catalogue
Common built-in variables in awk
sed editor
sed is a flow editor that edits the data flow based on pre provided – group rules before the editor processes the data.
The sed editor can process the data in the data stream according to commands, which are either input from the command line or stored in a command text file.
sed workflow mainly includes three processes: reading, executing and displaying:
● read: sed reads a line from the input stream (file, pipeline, standard input) and stores it in the temporary buffer (also known as pattern space)
● execution: by default, all sed commands are executed sequentially in the mode space. Unless the address of the line is specified, the SED command will be executed successively on all lines.
● display: send the modified content to the output stream. After sending data, the mode space will be cleared. Before all file contents are processed, the above process will be repeated until all contents are processed.
Before all file contents are processed, the above process will be repeated until all contents are processed.
Note: by default, all sed commands are executed in the mode space, so the input file will not change unless the output is stored by redirection.
Command format:
sed -e 'operation' File 1 file 2...
sed -n -e 'operation' File 1 file 2 ...
sed -f Script file 1 file 2 ...
sed -i -e 'operation' File 1 file 2 ...
sed -e '{
Operation 1
Operation 2
...
}' File 1 file 2 ...
sed common options
-e or--expression=: Indicates that the input text file is processed with the specified command. Only one operation command can be omitted. One-When executing multiple operation commands -f or--file=:Indicates that the input text file is processed with the specified script file. -h or--help: Displays help. -n,--quiet or silent: prohibit:sed Editor output, but can work with p command- -Use to complete the output. -i: Modify the target text file directly.
sed common operations:
s:Replace, replace the specified character. d:Delete, deletes the selected row. a: Add, add one below the current line-Line specifies the content. i: Insert, inserts a row of specified content above the selected row. c:Replace to replace the selected row with the specified content. y:For character conversion, the length of characters before and after conversion must be the same. p:Print. If a row is specified at the same time, it means that the specified row is printed:If you do not specify a line, it means that all contents are printed:If there are non printed characters, use ASCII Code output. It is usually associated with“-n"Option one-Start using. =: Print line numbers. 1(a lowercase letter L):Print text and non printable in the data stream ASCII character(Such as Terminator $,Tab\t)
Basic Usage
Print the input by default
view file contents
 Support redirection
Support redirection
Supports pipe characters

sed script format
'address + command' composition
1. No address: process the full text (such as line number)
2. Single address:
#: Specified line, $: last line
/ Pattern /: each line that can be matched by the pattern here
3. Address range:
#,# # From # line to # line, 3,6 from line 3 to line 6
#,+# # From # line to + # line, 3, + 4 means from line 3 to line 7
/ pat1/,/pat2/ The line between the first regular expression and the second regular expression
#,/ pat/ From # No. 1 behavior until pat is found
/ pat/,# Until the # pat number is found
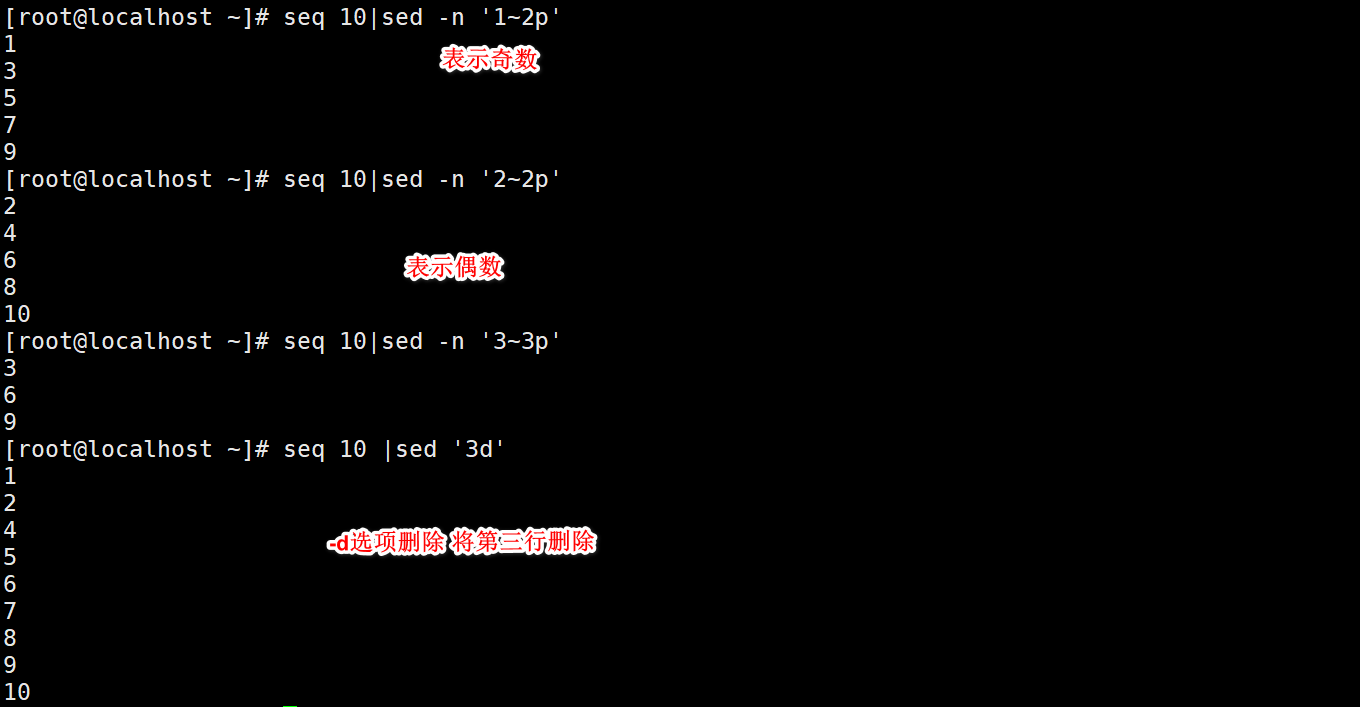
4. Step:~
1 ~ 2 odd rows
2 ~ 2 even rows
Example:
With automatic printing function, p print again
-The n option turns off automatic printing
Display line 3 directly

Display the second line directly

regular expression Automatic printing needs to be turned off, otherwise all will be printed
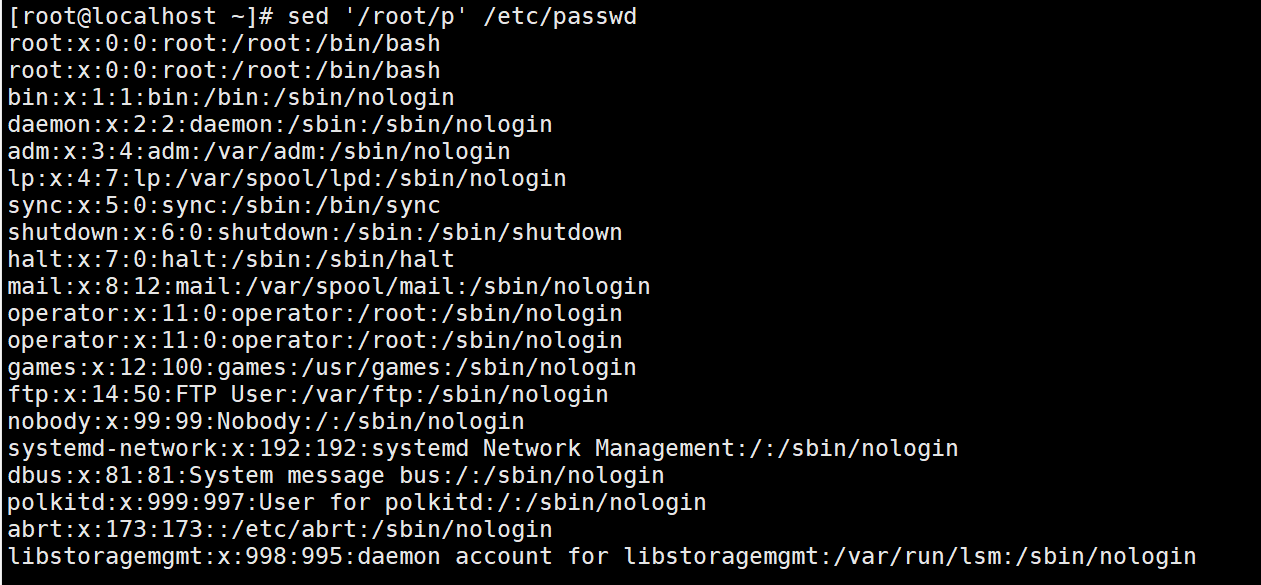
Print the line containing root / Root (what needs to be matched) / P (print) file name
Same function as grep root /etc/passwd

Display range Line number Display range

Add 4 lines after 3

You can match lines between two regular expressions
Displays the line between b and f
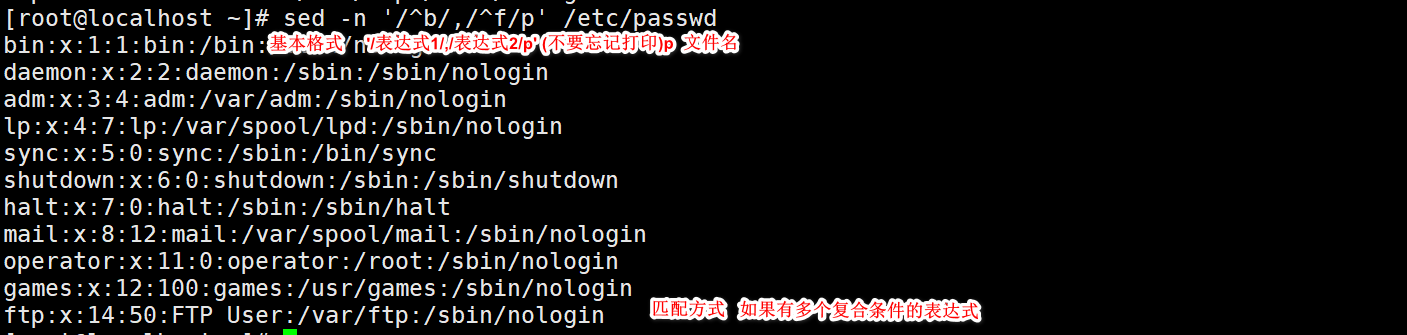
Start looking for the beginning of b and continue to find the beginning of f
Then find the beginning of b again. As soon as you find the beginning of f, it will be displayed without the beginning of f
Repeat cycle
Find logs between what time and what time

Odd even representation
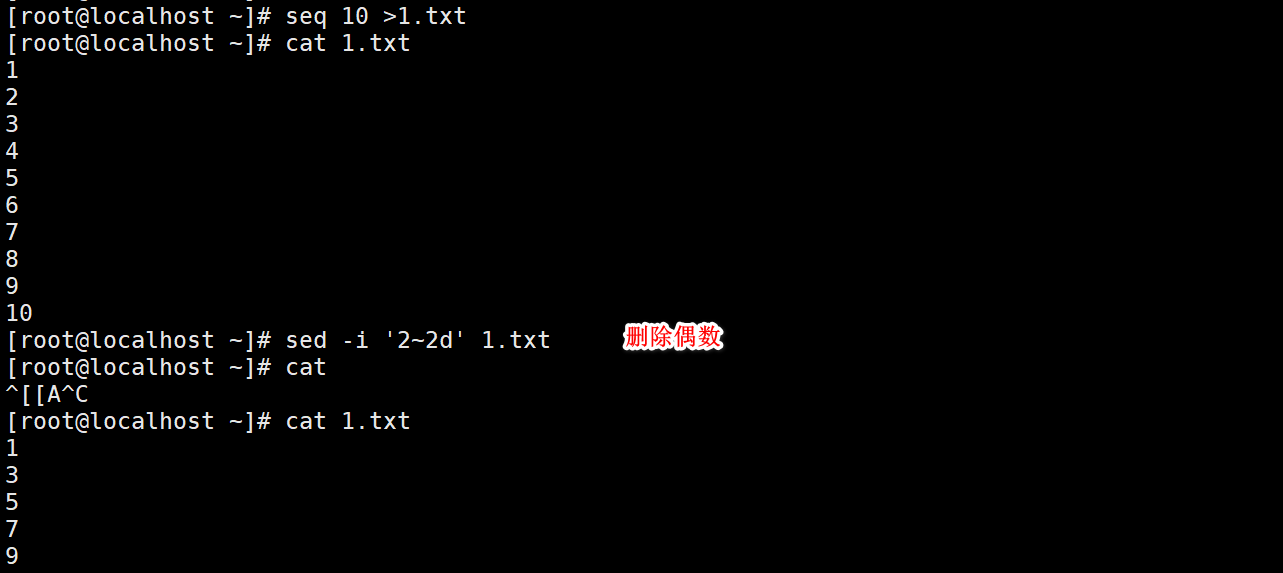
Modify file content, often used to modify configuration files
-i And - i.bak
Modify file Back up files before modifying them
-a added

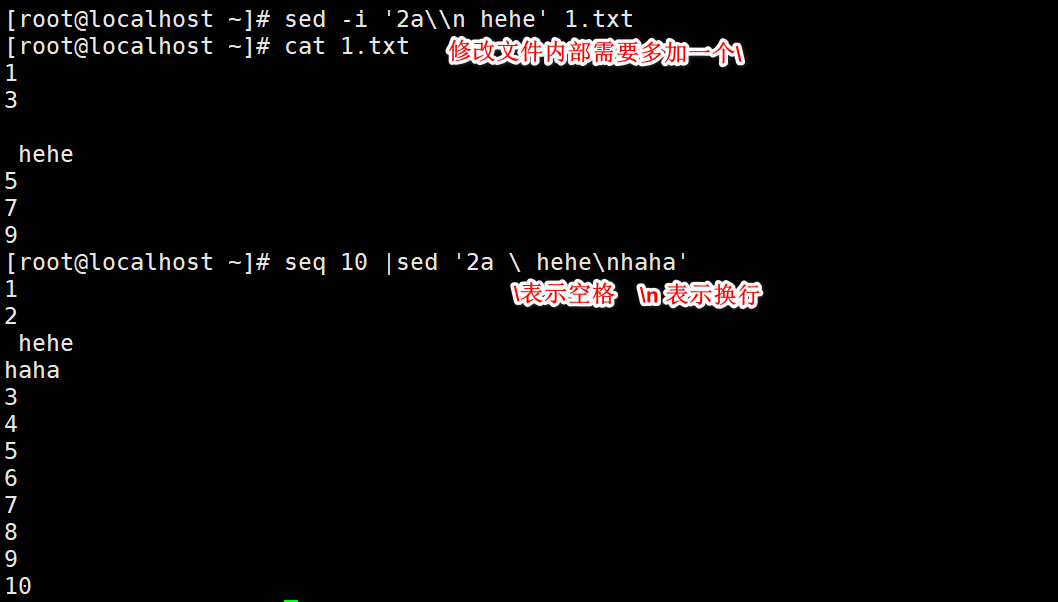
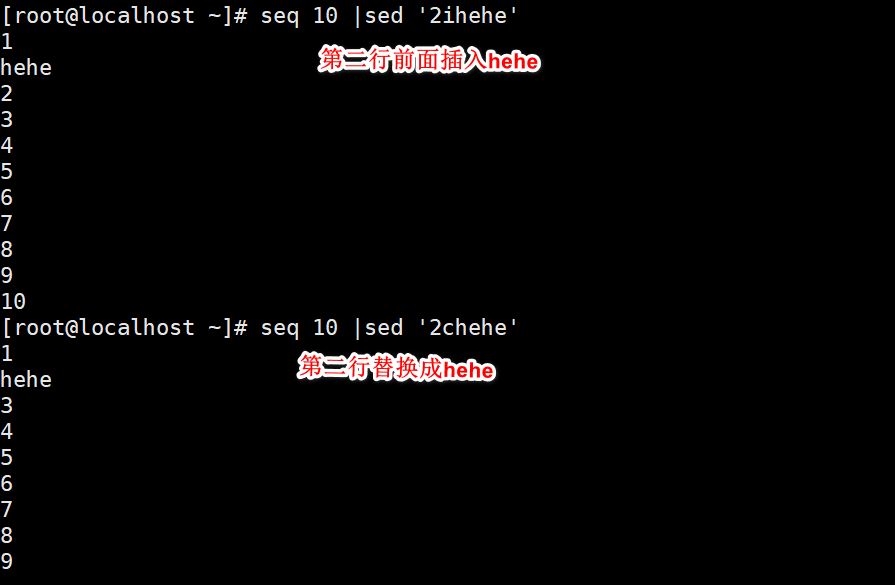
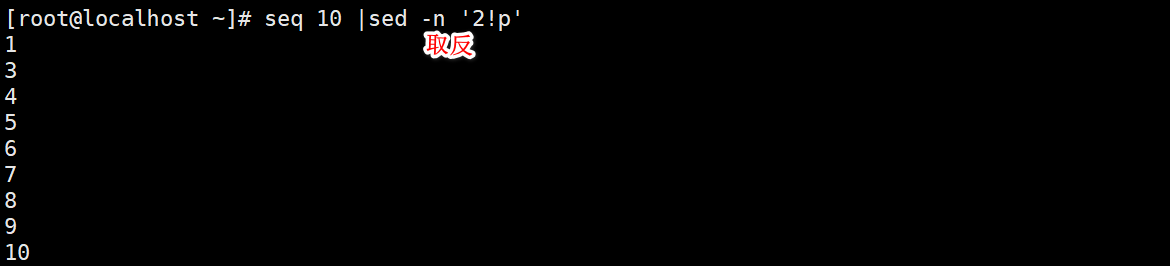
Search for alternatives
s/pattern/string/Modifier find replace,Other separators are supported, which can be in other forms: s@@@,s### Replace modifier: g Intra row global replacement p Displays the rows that have been replaced successfully w /PATH/FILE Save the successfully replaced line to a file I,i ignore case

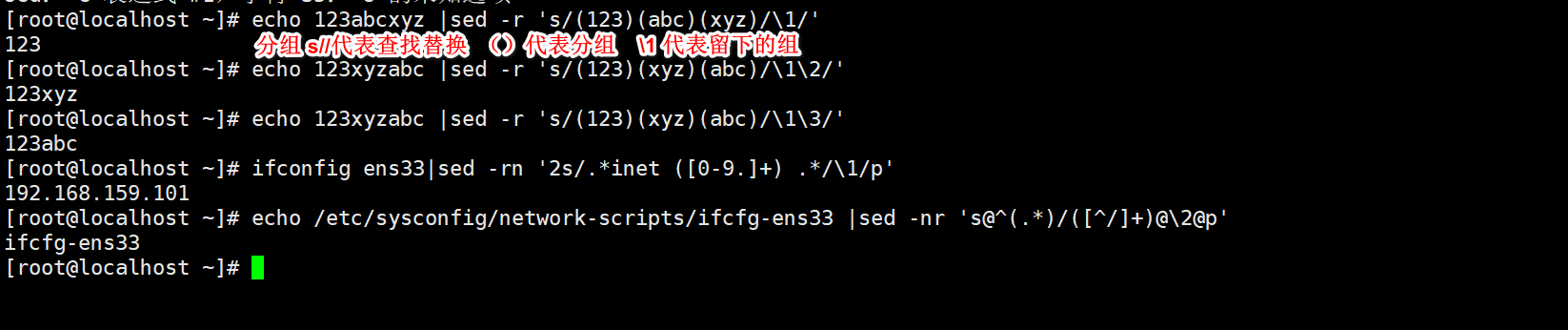
Change configuration file

AWK
In Linux/UNIX systems, awk is a powerful editing tool. It reads the input text line by line. By default, it is separated by a space or tab key, and executes editing commands according to patterns or conditions. Awk prefers to divide a line into multiple fields and then process them. The reading of awk information is also to find the matching pattern specified line by line to find the matching pattern that meets the conditions The content can be formatted and output or filtered, which can realize quite complex text operations without interaction. It is widely used in Shell scripts to complete various automatic configuration tasks.
Working principle: as mentioned earlier, the sed command is often used to process a whole line, while awk prefers to divide a line into multiple "fields" and then process them. By default, the field separator is a space or tab key. The awk execution results can be printed and displayed through the print function.
Format:
awk [option] 'Mode condition{operation}' File 1 file 2....
awk -f|-v Script file 1 file 2.....
pattern:
Unspecified means empty
/1/2/Represents a regular expression
Relational expressionBasic usage
Print it again



Get IP address

[root@localhost ~]#wc -l /etc/passwd
45 /etc/passwd
[root@localhost ~]#awk -F: '{print $0}' /etc/passwd
#$0 represents all elements
[root@localhost ~]#awk -F: '{print $1}' /etc/passwd
#Represents the first column
[root@localhost ~]#awk -F: '{print $1,$3}' /etc/passwd
#Represents the first and third columns
[root@localhost ky15]#awk '/^root/{print}' passwd
#A line beginning with root has been
[root@localhost ky15]#grep -c "/bin/bash$" passwd
#Counts the rows that currently end in / bin/bash
2
##### BEGIN {} mode means that the specified actions in BEGIN mode need to be executed before processing the specified text; awk then process the specified text, and then execute the specified actions in END mode. In END {} statements, statements such as print results are generally placed.
Common built-in variables in awk
FS: Specifies the field separator for each line of text. The default is space or tab stop. It works the same as "- F" - v "FS =:"
NF: the number of fields in the currently processed row
NR: line number (ordinal number) of the currently processed line
$0: the whole line content of the currently processed line
$n: the nth field (column n) of the current processing line
FILENAME: the name of the file being processed
Rs: line separator. When awk reads data from a file, it will cut the data into many records according to the definition of RS, while awk only reads one record at a time for processing. The default is \ n
FS
[root@localhost ky15]#awk -v FS=: '{print $1FS$3}' /etc/passwd
#Here FS is equivalent to a variable
[root@localhost ky15]#awk -F: '{print $1":"$3}' /etc/passwd
shell Variables in
[root@localhost ky15]#fs=":";awk -v FS=$fs '{print $1FS$3}' /etc/passwd
#Pass definition variable to FS
OFS
[root@localhost ky15]#fs=":";awk -v FS=$fs -v OFS="+" '{print $1,$3}' /etc/passwd
#Output separator
NF
[root@localhost ky15]#awk -F: '{print NF}' /etc/passwd
[root@localhost ky15]#awk -F: '{print $NF}' /etc/passwd
#Last field
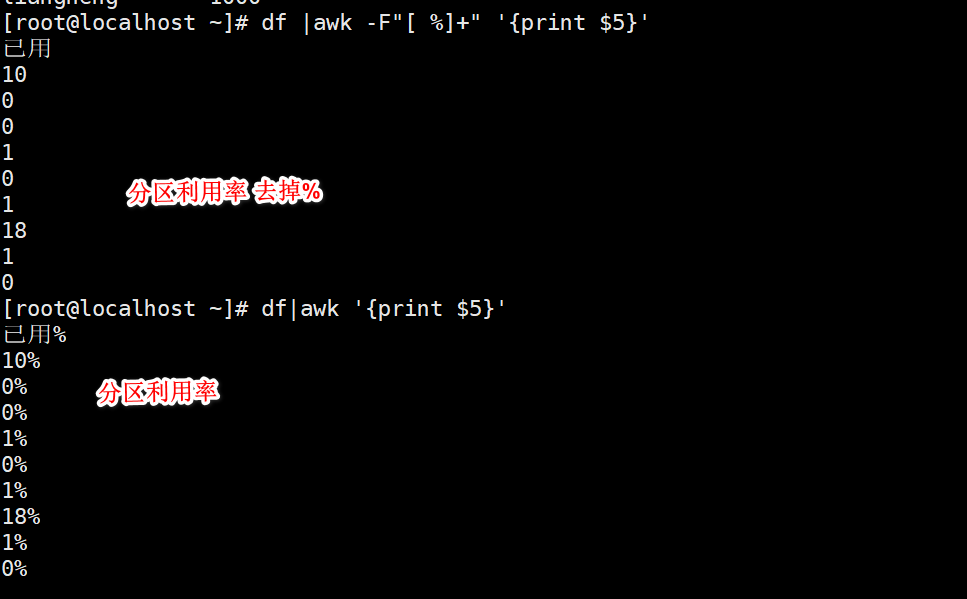
[root@localhost ky15]#df|awk -F: '{print $(NF-1)}'
#Penultimate line
[root@localhost ky15]#df|awk -F "[ %]+" '{print $(NF-1)}'
NR
[root@localhost ky15]#awk '{print $1,NR}' /etc/passwd
##Line number
[root@localhost ky15]#awk 'NR==2{print $1}' /etc/passwd
#Take only the first field of the second row
[root@localhost ky15]#awk 'NR==1,NR==3{print}' passwd
#Print out 1 to 3 lines
[root@localhost ky15]#awk 'NR==1||NR==3{print}' passwd
#Print out 1 and 3 lines
[root@localhost ky15]#awk '(NR%2)==0{print NR}' passwd
#Print out lines with function remainder of 0
[root@localhost ky15]#awk '(NR%2)==1{print NR}' passwd
#Print out the line with function remainder of 1
[root@localhost ky15]#awk 'NR>=3 && NR<=6{print NR,$0}' /etc/passwd
[root@localhost ky15]#seq 10|awk 'NR>5 && NR<10'
#Take between lines
6
7
8
9
[root@localhost ky15]#awk '$3>1000{print}' /etc/passwd