Now that we have written the fifth chapter, Jira's official system is actually getting farther and farther away. The content of this chapter has basically been completely separate from Jira itself, and has relied on Jira's API interface and database for development.It mainly contains the following functions:
- Personnel Task Scheduling Management
- Historic Task Scheduling Check
- BI Report
Be careful:
Since our secondary development is basically static pages, Jira's API interface is used extensively for ease of use.So we put these pages in Jira's container and set up a directory there.This allows you to share the same domain name as Jira, and no additional authentication is required for the access interface as long as the Jira system is logged in.
Personnel Task Scheduling Management
background
The requirement for this page is actually derived from BigGantt, a very powerful plug-in that we mentioned earlier and is very helpful for iterative task management.
But slowly, a management scenario emerged: a key project occupies part of the R&D force, which requires an understanding of the task schedule.And when the task changes, you can quickly see if there are R&D resources to schedule adjustments.
After analysis, we learned that there are actually two main points to this requirement: one is to have a list of tasks (usually a list of chief tasks filtered out by a JQL statement), and the other is to have a list of human resources and subtasks involved.Is BigGantt satisfied?It can filter out task lists based on JQL, but this list can only be expanded from a task perspective.When we need to evaluate how a person is scheduled and whether they can be inserted or adjusted, there is not a very good interface to present clearly.
Realization
So we designed the following functions: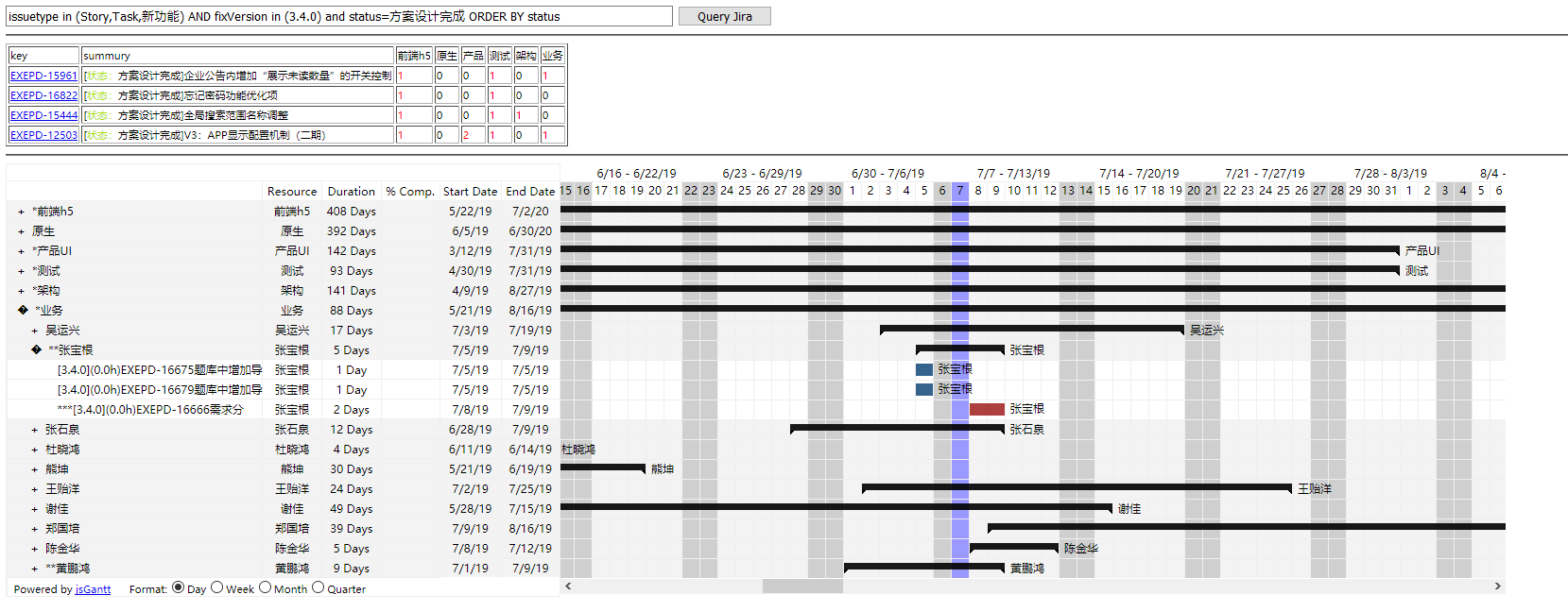
You can see that the interface is divided into three parts
The first part is a text input box for executing JQL statements.
The second part is the list of directors.
The third part is the human resources Gantt chart.
Task list passed
https://jira.yourdomain.com/rest/api/2/search?jql=' + jqlstr + '&maxResults=9999
The interface can get the json data for the task.
The Human Resources Gantt Chart is a python script written to launch a web container that reads data from Jira's underlying database and the organization returns json.What you get is sub-tasks that all R&D center staff have not completed.Why use python?Because Jira doesn't have other containers on this server, it's too cumbersome to install something like tomcat, make an mvc framework, or write jsp directly.
The sql to get the data is given below:
select concat(a.id) as pissueId,
ifnull(concat("EXEPD-", k.issuenum),"No Parent Task") as pikey,
k.SUMMARY as pisummary,
concat("EXEPD-", a.issuenum) as ikey,
'Subtasks' as itype,
a.SUMMARY,
b.pname,
ifnull(ifnull(i.vname, e.customvalue), 'Version is empty') as vname,
ac.last_name,
ad.lower_parent_name,
(case ad.lower_parent_name
when 'org-pd-qa' then 'test'
when 'org-pd-frontside-h5' then 'Front end h5'
when 'org-pd-frontside-native' then 'Native'
when 'org-pd-serverside-b' then 'business'
when 'org-pd-serverside-a' then 'Framework'
when 'org-pd-product' then 'product UI'
else '' end) as deptname,
DATE_FORMAT(a.CREATED,'%Y-%m-%d') as creatdate,
DATE_FORMAT(a.DUEDATE,'%m/%d/%Y') as enddate,
DATE_FORMAT(cd.DATEVALUE,'%m/%d/%Y') as startdate,
concat(ab.ID) as asid,
concat(ad.parent_id) as dpid,
concat(ROUND(ifnull(a.TIMESPENT,0) / 3600, 1)) as timespent,
ab.lower_user_name asname,
1 as nums
from jiraissue a
join app_user ab on ab.user_key = a.ASSIGNEE
join cwd_user ac on ac.lower_user_name = ab.lower_user_name
join cwd_membership ad on ad.lower_child_name = ab.lower_user_name and ad.lower_parent_name in
('org-pd-frontside-h5',
'org-pd-frontside-native',
'org-pd-serverside-a',
'org-pd-serverside-b',
'org-pd-qa',
'org-pd-product')
join issuestatus b on b.ID = a.issuestatus
left join nodeassociation f on f.SOURCE_NODE_ID = a.ID and f.ASSOCIATION_TYPE = 'IssueFixVersion'
left join projectversion i on i.ID = f.SINK_NODE_ID
left join customfield c on c.cfname = 'Correction Status'
left join customfieldvalue d on d.CUSTOMFIELD = c.id and d.ISSUE = a.ID
left join customfieldoption e on e.CUSTOMFIELD = c.ID and e.id = d.STRINGVALUE
left join customfieldvalue dd on dd.CUSTOMFIELD = 10400 and dd.ISSUE = a.ID
left join customfieldoption de on de.CUSTOMFIELD = 10400 and de.id = dd.STRINGVALUE
left join customfield cc on cc.cfname = 'Start Date'
left join customfieldvalue cd on cd.CUSTOMFIELD = cc.id and cd.ISSUE = a.ID
left join issuelink j on j.DESTINATION = a.ID
left join jiraissue k on k.ID = j.SOURCE
where a.issuetype = 10003
and a.PROJECT = 10000
and a.issuestatus != 10001
and a.PRIORITY<=5
order by ad.lower_parent_name,ac.last_name,cd.DATEVALUE
This involves understanding the Jira database. Jira issue is the issue library, app_user is the people library, cwd_membership is the grouping library, and customfield, customfield option, customfield value are three sets of custom fields.This statement cannot be used directly on any Jira system because there are many custom settings rules.
For example, we added two custom fields, Start Date and Amendment Status, and defined a priority that is ignored in the current management panel (so there is a PRIORITY<=5 condition).
With a list of tasks and a list of human resources, we need to combine them.
The first Gantt plugin we used was JSGantt This plugin is still simple.Our Gantt chart has three layers, the first is departments, the second is people, and the third is tasks.In order to clearly show the relationship between the Gantt chart and the task, we cycle through the subtasks of all people. When the parent task is in the second part of the task list, an asterisk is placed on the title of the first layer, two asterisks are placed on the second layer, three asterisks are placed on the third layer, and the Gantt chart of the task is shown in red.In addition to not being able to drag and drop modifications to the task schedule, this is basically what we've been saying.This diagram has also become the most important tool I use to check iterations and people's schedules at the moment.
Historic Task Scheduling Check
background
Everyone's tasks are rolling, and each person is faced with at least four tasks each day:
- Planned Tasks (Long Term)
- Insertible tasks (long or short term, urgent)
- Online Problems (Critical Emergency Short Term)
- Bug problem (important not urgent)
Therefore, to manage R&D resources as managers, it is necessary to properly coordinate the task arrangement, and at the same time, it is necessary to analyze the situation of task changes and put forward the improvement needs for internal personnel or external demand units.
Realization
This is a management requirement, based on the perspective of people, to observe and analyze the change of a person's task over a period of time.
Since the interval of observation is uncertain, we cache each person's daily uncompleted subtasks and aggregate the subtasks for the specified time interval according to the page requirements.
Give the final result first: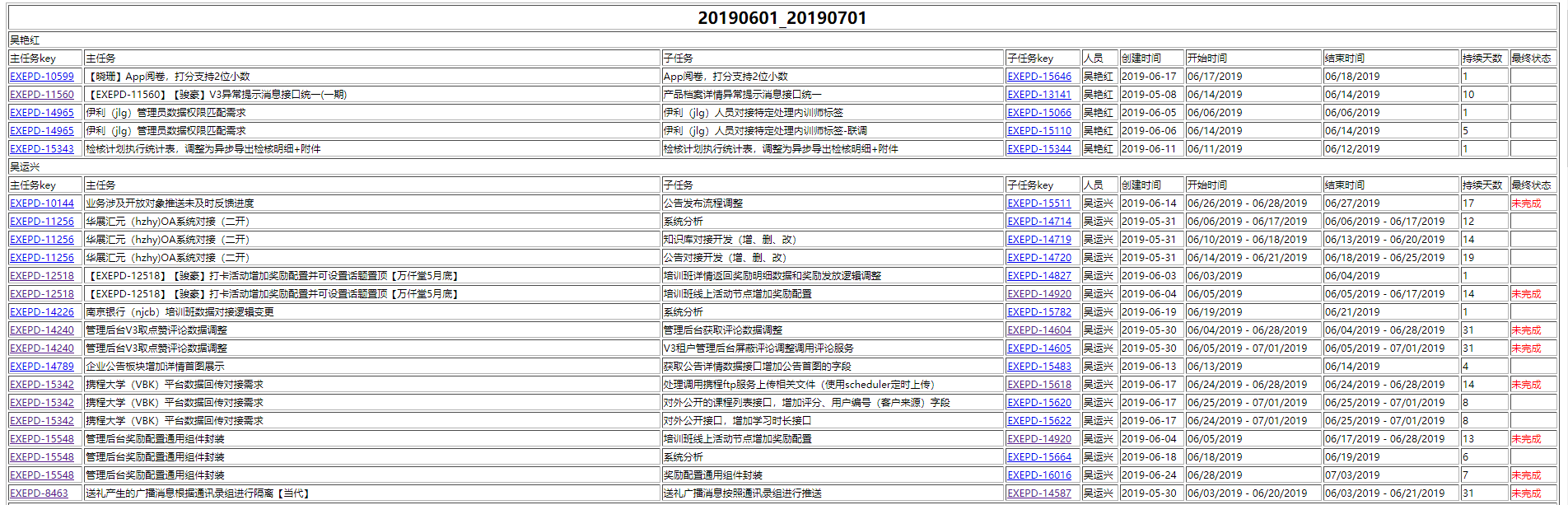
What we want to do:
- Timed tasks are used to save incomplete subtasks on a daily basis
- Background services query and aggregate task information based on front-end incoming conditions
- Front End Display
Timed tasks use python as a script, crontab as a morning execution, each time a new table is saved with a date as the table name. The script actually uses sql in the personnel task scheduling management, and OK is wrapped up with create table z_subtask_%date ().
The server also uses the web service started by python above to add an interface.
The primary perspective of the final interface is people, and the fields include:
- Head and sub-task information
- When to create (confirm when to receive tasks)
- Start and end dates, a date if the date has never changed, and a date interval if there are adjustments
- Days of duration refers to how many days the task has been cached in the library, that is, how many days have passed since the new task was created
- Final status refers to whether the task is completed by the query deadline
In this way, we can basically analyze the planned and delayed nature of a person's tasks, communicate and understand the causes, and formulate appropriate optimization plans.
BI
background
Every organization must have an analytical need. Whether it is internal improvement or overall reporting, having a complete presentation of charts and data tables is the most basic requirement.This requirement was first attempted in Jira's plug-ins, but a number of plug-in discoveries failed to achieve the desired results, ultimately moving to a third-party BI framework where the underlying data sources are organized themselves.
Realization
The QuickBI of Ali Cloud is selected.
Show part of the effect:
Hour Dimension BI Report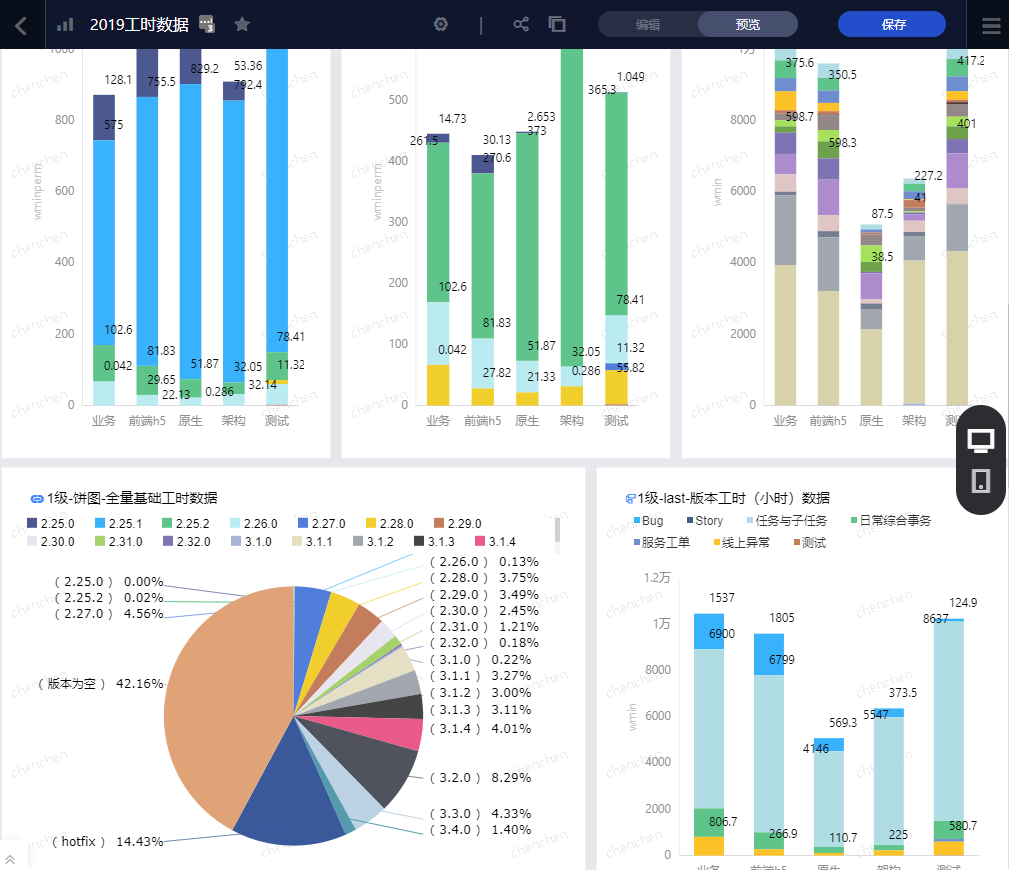
Iterative Task Analysis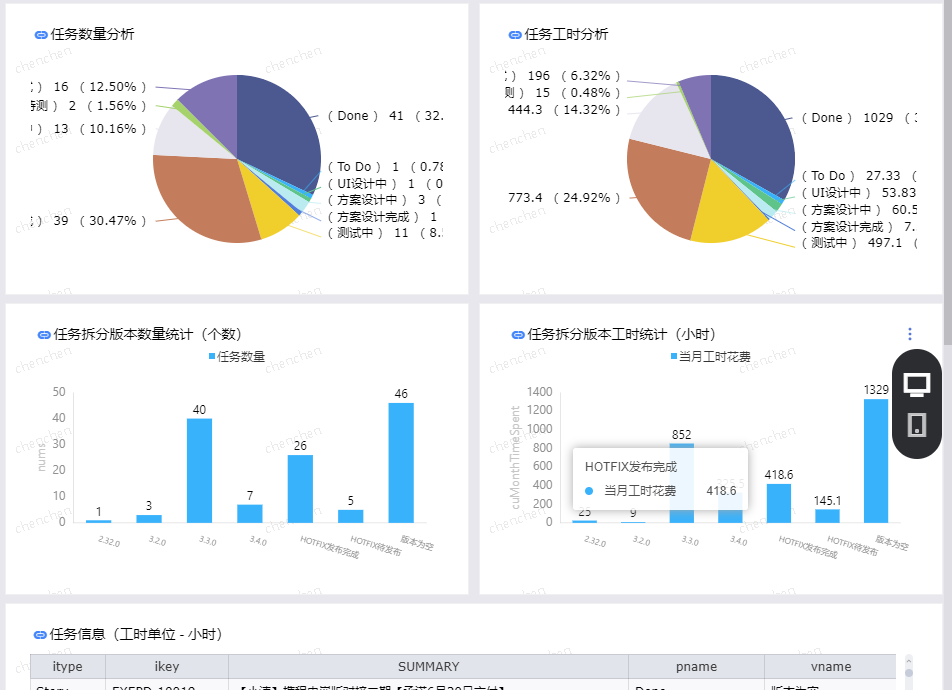
With BI tools, there are actually no big constraints on what a report is made of.The analysis is mainly focused on the two parts of work and iteration task.
I'll give you two examples of sql referencing Jira's underlying database for organizing data:
Iteration Task Organization:
select concat('C_', a.id) as pissueId,
concat("EXEPD-", a.issuenum) as ikey,
k.pname as itype,
a.SUMMARY,
sum((ifnull(a.TIMESPENT, 0) + ifnull(j.TIMESPENT, 0)) / 3600) as allTimeSpent,
sum(ifnull(ll.timeworked, 0)) / 3600 as cuMonthTimeSpent,
b.pname,
ifnull(ifnull((case when i.vname='hotfix' then null else i.vname end) , e.customvalue), 'Version is empty') as vname,
1 as nums
from jiraissue a
join issuestatus b on b.ID = a.issuestatus
left join nodeassociation f on f.SOURCE_NODE_ID = a.ID and f.ASSOCIATION_TYPE = 'IssueFixVersion'
left join projectversion i on i.ID = f.SINK_NODE_ID
left join customfield c on c.cfname = 'Correction Status'
left join customfieldvalue d on d.CUSTOMFIELD = c.id and d.ISSUE = a.ID
left join customfieldoption e on e.CUSTOMFIELD = c.ID and e.id = d.STRINGVALUE
left join issuelink g on g.SOURCE = a.ID and g.LINKTYPE = 10100
left join jiraissue j on j.ID = g.DESTINATION
join issuetype k on k.id = a.issuetype
left join (select l.issueid, sum(ifnull(l.timeworked, 0)) as timeworked
from worklog l
where date_format(l.STARTDATE, '%Y-%m') = '2019-06'
group by l.issueid) ll on ll.issueid = j.ID
where a.issuenum in (1,2,3,4)
and a.PROJECT = 10000
group by a.IDWork analysis:
select a.id,
a.issueid,
concat('C_', ifnull(n.SOURCE, a.id)) as pissueId,
a.worklogbody,
(a.timeworked / 3600) as wmin,
(a.timeworked / 3600 / (case d.lower_parent_name
when 'org-pd-qa' then 10
when 'org-pd-frontside-h5' then 9
when 'org-pd-frontside-native' then 5
when 'org-pd-serverside-b' then 12
when 'org-pd-serverside-a' then 7
when 'org-pd-product' then 9
else '' end)) as wminperm,
date_format(a.STARTDATE, '%Y-%m-%d') as sdate,
date_format(a.STARTDATE, '%Y-%m') as sdm,
c.last_name,
(case d.lower_parent_name
when 'org-pd-qa' then 'test'
when 'org-pd-frontside-h5' then 'Front end h5'
when 'org-pd-frontside-native' then 'Native'
when 'org-pd-serverside-b' then 'business'
when 'org-pd-serverside-a' then 'Framework'
when 'org-pd-product' then 'product UI'
else '' end) as deptname,
k.pname,
concat(h.pkey, '-', e.issuenum) as issuekey,
concat('https://jira.exexm.com/browse/', h.pkey, '-', e.issuenum) as issueurl,
(case j.pname when 'Sub-task' then 'Tasks and Subtasks' when 'Task' then 'Tasks and Subtasks' else j.pname end) as issuetypename,
-- (case j.pname when 'Sub-task' then 'Subtasks' when 'Task' then 'task' else j.pname end) as issuetypename,
e.SUMMARY,
-- ifnull(ifnull(i.vname, ifnull(m.customvalue,mm.customvalue)), 'Version is empty') as vname,
i.vname,
(case
when
(i.vname is null and (l.STRINGVALUE is not null or ll.STRINGVALUE is not null))
then 'hotfix'
when
(i.vname is null or i.vname='')
then 'Version is empty'
when
a.issueid = 10752
then 'Daily business'
when
a.issueid = 18019
then 'Extraplanning'
else i.vname end) as cord
from worklog a
join app_user b on b.user_key = a.AUTHOR
join cwd_user c on c.lower_user_name = b.lower_user_name
join cwd_membership d on d.lower_child_name = b.lower_user_name and d.lower_parent_name in
('org-pd-frontside-h5',
'org-pd-frontside-native',
'org-pd-serverside-a',
'org-pd-serverside-b',
'org-pd-qa',
'org-pd-product')
join jiraissue e on e.ID = a.issueid
left join nodeassociation f on f.SOURCE_NODE_ID = e.ID and f.ASSOCIATION_TYPE = 'IssueFixVersion'
left join projectversion i on i.ID = f.SINK_NODE_ID
join issuetype j on j.id = e.issuetype
join project h on h.ID = e.PROJECT
left join issuelink n on n.DESTINATION = e.ID and n.LINKTYPE = 10100
join issuestatus k on k.ID = e.issuestatus
left join customfieldvalue l on l.CUSTOMFIELD = 10025 and l.ISSUE = n.SOURCE
left join customfieldoption m on m.CUSTOMFIELD = 10025 and m.id = l.STRINGVALUE
left join customfieldvalue ll on ll.CUSTOMFIELD = 10025 and ll.ISSUE = e.ID
left join customfieldoption mm on mm.CUSTOMFIELD = 10025 and mm.id = ll.STRINGVALUE
where a.STARTDATE >= '2019-1-1'
order by a.STARTDATE ascsummary
At this point, all the tidying up of Jira's use is now complete.But this should only be a phased milestone. Our organizational structure is progressing, our process management methods are progressing, and Atlassian is progressing, so we can't stop.Jira is just one part of the complete ecosystem, and we need to better organize our R&D team, followed by some partners.For an enterprise and R&D team to survive and improve for a long time, it needs to accumulate, but it can not be passed on orally, but also can be combed and improved in stages.The next chapter is how enterprises use Confluence to accumulate knowledge.