subject
Given a large file (1T? 10T), in which each line stores a user's ID (IP? IQ?) , your computer has only 2G memory, please find the ten IDS with the highest frequency
introduce
In recent years, the TopK problem has been the most, the most and the most in the field test
In fact, the answer is relatively simple
- stand-alone
- Limited memory
- File is too large.
In such an environment, use the following ideas to solve it
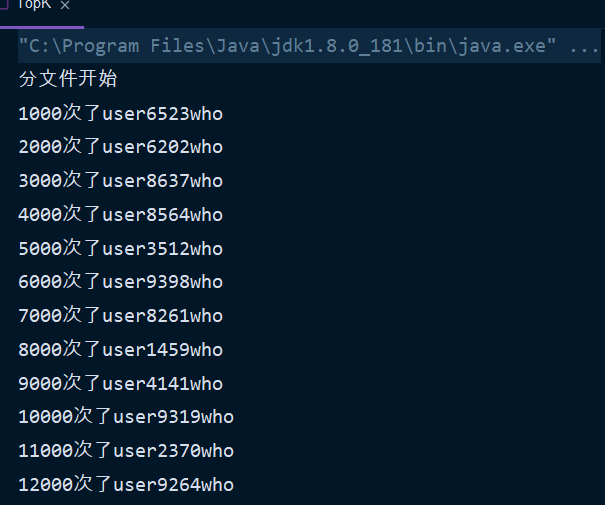
- Read large file by line
- Hash sub file
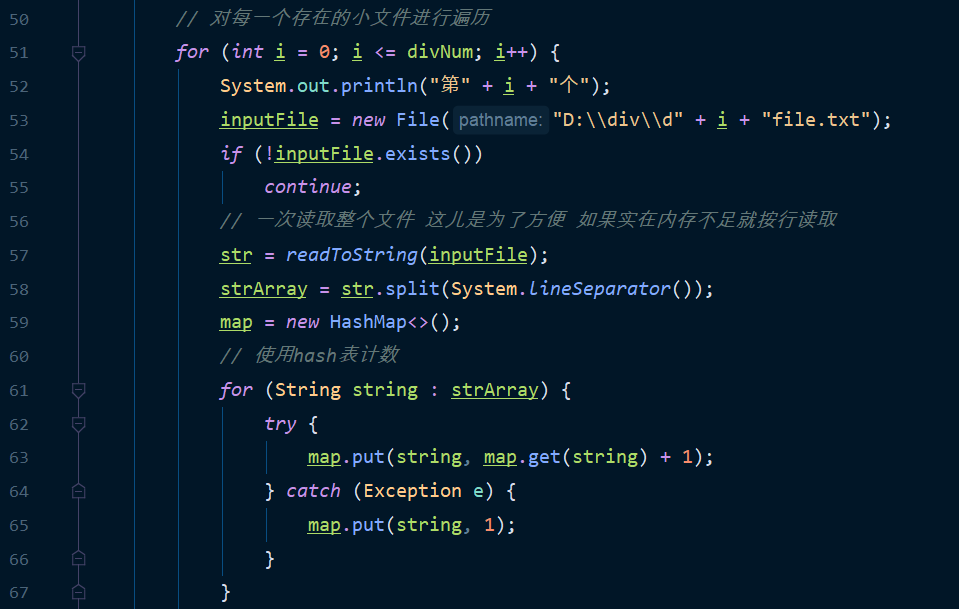
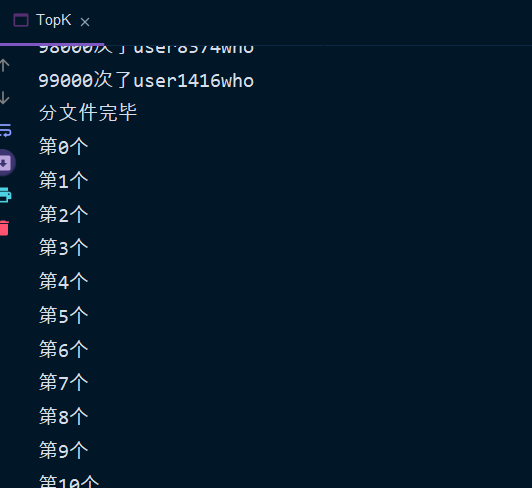
- Read a single small file
- Use map count
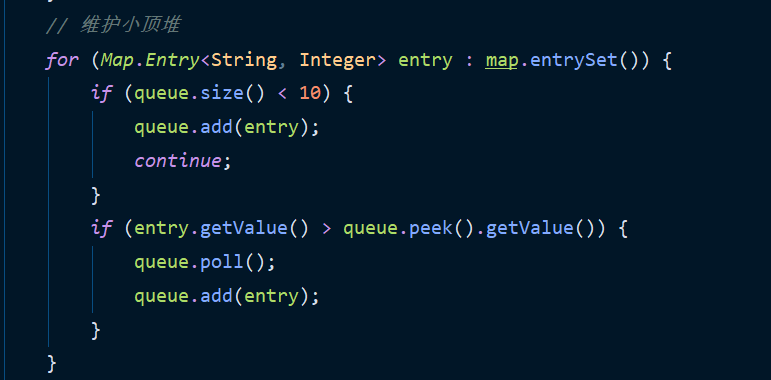
- Maintenance of small top reactor
Create use cases
First, make some use cases for testing
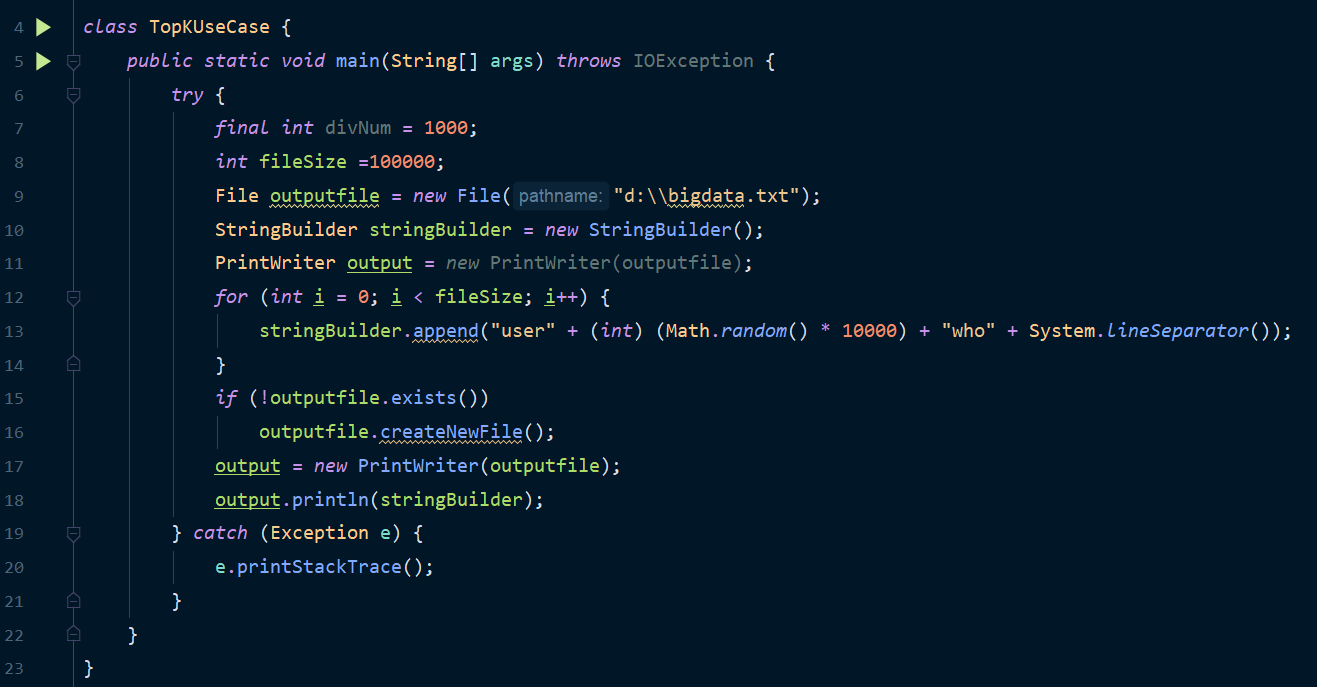
This is to create 100000 strings, because the amount of data is not much and the running time is a little long
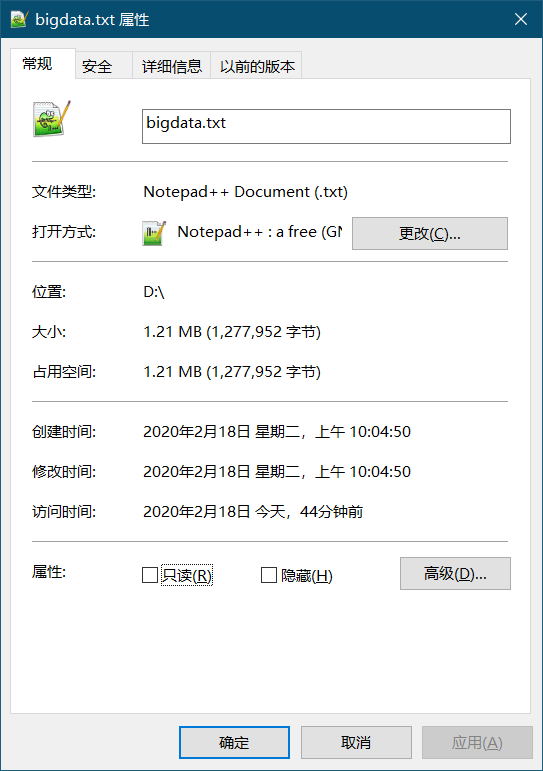
The generated file size is shown in the figure
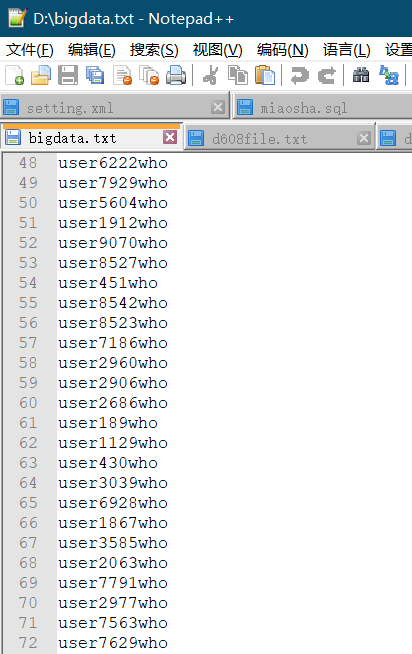
The generated data is shown in the figure
Read and split files by line
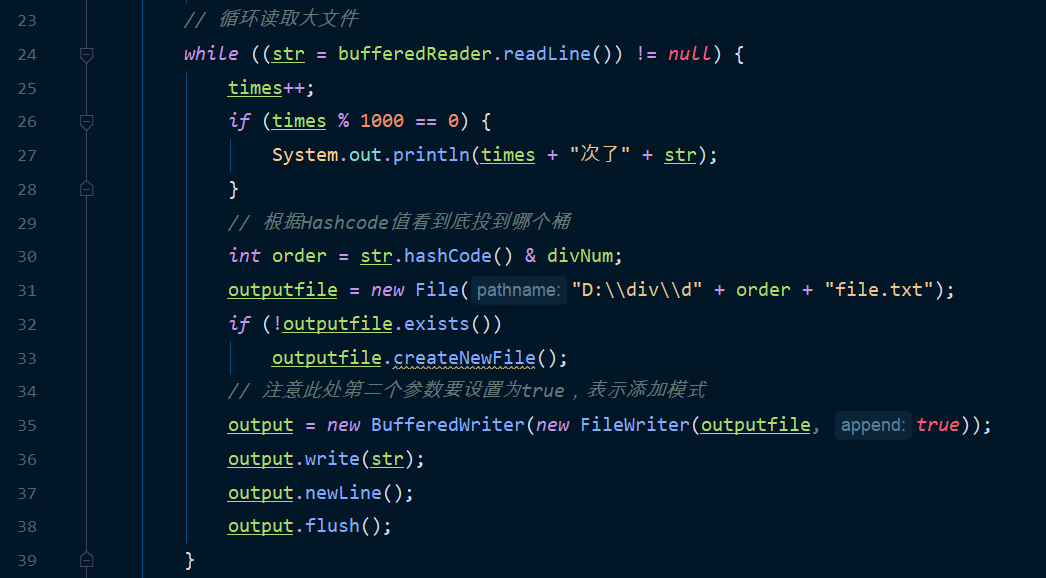
This piece of code should be ok?
Logic is
- Read by line
- Print the process every 1000 lines
- Bucket according to Hashcode value
- Writes to the specified file in append mode
In this way, theoretically, we can get 1000 strings containing the same hashcode modulus value
That is, all the same strings are in one file
count
A single file can be saved by the system, so long as you count these strings and put the key values into a hashmap
Maintenance of small top reactor
After one traverse, you can put the count into the small top heap, so that you can complete the sorting only by maintaining a small top heap of k size
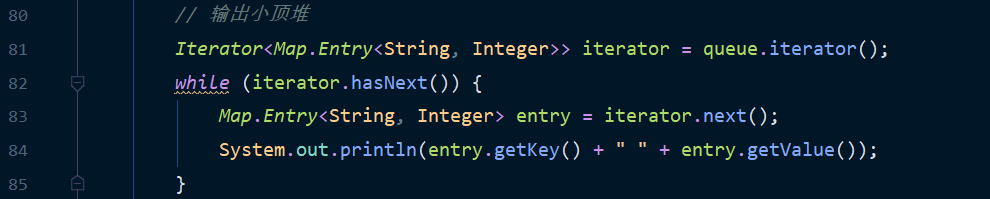
output
Finally, output the contents of the small top heap
Better solution
If you can use hadoop for multiple computers, you can split the files into multiple files, count the map separately, count the reduction uniformly, and then use the small top heap to find the topk
But the interviewer will not be allowed to operate XD in this way
appendix
TopK use case generation
import java.io.*; import java.util.*; class TopKUseCase { public static void main(String[] args) throws IOException { try { final int divNum = 1000; int fileSize =100000; File outputfile = new File("d:\\bigdata.txt"); StringBuilder stringBuilder = new StringBuilder(); PrintWriter output = new PrintWriter(outputfile); for (int i = 0; i < fileSize; i++) { stringBuilder.append("user" + (int) (Math.random() * 10000) + "who" + System.lineSeparator()); } if (!outputfile.exists()) outputfile.createNewFile(); output = new PrintWriter(outputfile); output.println(stringBuilder); } catch (Exception e) { e.printStackTrace(); } } }
TopK code
import java.awt.*; import java.io.*; import java.util.*; class TopK { public static void main(String[] args) throws IOException { final int divNum = 1000; // How many files are divided in advance according to the given conditions // Read large files by line File inputFile = new File("d:\\bigdata.txt"); FileInputStream inputStream = new FileInputStream(inputFile); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream)); String str = null; // Output small file File outputfile; BufferedWriter output; // Count is used to print logs int times = 0; System.out.println("Sub file start"); // Create directory File menu = new File("D:\\div"); if (!menu.exists()) menu.mkdirs(); // Circular reading of large files while ((str = bufferedReader.readLine()) != null) { times++; if (times % 1000 == 0) { System.out.println(times + "Times" + str); } // According to the Hashcode value, which bucket to throw int order = str.hashCode() & divNum; outputfile = new File("D:\\div\\d" + order + "file.txt"); if (!outputfile.exists()) outputfile.createNewFile(); // Note that the second parameter here should be set to true, indicating the adding mode output = new BufferedWriter(new FileWriter(outputfile, true)); output.write(str); output.newLine(); output.flush(); } System.out.println("File splitting completed"); // Create small top heap and hash table String[] strArray; Map<String, Integer> map; Queue<Map.Entry<String, Integer>> queue = new PriorityQueue<>(10, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return o1.getValue() - o2.getValue(); } }); // Traverse every existing small file for (int i = 0; i <= divNum; i++) { System.out.println("The first" + i + "individual"); inputFile = new File("D:\\div\\d" + i + "file.txt"); if (!inputFile.exists()) continue; // Read the whole file at a time. This is for the convenience of reading by line if there is insufficient memory str = readToString(inputFile); strArray = str.split(System.lineSeparator()); map = new HashMap<>(); // Use hash table count for (String string : strArray) { try { map.put(string, map.get(string) + 1); } catch (Exception e) { map.put(string, 1); } } // Maintenance of small top reactor for (Map.Entry<String, Integer> entry : map.entrySet()) { if (queue.size() < 10) { queue.add(entry); continue; } if (entry.getValue() > queue.peek().getValue()) { queue.poll(); queue.add(entry); } } } // Output small top reactor Iterator<Map.Entry<String, Integer>> iterator = queue.iterator(); while (iterator.hasNext()) { Map.Entry<String, Integer> entry = iterator.next(); System.out.println(entry.getKey() + " " + entry.getValue()); } } // Read all files at once public static String readToString(File file) { Long filelength = file.length(); //Get file length byte[] filecontent = new byte[filelength.intValue()]; try { FileInputStream in = new FileInputStream(file); in.read(filecontent); in.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return new String(filecontent);//Return to file content, default encoding } }

