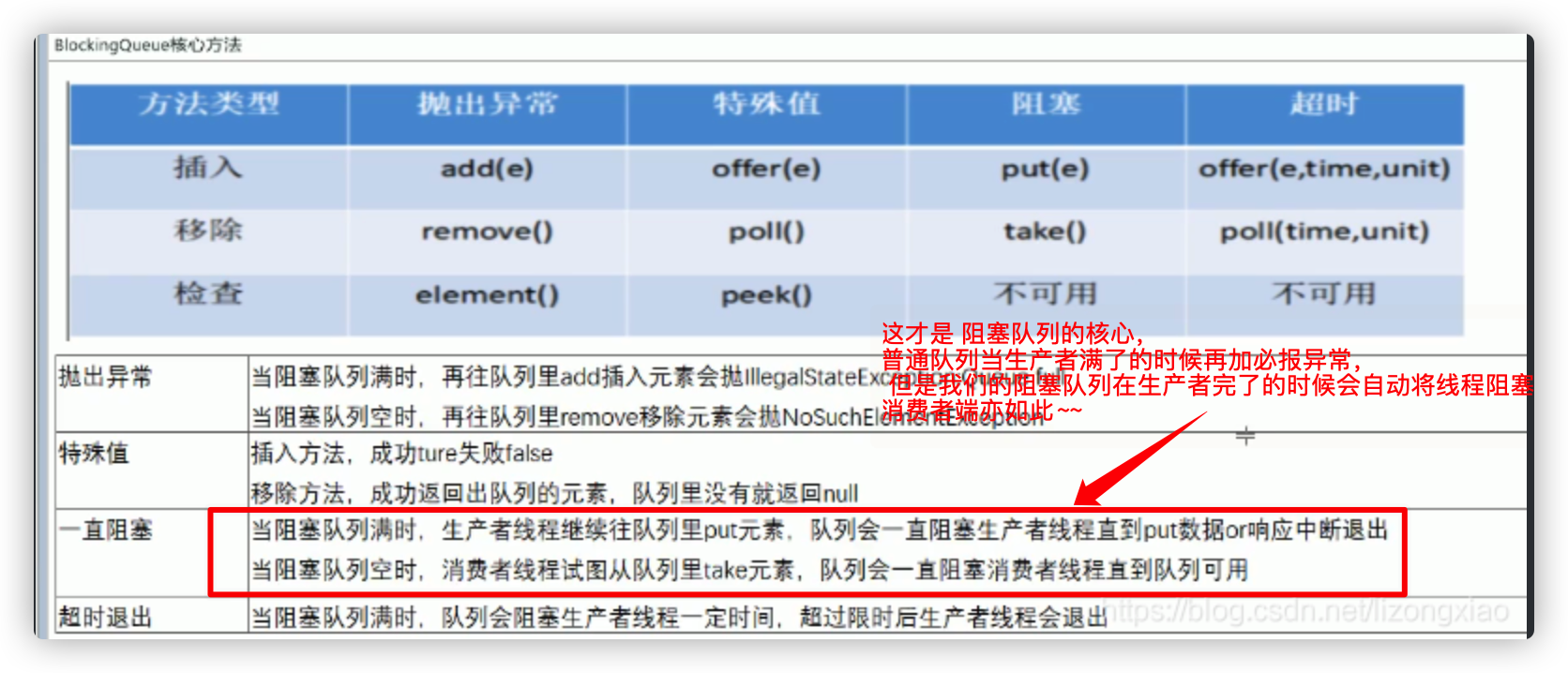
BlockingQueue
Blocking queues, commonly used are
-
BlockingQueue class
- LinkedBlockingQueue: A blocked queue implemented by a chain table, which is an unbound queue
- ArrayBlockingQueue: A bounded blocking queue consisting of an array structure.
- PriorityBlockingQueue: Unbounded blocked queue that supports priority ordering.
-
DelayQueue: A queue sorted by delay time. Delay is an interface that must be implemented when loading tasks into it. When taking a task, the queue is usually first in, first out. This queue is taken by wait time, and is generally used for timing tasks. Essentially, it is a priorityqueue, a binary tree model, with a small top heap.
-
SynchronusQueue is used to transfer tasks between two threads. The capacity is always zero. It can't be filled in. Threads have to wait when they are used. This is the most useful one in the thread pool. Many thread pools use this when they pick up tasks from each other.
-
Combination of front queues in LinkedTransferQueue The difference with SynchronusQueue is that this transferable content can be of length. NB adds a transfer method, meaning that when a thread is added to this queue, if it is a put method, the thread is loaded and gone. Transfer is finished, waiting, and when someone comes to take this resource, the thread goes.Is usually used to do an operation, but requires that there must be a result before continuing, such as to wait for the result to be fed back to the customer after payment
Differences between Queue and List
Queue adds many multi-threaded friendly API s, such as offer () peek (), pool(), put(), take().
- put/take is blocked. put must be loaded in. If the queue is full, this thread will block. Take must fetch out. If it is not, it will block
- Offer and add: Both insert elements to the end of the queue, but when the queue is exceeded, add () throws an exception for you to handle, and offer () returns false directly
- peek takes elements, but does not remove them
- poll is taken and remove d
- The principle of blocking is park/unpark (park at the bottom of await)
- Actually, Condition's await and signal methods are used
As for BlockingQueue, it is the underlying model for implementing MQ (message queue) for its put and take blocking methods
Eight Locks Theory
1 Standard Access, Print SMS or Mail first
2 Stop for 4 seconds Print SMS or Mail first within SMS method
3 Ordinary Hello method, text message or hello first
4 There are two mobile phones now, print SMS or email first
5 Two static synchronization methods, one mobile phone, printing SMS or email first
6 Two static synchronization methods, 2 Mobile phones, print SMS or email first
7 1 static synchronization method, 1 common synchronization method, 1 mobile phone, print SMS or mail first
81 static synchronization methods, 1 common synchronization method, 2 Mobile phones, print SMS or mail first
Run Answer:
1. SMS
2. SMS
3,Hello
4. Mail
5. SMS
6. SMS
7. Mail
8. Mail
To distinguish between object locks and class locks, synchornized locks on non-static methods belong to this (object locks), synchornized locks on static methods belong to Xxx.class (class locks)
public class EightLocks {
public static void main(String[] args) throws Exception {
Phone phone = new Phone();
Phone phone2 = new Phone();
new Thread(() -> {
try {
phone.sendSMS();
} catch (Exception e) {
e.printStackTrace();
}
}, "AA").start();
Thread.sleep(100);
new Thread(() -> {
try {
phone2.sendEmail();
} catch (Exception e) {
e.printStackTrace();
}
}, "BB").start();
}
}
class Phone {
public static synchronized void sendSMS() throws Exception {
SleepHelper.sleep(3);
System.out.println("------sendSMS");
}
public synchronized void sendEmail() throws Exception {
System.out.println("------sendEmail");
}
public void getHello() {
System.out.println("------getHello");
}
}
Thread Pool
Advantages of thread pools: Maximum concurrency is controlled by controlling the number of threads, making it easy to manage threads, and thread reuse
Inheritance relationship between thread pool interfaces and classes
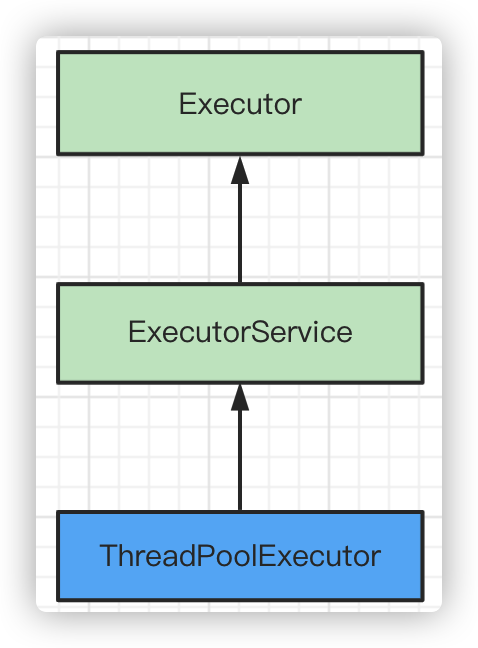
- ThreadPoolExecutor: Core class of thread pool
- ExcutorService: Defines a series of methods for thread pool life cycle
- Executor: The thread's execution interface, which defines only one execute() method
ExecutorService service = Executors.newCachedThreadPool();
Future<String> future = service.submit(c); //asynchronous
System.out.println("hello");
System.out.println(future.get());//block
FutureTask
Future: Stores the results to be produced by execution in the future.
Place the program in FutureTask, which executes when the thread starts and stores the results
We create threads in a callable-based manner that works with FutureTask.
FutureTask implements Runnable and Future interfaces
CompletableFuture
Used to process multithreaded requests asynchronously and manage the results of multiple Futures. The principle is to open multiple threads and process multiple future simultaneously.
**Scenario Case: ** Suppose you can provide a service that queries prices of the same kind of product (such as Tmall Taobao Jingdong) on major e-commerce websites and summarizes the display
There are three methods: priceOfTM(), priceOfTB(), Taobao (), and priceOfJD() from Jingdong.
The traditional method is to have three methods execute in turn. Now with CompletableFuture, request processing can be done asynchronously. CompletableFuture can manage the processing results of multiple future s. It saves time for programs to run.
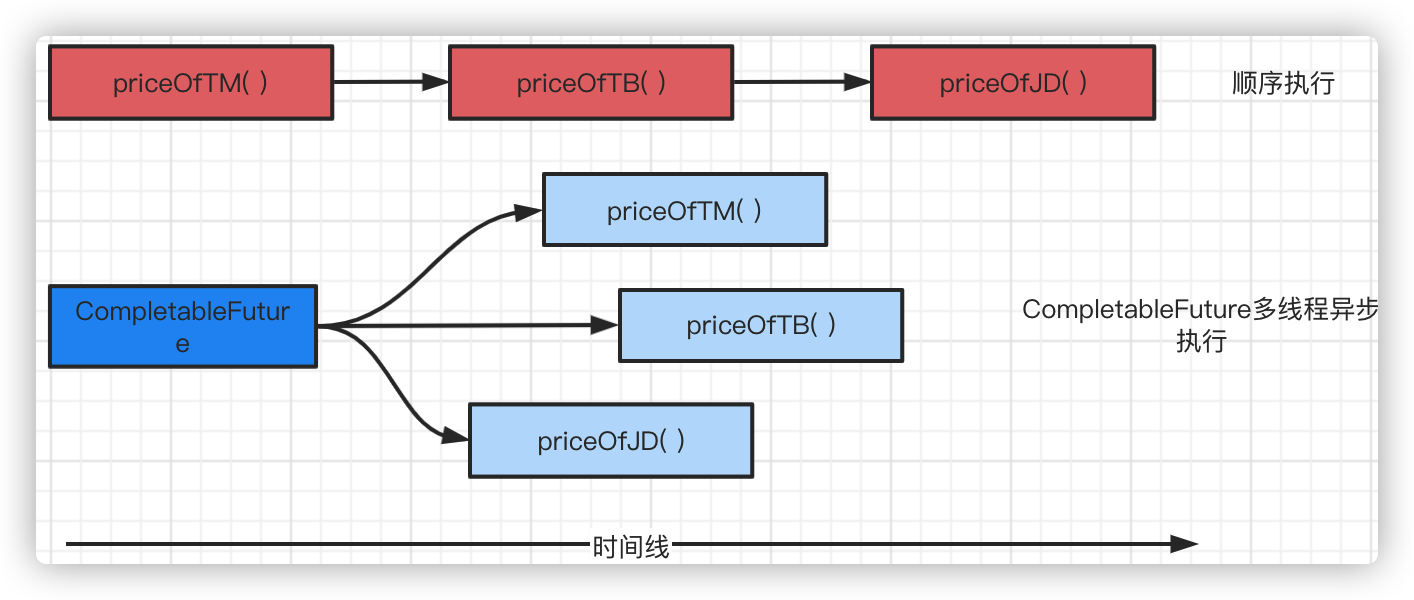
How to use CompletableFuture:
-
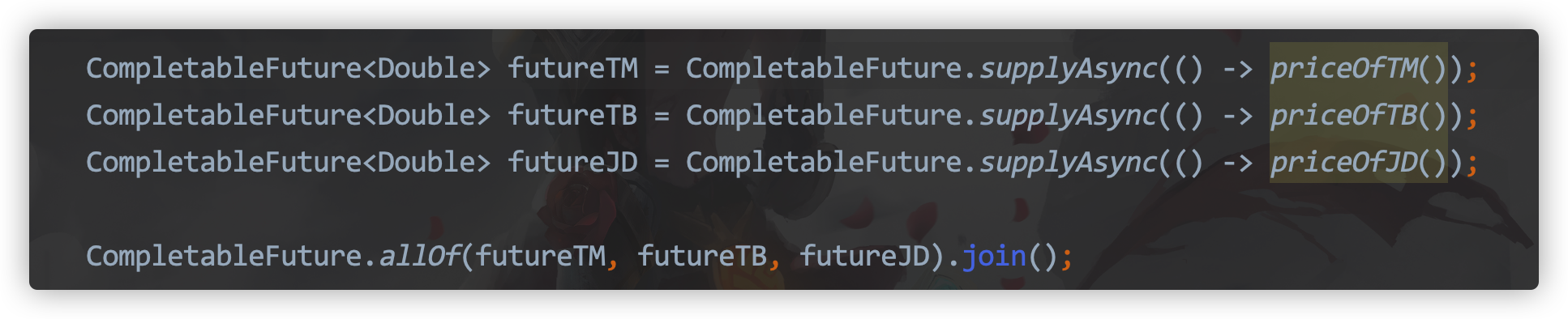
Executing multiple methods asynchronously using CompletableFuture
-
A series of chain operations can be used to execute methods using CompletableFuture

Thread pool creation
Mode 1
A pool has N fixed threads and a fixed number of threads
ExecutorService threadPool = Executors.newFixedThreadPool(5);
Mode 2
One task, one task, one pool, one route
ExecutorService service = Executors.newSingleThreadExecutor();
Mode 3
Elastically adjust the number of threads in the thread pool based on the number of concurrencies
ExecutorService service = Executors.newCachedThreadPool();
Method 4
Use ThreadPoolExecutor to create a thread pool, which must be used in development. See below.
Note: The Ali Development Manual states that ThreadPoolExecutor must be used to create thread pools during development, Executors cannot be used to create thread pools, and the creation thread new Thread() should not be displayed.
[Force) Thread resources must be provided through a thread pool, and self-explicit thread creation is not allowed in the application. Description: Thread pools have the advantage of reducing the time spent creating and destroying threads and the overhead of system resources to address resource shortages. Without thread pools, it can cause the system to create a large number of similar threads, leading to memory depletion or "over-switching" problems [Force) Thread pool not allowed Executors To create, but through ThreadPoolExecutor In this way, students writing more clearly understand the rules of the thread pool to avoid the risk of resource exhaustion. Explain: Executors The drawbacks of the returned thread pool object are as follows: 1)FixedThreadPool SingleThreadPool: Allowed request waiting queue length is Integer.MAX_ VALUE,Can cause a lot of requests to accumulate, resulting in OOM 2)CachedThreadPool: The number of creation threads allowed is Inteaer.MAX WALUE,Can create a large number of threads, resulting in OOM
ThreadPoolExecutor Bottom Principle
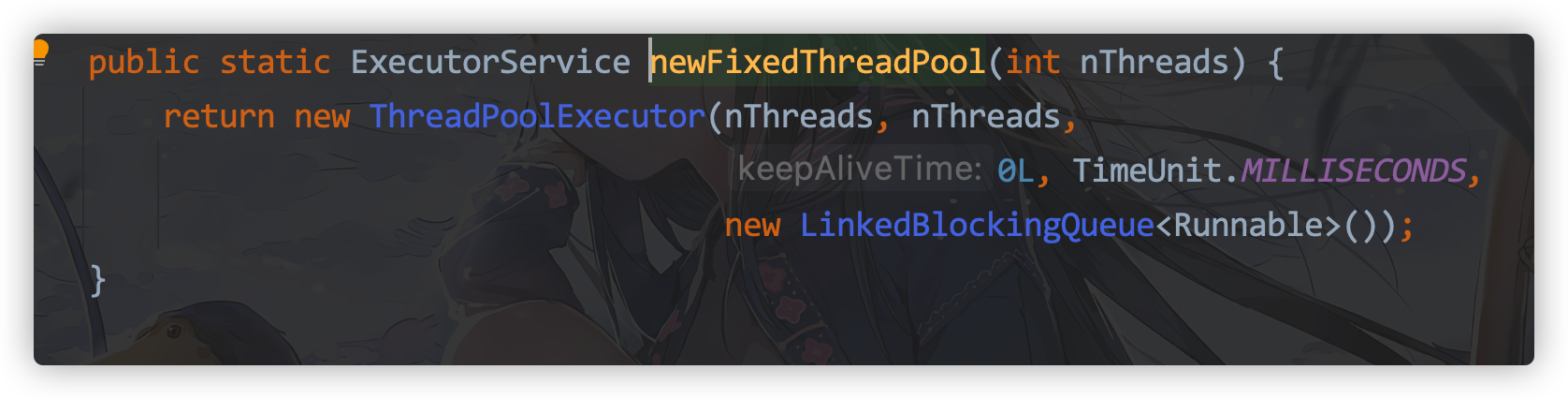
Use newFixedThreadPool
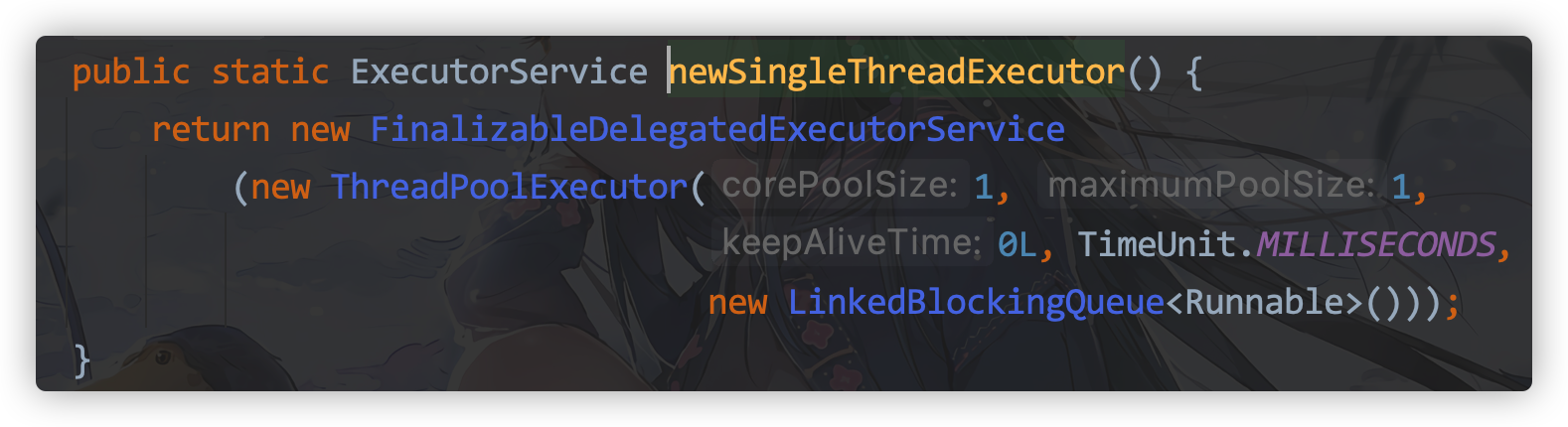
Using newSingleThreadExecutor
Use newCachedThreadPool

Thread pool 7 parameters
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
Seven parameters
- corePoolSize: Number of core threads in the thread pool.
- maximumPoolSize: Maximum number of threads
- keepAliveTime: The lifetime of an extra thread other than the core thread, after which it is returned to the operating system to avoid wasting resources.
- TimeUnit:keepAliveTime Unit
- BlockingQueue: Task queue, a task submitted but not yet executed.
- ThreadFactory: A thread factory that generates worker threads in the thread pool and is used to create threads, usually by default
- handler: The absolute policy used when the queue is full and the thread pool is full.
Note: maximumPoolSize in actual development needs to be estimated by itself. Judgment by machine configuration + formula + a lot of pressure measurement
The difference between executor() and submit() of a thread pool
Both open a thread and execute asynchronously. However, submit has a return value execute does not. submit's return value is a Future class, which can get exception information after the FutureTask executes
How Thread Pool Bottom Works
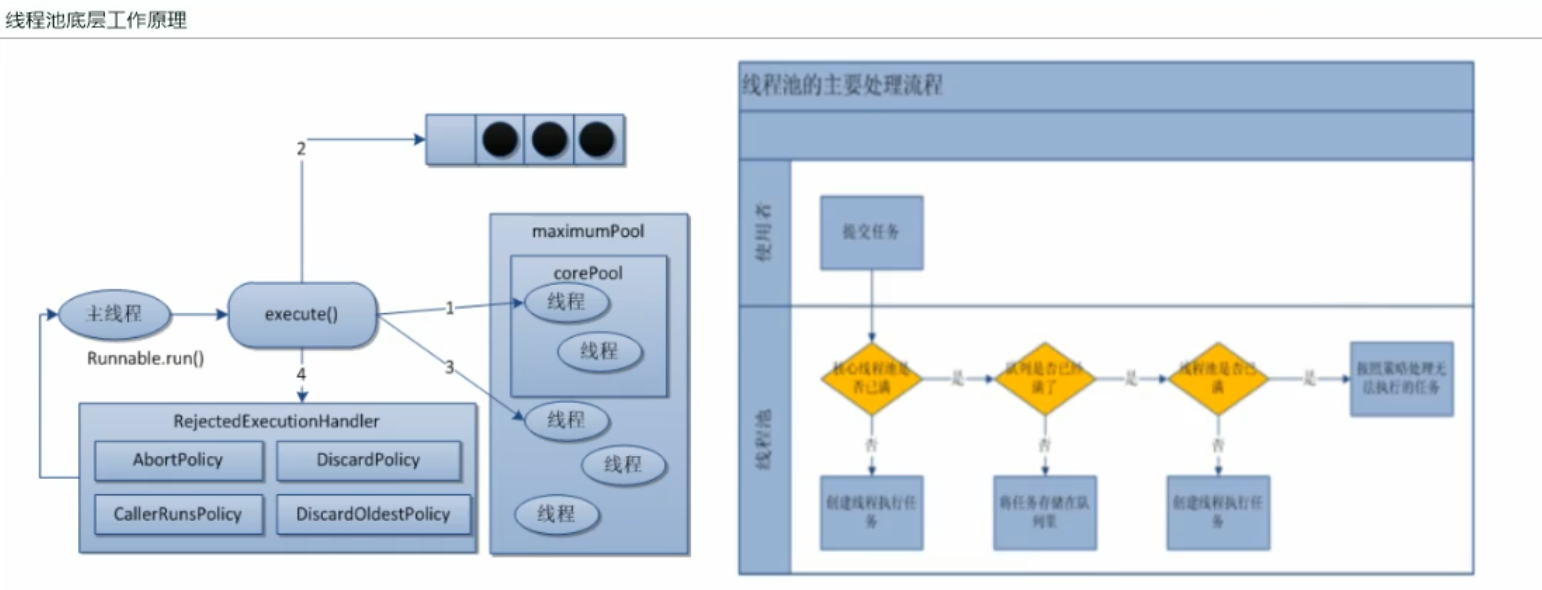
-
After creating the thread pool, start waiting for requests.
-
When the execute() method is called to add a request task, the thread pool makes the following judgment:
-
If the number of running threads is less than corePoolSize, create a thread to run the task immediately;
-
If the number of running threads is greater than or equal to corePoolSize, queue the task;
-
If the queue is full and the number of running threads is less than maximumPoolSize at this time, create a non-core thread to run the task immediately.
-
If the queue is full and the number of running threads is greater than or equal to maximumPoolSize, the thread pool initiates a saturated rejection policy to execute.
-
-
When a thread finishes a task, it takes the next task from the queue to execute.
-
When a thread has nothing to do (idle) for more than a certain amount of time (greater than the keepAliveTime parameter), the thread decides:
- If the number of currently running threads is greater than corePoolSize, the non-core thread is stopped.
- When all tasks for all thread pools are completed, it eventually shrinks to the size of the corePoolSize.
public class ThreadPoolDemo {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(2,
5,
2L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
try {
for (int i = 0; i < 9; i++) {
executor.execute(() ->{
System.out.println(Thread.currentThread().getName() + "In business~~~");
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
executor.shutdown();
}
}
}
Thread pool rejection policy
-
AbortPolicy (default): throw an exception directly, RejectedExecutionException
-
CallerRunsPolicy: Tasks are not discarded or exceptions are thrown back to the caller for execution. If a task is called by the main method, the rejected method is given to main() for execution.
-
DiscardOldestPolicy: Discard the longest-waiting task in the queue and join the queue to make it new.
-
DiscardPolicy: Discard unhandled tasks without handling them or throwing exceptions. This is the best strategy if you allow tasks to be lost.
Note: The above built-in rejection policies all implement the RejectedExecutionHandle interface
-
Rejection policies can be customized
General custom thread pool rejection policy in development. Scenario: when order request concurrency is too high, waiting queue and thread pool are full, the requested order is rejected, then the rejected request can be saved in kafka or rabbitmq or mysql and logged before processing when it is released
Rejection policy for custom thread pools
Implement RejectedExecutionHandle method
public class MyRejectedHandler {
public static void main(String[] args) {
ExecutorService service = new ThreadPoolExecutor(4, 4,
0, TimeUnit.SECONDS, new ArrayBlockingQueue<>(6),
Executors.defaultThreadFactory(),
new MyHandler());
}
static class MyHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
//log("r rejected")
//save r kafka mysql redis
//try 3 times
if(executor.getQueue().size() < 10000) {
//try put again();
}
}
}
}
What is the specific strategy or depends on the specific business.
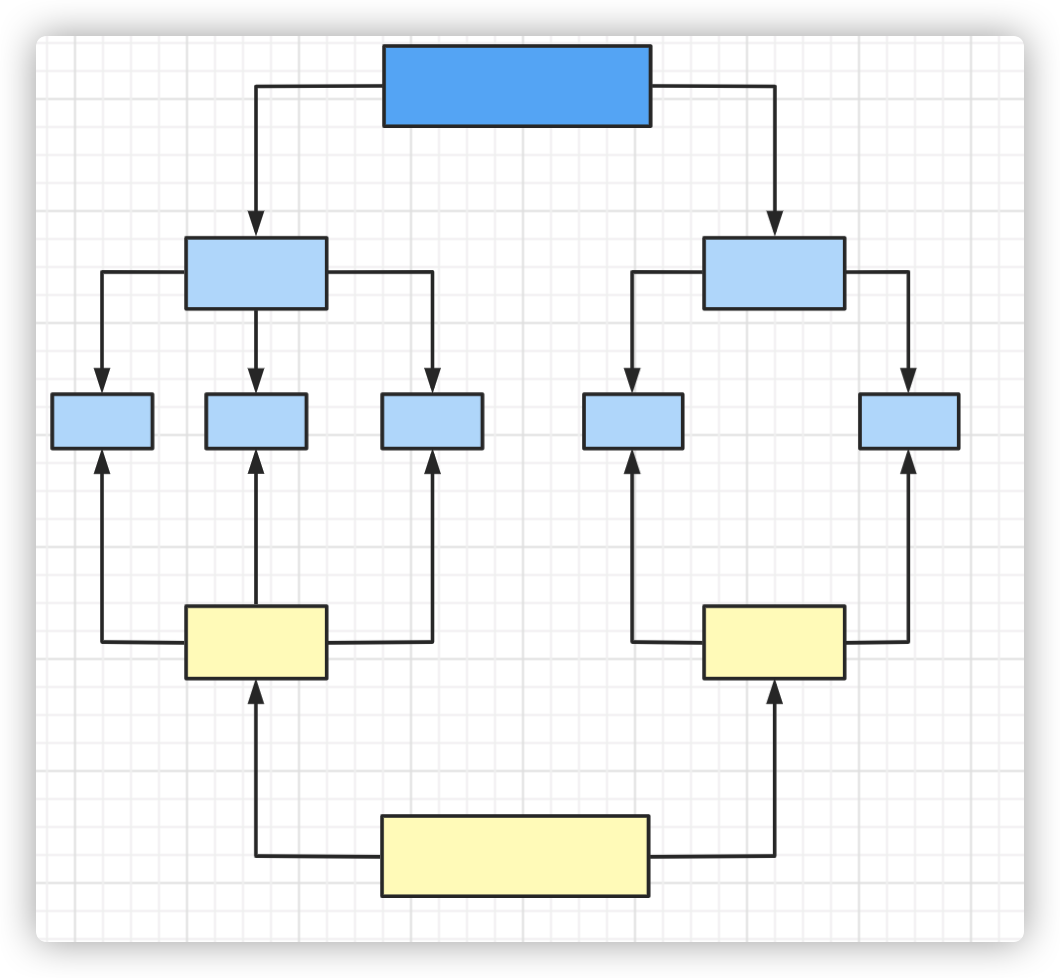
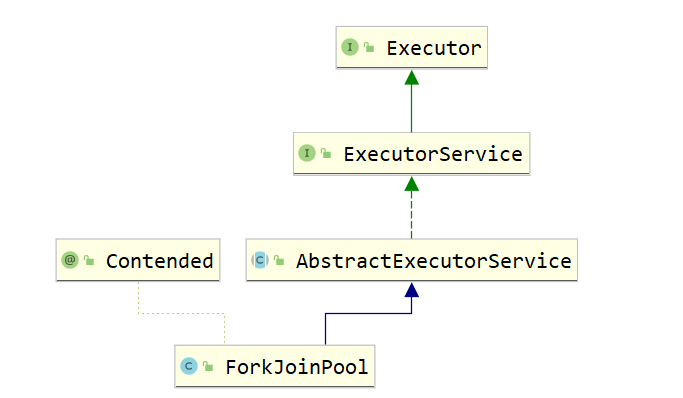
ForkJoinPool
Tasks that break down summaries are subtasks that are executed by multiple threads. Ultimately, the process of merging the results into summaries is CPU intensive. Note: Subtasks cannot be executed before they are executed.
Belongs to Task Split+Result Merge
Characteristic:
- Each thread in ForkJoinPool has its own unique work queue, while all threads in ThreadPoolExecutor share a single work queue.
- Work stealing: A thread work queue in ForkJoinPool can steal work queues from other threads.
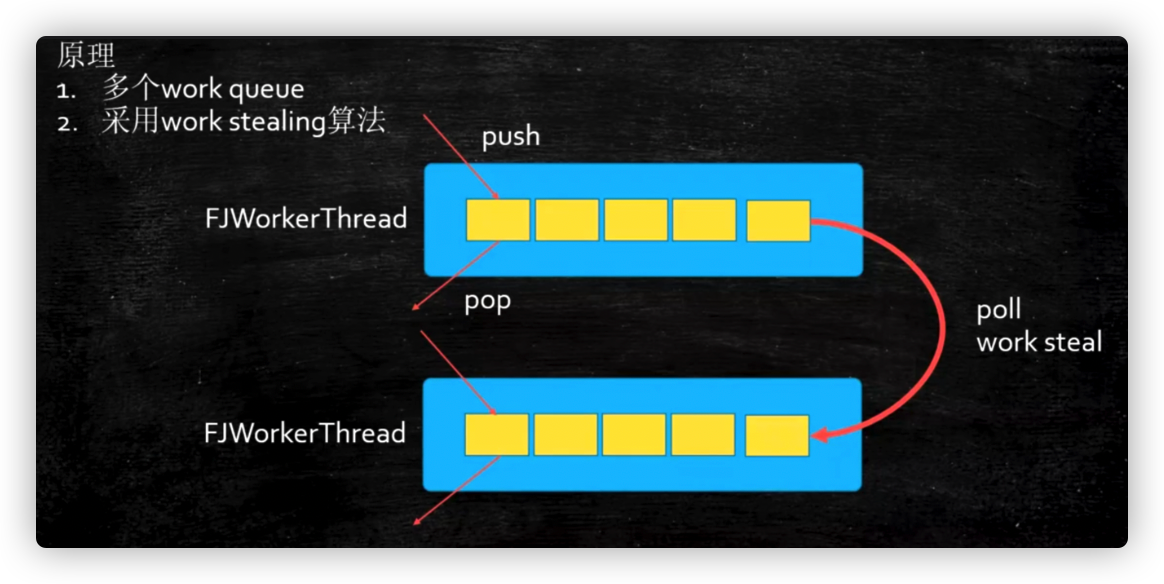
When a thread is executing faster, to prevent idle threads and maximize cpu utilization, fast-executing threads can steal tasks from slower-executing threaded work queues. Steal from the end of other threaded work queues and place them at the end of their own work queues
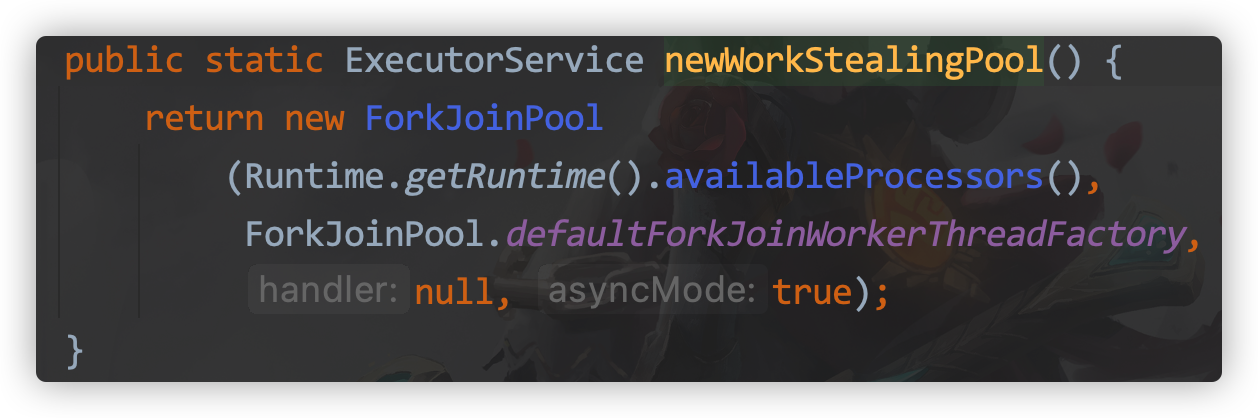
Creation Method
ExecutorService service = Executors.newWorkStealingPool();
At the bottom of it is new ForkJoinPool, which is designed to provide a more convenient interface for defining parameters, and that's all
RecursiveTask: Recursive Task: Task that can be called recursively after inheritance, with a return value
public class ForkJoinPool {
static int[] nums = new int[100_0000];
static final int MAX_NUM = 50000;
static Random r = new Random();
static {
for(int i=0; i<nums.length; i++) {
nums[i] = r.nextInt(100);
}
long start = System.currentTimeMillis();
System.out.println("---" + Arrays.stream(nums).sum()); //stream api
long end = System.currentTimeMillis();
System.out.println("time spend of stream method--" + (end - start));
}
static class AddTaskRet extends RecursiveTask<Long> {
private static final long serialVersionUID = 1L;
int start, end;
AddTaskRet(int s, int e) {
start = s;
end = e;
}
@Override
protected Long compute() {
if(end-start <= MAX_NUM) {
long sum = 0L;
for(int i=start; i<end; i++) sum += nums[i];
return sum;
}
int middle = start + (end-start)/2;
AddTaskRet subTask1 = new AddTaskRet(start, middle);
AddTaskRet subTask2 = new AddTaskRet(middle, end);
subTask1.fork();
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
public static void main(String[] args) throws IOException {
ForkJoinPool fjp = new ForkJoinPool();
AddTaskRet task = new AddTaskRet(0, nums.length);
long start = System.currentTimeMillis();
fjp.submit(task);
long result = task.join();
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("time spend of forkjoin method--" + (end - start));
}
}
Parallel Stream
The bottom level of parallel streaming is ForkJoinPool
public class T13_ParallelStreamAPI {
public static void main(String[] args) {
List<Integer> nums = new ArrayList<>();
Random r = new Random();
for(int i=0; i<10000; i++) nums.add(1000000 + r.nextInt(1000000));
long start = System.currentTimeMillis();
nums.forEach(v->isPrime(v));
long end = System.currentTimeMillis();
System.out.println(end - start);
//Using parallel stream api
start = System.currentTimeMillis();
nums.parallelStream().forEach(T13_ParallelStreamAPI::isPrime);
end = System.currentTimeMillis();
System.out.println(end - start);
}
// Finding prime numbers
public static boolean isPrime(int num) {
for(int i=2; i<=num/2; i++) {
if(num % i == 0) return false;
}
return true;
}
}