1, Background introduction
There are many split services in the distributed system. In the process of continuous iterative upgrading, the following common thorny situations will occur:
For the version upgrade of a technical component, depending on the package upgrade leads to the expiration of some syntax or API, or the component fixes urgent vulnerabilities, which will lead to the passive upgrade iteration of various services in the distributed system, which is easy to cause unexpected problems; Different services have different dependencies and versions on components, resulting in incompatibility problems. It is difficult to manage and maintain versions uniformly. Once problems occur, it is easy to rush and cause butterfly effect;
Therefore, in complex systems, unified management and secondary shallow encapsulation of dependent frameworks and components can greatly reduce the processing cost and risk of the above problems, and better manage and control the technology stack.
2, Frame shallow packaging
1. Shallow encapsulation
Why shallow encapsulation? The core purpose is to uniformly manage and coordinate the dependency and upgrading of components, and make a layer of packaging for common methods. In fact, many components do not use many function points, but there are many use points in the business, which brings some difficulties to the iterative upgrading of components themselves:
For example, if there is a huge risk vulnerability in the common API of a component, or the expired usage is replaced, the parts involved in the whole system need to be upgraded, and the cost of this operation is very high;
If this common component method is repackaged as a tool method for processing business, it is relatively easy to solve the above problems. As long as the encapsulated tool method and service dependency are upgraded, the time cost and risk can be reduced.
Two aspects of decoupling can be realized by means of shallow packaging:
Business and technology
Secondary shallow encapsulation is commonly used in the technology stack, which can greatly reduce the coupling between business and technology. In this way, the technology stack can be upgraded independently and the functions can be extended without affecting the iteration of business services.
Frames and components
Different frameworks and components need a certain degree of user-defined configuration. At the same time, they are managed by modules, and specific dependencies are introduced into different services. They can also be unified in the basic package, so as to realize the rapid combination of technology stacks.
Shallow encapsulation here refers to the syntax commonly used for packaging. The component itself is a deep encapsulation at the technical level, so it is impossible to completely separate the native usage of the technology stack.
2. Unified version control
For example, under the microservice architecture, different R & D groups are responsible for different business modules. However, affected by the experience and ability of developers, it is easy to choose different service components, or the same components depend on different versions, so it is difficult to uniformly manage the system architecture.
For the secondary packaging method, the iterative expansion of the technology stack and the problem of version conflict can be strictly controlled. Through the unified upgrade of the secondary packaging layer, the business service can be upgraded quickly and the dependency difference of different services can be solved.
3, Practical cases
1. Case introduction
In Java distributed system, microservice basic components (Nacos, Feign, Gateway, Seata) and system middleware (Quartz, Redis, Kafka, ElasticSearch, Logstash) carry out secondary shallow encapsulation and unified integrated management of common functions, configurations and API s, so as to meet the rapid implementation of basic environment construction and temporary tools in daily development.
- Application cases of Bute flyer component encapsulation;
- Secondary packaging of common technical components of Bute frame;
2. Layered architecture
It is divided into five layers as a whole: gateway layer, application layer, business layer, middleware layer and foundation layer, which are combined into a set of distributed system.
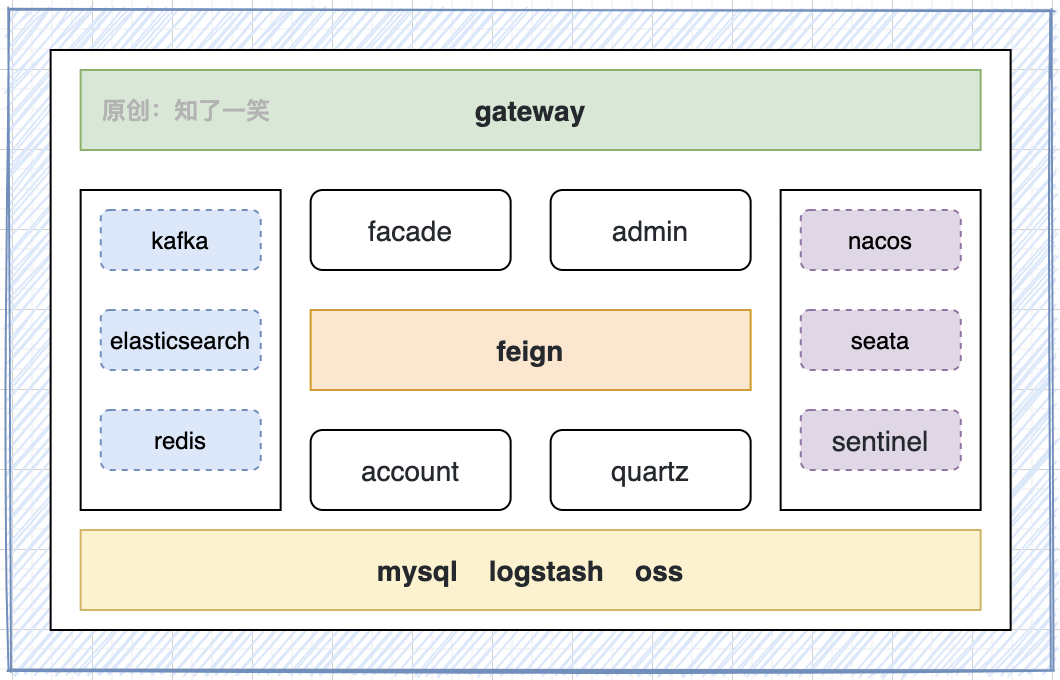
Service overview
| service name | layered | port | Cache Library | database | describe |
|---|---|---|---|---|---|
| flyer-gateway | Gateway layer | 8010 | db1 | nacos | Routing control |
| flyer-facade | application layer | 8082 | db2 | facade | Facade service |
| flyer-admin | application layer | 8083 | db3 | admin | Back end management |
| flyer-account | Business layer | 8084 | db4 | account | Account management |
| flyer-quartz | Business layer | 8085 | db5 | quartz | Timed task |
| kafka | middleware | 9092 | --- | ------ | Message queue |
| elasticsearch | middleware | 9200 | --- | ------ | Search Engines |
| redis | middleware | 6379 | --- | ------ | Cache Center |
| logstash | middleware | 5044 | --- | es6.8.6 | Log collection |
| nacos | Foundation layer | 8848 | --- | nacos | Registration configuration |
| seata | Foundation layer | 8091 | --- | seata | Distributed transaction |
| mysql | Foundation layer | 3306 | --- | ------ | data storage |
3. Directory structure
The secondary encapsulation management of each technology stack is carried out in the Bute frame, and the dependency reference is carried out in the Bute flyer.
butte-frame ├── frame-base Basic code block ├── frame-jdbc Database components ├── frame-core Service base dependency ├── frame-gateway Routing Gateway ├── frame-nacos Registration and configuration center ├── frame-seata Distributed transaction ├── frame-feign Inter service call ├── frame-security security management ├── frame-search Search Engines ├── frame-redis Cache management ├── frame-kafka Message Oriented Middleware ├── frame-quartz Timed task ├── frame-swagger Interface documentation └── frame-sleuth Link log butte-flyer ├── flyer-gateway Gateway service: routing control ├── flyer-facade Facade service: functional collaboration interface ├── flyer-account Account service: user account ├── flyer-quartz Task service: scheduled tasks └── flyer-admin Management service: back end management
4. Technology stack component
Common technology stacks of the system: basic framework, micro service components, cache, security management, database, scheduled tasks, tool dependencies, etc.
| name | edition | explain |
|---|---|---|
| spring-cloud | 2.2.5.RELEASE | Microservice framework Foundation |
| spring-boot | 2.2.5.RELEASE | Service base dependency |
| gateway | 2.2.5.RELEASE | Routing Gateway |
| nacos | 2.2.5.RELEASE | Registry and configuration management |
| seata | 2.2.5.RELEASE | Distributed transaction management |
| feign | 2.2.5.RELEASE | Request invocation between microservices |
| security | 2.2.5.RELEASE | security management |
| sleuth | 2.2.5.RELEASE | Request track link |
| security-jwt | 1.0.10.RELEASE | JWT encryption component |
| hikari | 3.4.2 | Database connection pool, default |
| mybatis-plus | 3.4.2 | ORM persistence layer framework |
| kafka | 2.0.1 | MQ message queue |
| elasticsearch | 6.8.6 | Search Engines |
| logstash | 5.2 | Log collection |
| redis | 2.2.5.RELEASE | Cache management and lock control |
| quartz | 2.3.2 | Scheduled task management |
| swagger | 2.6.1 | Interface documentation |
| apache-common | 2.7.0 | Basic dependency package |
| hutool | 5.3.1 | Basic Toolkit |
4, Microservice component
1,Nacos
In the whole component system, Nacos provides two core capabilities: adapting microservice registration and discovery standards, quickly realizing dynamic service registration and discovery, metadata management, etc., and providing the most basic capabilities in microservice components; Configuration center: uniformly manage various service configurations, centralize storage management in Nacos, isolate different configurations in multiple environments, and avoid the risk of online configuration liberalization;
Connection management
spring:
cloud:
nacos:
# Configure read
config:
prefix: application
server-addr: 127.0.0.1:8848
file-extension: yml
refresh-enabled: true
# Registration Center
discovery:
server-addr: 127.0.0.1:8848
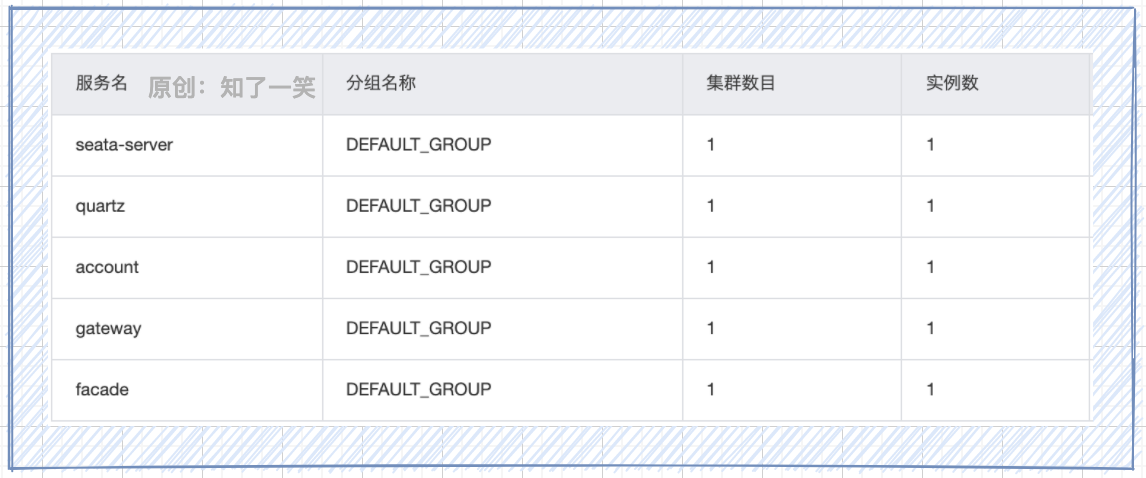
configuration management
- bootstrap.yml: file in the service, connect and read the configuration information in Nacos;
- application.yml: common basic configuration, where mybatis components are configured;
- application-dev.yml: middleware connection configuration, used as environment identification isolation;
- application-def.yml: user defined configuration of each service and parameter loading;
2,Gateway
Gateway is the core capability of gateway. It provides unified API routing management. As the only entry for requests under the microservice architecture, it can also handle all non business functions at the gateway layer, such as security control, traffic monitoring, current limiting, etc.
Routing control: discovery and routing of various services;
@Component
public class RouteFactory implements RouteDefinitionRepository {
@Resource
private RouteService routeService ;
/**
* Load all routes
* @since 2021-11-14 18:08
*/
@Override
public Flux<RouteDefinition> getRouteDefinitions() {
return Flux.fromIterable(routeService.getRouteDefinitions());
}
/**
* Add route
* @since 2021-11-14 18:08
*/
@Override
public Mono<Void> save(Mono<RouteDefinition> routeMono) {
return routeMono.flatMap(routeDefinition -> {
routeService.saveRouter(routeDefinition);
return Mono.empty();
});
}
}
Global filtering: as the basic capability of the gateway;
@Component
public class GatewayFilter implements GlobalFilter {
private static final Logger logger = LoggerFactory.getLogger(GatewayFilter.class);
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
String uri = request.getURI().getPath() ;
String host = String.valueOf(request.getHeaders().getHost()) ;
logger.info("request host : {} , uri : {}",host,uri);
return chain.filter(exchange);
}
}
3,Feign
Feign component is a declarative WebService client, which makes the invocation between microservices easier. Feign manages the requests through template and interface by annotation, which can manage the communication interaction between various services more standard.
Response decoding: define the decoding logic of Feign interface response, check and control the unified interface style;
public class FeignDecode extends ResponseEntityDecoder {
public FeignDecode(Decoder decoder) {
super(decoder);
}
@Override
public Object decode(Response response, Type type) {
if (!type.getTypeName().startsWith(Rep.class.getName())) {
throw new RuntimeException("Abnormal response format");
}
try {
return super.decode(response, type);
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e.getMessage());
}
}
}
4,Seata
Seata component is an open source distributed transaction solution, which is committed to providing high-performance and easy-to-use distributed transaction services, realizing AT, TCC, SAGA and XA transaction modes, and supporting one-stop distributed solutions.
Transaction configuration: manage parameter definitions of Seata components based on nacos;
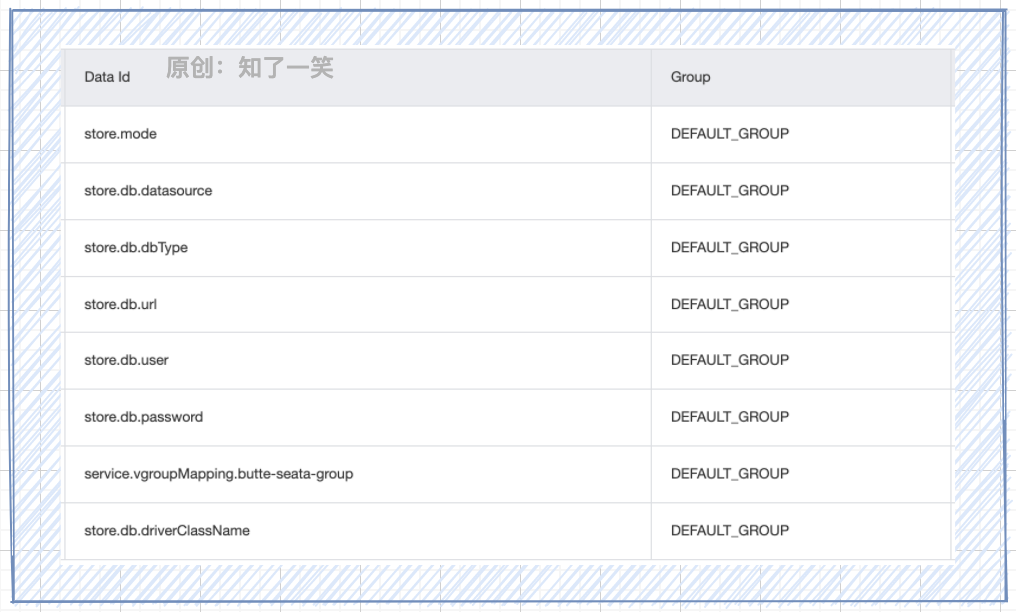
Service registration: connect and use Seata services in services that need to manage distributed transactions;
seata:
enabled: true
application-id: ${spring.application.name}
tx-service-group: butte-seata-group
config:
type: nacos
nacos:
server-addr: ${spring.cloud.nacos.config.server-addr}
group: DEFAULT_GROUP
registry:
type: nacos
nacos:
server-addr: ${spring.cloud.nacos.config.server-addr}
application: seata-server
group: DEFAULT_GROUP
5, Middleware integration
1,Kafka
Kafka is a distributed, partitioned, multi replica and multi subscriber distributed message processing platform coordinated by Zookeeper, which is open source by Apache. It is written in Scala and Java languages. It is also often used to collect log data generated by users in application services.
Message sending: encapsulates the basic capability of message sending;
@Component
public class KafkaSendOperate {
@Resource
private KafkaTemplate<String, String> kafkaTemplate ;
public void send (SendMsgVO entry) {
kafkaTemplate.send(entry.getTopic(),entry.getKey(),entry.getMsgBody()) ;
}
}
Message consumption: there are two strategies for consumption monitoring;
- The message producer consumes by itself and executes the logic of specific consumption services through the Feign interface, which is conducive to process tracking and troubleshooting;
- The message consumer can listen directly to reduce the process nodes of message processing. Of course, it can also create a unified MQ bus service (end of the article);
public class KafkaListen {
private static final Logger logger = LoggerFactory.getLogger(KafkaListen.class);
/**
* Kafka Message listening
* @since 2021-11-06 16:47
*/
@KafkaListener(topics = KafkaTopic.USER_TOPIC)
public void listenUser (ConsumerRecord<?,String> record, Acknowledgment acknowledgment) {
try {
String key = String.valueOf(record.key());
String body = record.value();
switch (key){ }
} catch (Exception e){
e.printStackTrace();
} finally {
acknowledgment.acknowledge();
}
}
}
2,Redis
Redis is an open source component, memory based high-performance key value data structure storage system. It can be used as database, cache and message middleware, and supports various types of data structures, such as string, set, etc. In practical applications, it is usually used to cache and lock hot data with low change frequency.
KV data cache: as the most commonly used function of Redis, it caches a key and value with a specified validity period, which can be obtained directly when used;
@Component
public class RedisKvOperate {
@Resource
private StringRedisTemplate stringRedisTemplate ;
/**
* To create a cache, you must take the cache duration
* @param key Cache Key
* @param value Cache Value
* @param expire Unit second
* @return boolean
* @since 2021-08-07 21:12
*/
public boolean set (String key, String value, long expire) {
try {
stringRedisTemplate.opsForValue().set(key,value,expire, TimeUnit.SECONDS);
} catch (Exception e){
e.printStackTrace();
return Boolean.FALSE ;
}
return Boolean.TRUE ;
}
}
Lock locking mechanism: Based on redislock registry in spring integration redis, realize distributed locking;
@Component
public class RedisLockOperate {
@Resource
protected RedisLockRegistry redisLockRegistry;
/**
* Try locking once, using the default time
* @param lockKey Lock Key
* @return java.lang.Boolean
* @since 2021-09-12 13:14
*/
@SneakyThrows
public <T> Boolean tryLock(T lockKey) {
return redisLockRegistry.obtain(lockKey).tryLock(time, TimeUnit.MILLISECONDS);
}
/**
* Release lock
* @param lockKey Unlock Key
* @since 2021-09-12 13:32
*/
public <T> void unlock(T lockKey) {
redisLockRegistry.obtain(lockKey).unlock();
}
}
3,ElasticSearch
Elasticsearch is a search server based on Lucene. It provides a distributed multi-user full-text search engine based on RESTful web interface. Elasticsearch is developed in Java and is a popular enterprise search engine.
Index management: index creation and deletion, structure addition and query;
Template method operation based on ElasticsearchRestTemplate;
@Component
public class TemplateOperate {
@Resource
private ElasticsearchRestTemplate template ;
/**
* Create indexes and structures
* @param clazz Annotation based class entity
* @return java.lang.Boolean
* @since 2021-08-15 19:25
*/
public <T> Boolean createPut (Class<T> clazz){
boolean createIf = template.createIndex(clazz) ;
if (createIf){
return template.putMapping(clazz) ;
}
return Boolean.FALSE ;
}
}
Native API operation based on RestHighLevelClient;
@Component
public class IndexOperate {
@Resource
private RestHighLevelClient client ;
/**
* Determine whether the index exists
* @return boolean
* @since 2021-08-07 18:57
*/
public boolean exists (IndexVO entry) {
GetIndexRequest getReq = new GetIndexRequest (entry.getIndexName()) ;
try {
return client.indices().exists(getReq, entry.getOptions());
} catch (Exception e) {
e.printStackTrace();
}
return Boolean.FALSE ;
}
}
Data management: data addition, primary key query, modification and batch operation. The complexity of business search encapsulation is very high;
Data addition, deletion and modification methods;
@Component
public class DataOperate {
@Resource
private RestHighLevelClient client ;
/**
* Batch update data
* @param entry Object body
* @since 2021-08-07 18:16
*/
public void bulkUpdate (DataVO entry){
if (CollUtil.isEmpty(entry.getDataList())){
return ;
}
// Request condition
BulkRequest bulkUpdate = new BulkRequest(entry.getIndexName(),entry.getType()) ;
bulkUpdate.setRefreshPolicy(entry.getRefresh()) ;
entry.getDataList().forEach(dataMap -> {
UpdateRequest updateReq = new UpdateRequest() ;
updateReq.id(String.valueOf(dataMap.get("id"))) ;
updateReq.doc(dataMap) ;
bulkUpdate.add(updateReq) ;
});
try {
// Execute request
client.bulk(bulkUpdate, entry.getOptions());
} catch (IOException e) {
e.printStackTrace();
}
}
}
Index primary key query, grouping query method;
@Component
public class QueryOperate {
@Resource
private RestHighLevelClient client ;
/**
* Specify field grouping query
* @since 2021-10-07 19:00
*/
public Map<String,Object> groupByField (QueryVO entry){
Map<String,Object> groupMap = new HashMap<>() ;
// Grouping API
String groupName = entry.getGroupField()+"_group" ;
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(0) ;
TermsAggregationBuilder termAgg = AggregationBuilders.terms(groupName)
.field(entry.getGroupField()) ;
sourceBuilder.aggregation(termAgg);
// Query API
SearchRequest searchRequest = new SearchRequest(entry.getIndexName());
searchRequest.source(sourceBuilder) ;
try {
// Execution API
SearchResponse response = client.search(searchRequest, entry.getOptions());
// Response results
Terms groupTerm = response.getAggregations().get(groupName) ;
if (CollUtil.isNotEmpty(groupTerm.getBuckets())){
for (Terms.Bucket bucket:groupTerm.getBuckets()){
groupMap.put(bucket.getKeyAsString(),bucket.getDocCount()) ;
}
}
} catch (IOException e) {
e.printStackTrace();
}
return groupMap ;
}
}
4,Logstash
Logstash is an open source data acquisition component with real-time pipeline function. Logstash can dynamically collect data from multiple sources, standardize data conversion, and transfer data to the selected storage container.
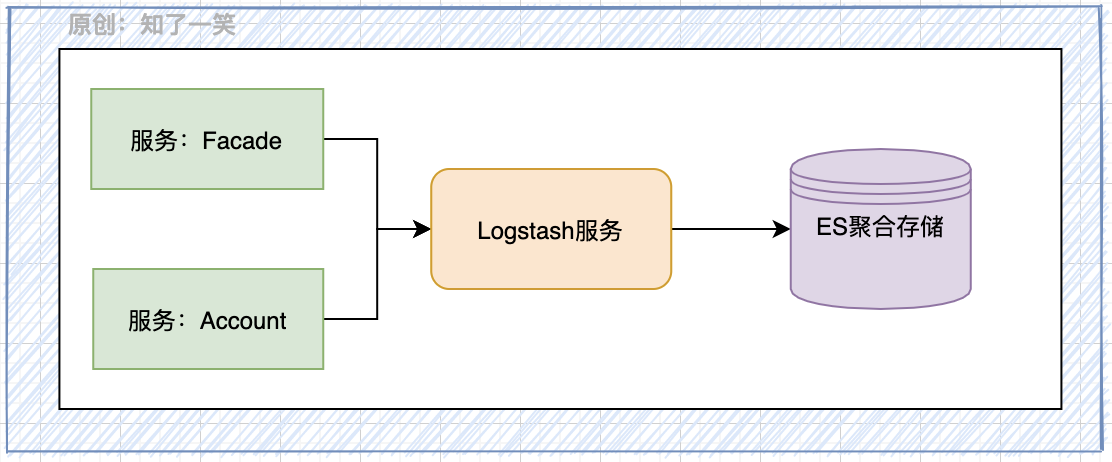
- Sleuth: manage service links and provide core TraceId and SpanId generation;
- Elastic search: aggregate, store and query logs based on ES engine;
- Logstash: provides log collection services and the ability to send data to ES;
logback.xml: the service connects the Logstash address and loads the core configuration;
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml" />
<springProperty scope="context" name="APP_NAME" source="spring.application.name" defaultValue="butte_app" />
<springProperty scope="context" name="DES_URI" source="logstash.destination.uri" />
<springProperty scope="context" name="DES_PORT" source="logstash.destination.port" />
<!-- Output to LogStash Configuration, startup required LogStash service -->
<appender name="LogStash"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>${DES_URI:- }:${DES_PORT:- }</destination>
<encoder
class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${APP_NAME:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
</configuration>
5,Quartz
Quartz is an open source job scheduling framework written entirely in java, which is used to perform scheduled scheduling tasks in various services. Under the microservice architecture, an independent quartz service is usually developed to trigger the task execution of various services through the Feign interface.
Configuration parameters: basic information of scheduled task, database table and thread pool;
spring:
quartz:
job-store-type: jdbc
properties:
org:
quartz:
scheduler:
instanceName: ButteScheduler
instanceId: AUTO
jobStore:
class: org.quartz.impl.jdbcjobstore.JobStoreTX
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: qrtz_
isClustered: true
clusterCheckinInterval: 15000
useProperties: false
threadPool:
class: org.quartz.simpl.SimpleThreadPool
threadPriority: 5
threadCount: 10
threadsInheritContextClassLoaderOfInitializingThread: true
6,Swagger
Swagger is a commonly used interface document management component. It can quickly generate interface description information through simple annotation of API interfaces and objects, and provides a visual interface, which can quickly send requests and debug the interface. This component greatly improves the efficiency in front and rear joint debugging.
Configure basic packet scanning capability;
@Configuration
public class SwaggerConfig {
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("com.butte"))
.paths(PathSelectors.any())
.build();
}
}
Access: Service: port / swagger-ui.html to open the interface document;

6, Database configuration
1,MySQL
Under the microservice architecture, different services correspond to different MySQL libraries. The division of databases based on business modules is a commonly used method at present. The services under their respective businesses can be iteratively upgraded, and the avalanche effect caused by a single point of failure can be avoided.

2,HikariCP
As the recommended and default database connection pool for spring boot 2, HikariCP has the characteristics of extremely fast speed, light weight and simplicity.
spring:
datasource:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/${data.name.mysql}?${spring.datasource.db-param}
username: root
password: 123456
db-param: useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
hikari:
minimumIdle: 5
maximumPoolSize: 10
idleTimeout: 300000
maxLifetime: 500000
connectionTimeout: 30000
The configuration of the connection pool can be properly tuned according to the concurrent requirements of the business.
3,Mybatis
The framework component of mybatis persistence layer supports customized SQL, stored procedures and advanced mapping. Mybatis plus is an enhancement tool for mybatis. On the basis of mybatis, only enhancement is made without change, which can simplify development and improve efficiency.
mybatis-plus:
mapper-locations: classpath*:/mapper/**/*.xml
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
7, Source code address
Application warehouse: https://gitee.com/cicadasmile/butte-flyer-parent Component encapsulation: https://gitee.com/cicadasmile/butte-frame-parent
