This blog will realize Worry free agent and National Agency To access and save to Redis database.
The anti crawling measures of worry free agent mainly lie in the inconsistency between the port of the page and the port number of the source code. The reason for the inconsistency is that there is js encryption. The solution is to directly check the corresponding js source code and see the principle of encryption.
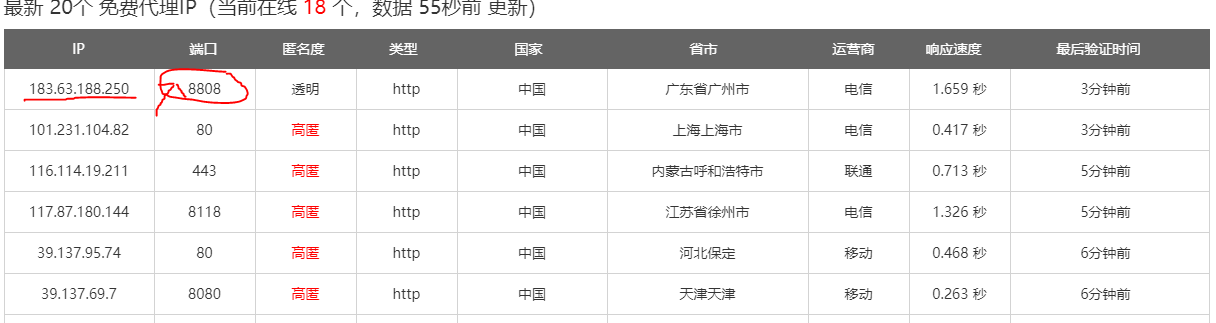
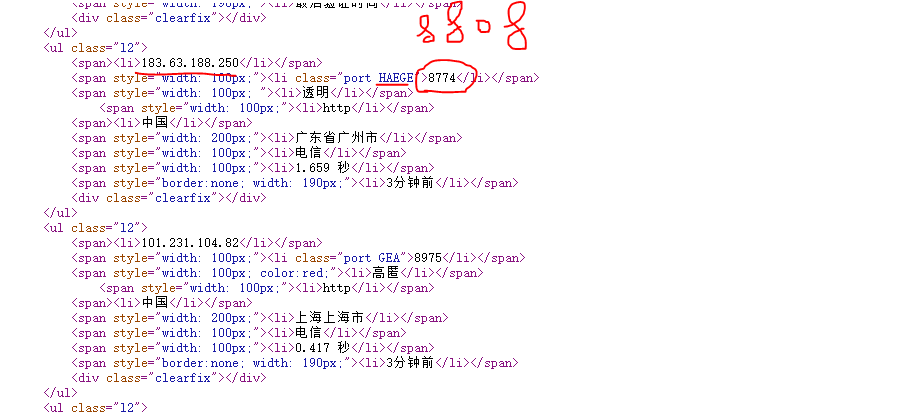
Through F12 check, we know that the encrypted js is http://www.data5u.com/theme/data5u/javascript/pde.js?v=1.0 Through Online tools You can expand the source code. Here, you need to expand it twice in a row. The effect is as follows:
$(function() {
$('.port')['each'](function() {
var a = $(this)['html']();
if (a['indexOf']('*') != -0x1) {
return
};
var b = $(this)['attr']('class');
try {
b = (b['split'](' '))[0x1];
var c = b['split']('');
var d = c['length'];
var f = [];
for (var g = 0x0; g < d; g++) {
f['push']('ABCDEFGHIZ' ['indexOf'](c[g]))
};
$(this)['html'](window['parseInt'](f['join']('')) >> 0x3)
} catch(e) {}
})
})It can be seen that the decryption logic is very clear, that is, take out the second class on the port element (assumed to start from 1), that is, the strange string, and then find its location in 'ABCDEFGHIZ'. Finally, splice the location coordinates found in order and turn them into numbers, and then divide them by 8 to get the final port number.
spider code
from scrapy import Spider
from scrapy import Request
from ..items import ProxypoolItem
class Data5uSpider(Spider):
name = 'data5u'
start_urls = ['http://www.data5u.com/']
def parse(self,response):
ip_list = response.xpath("//ul[@class='l2']/span[1]/li/text()").extract()
port = response.xpath("//ul[@class='l2']/span[2]/li/@class").extract()
port_list = []
for i in port:
stemp = i.replace('port', '').strip()
ports = []
for j in stemp:
ports.append(str("ABCDEFGHIZ".find(j)))
port_list.append(str(int(''.join(ports))//8))
http = response.xpath("//ul[@class='l2']/span[4]/li/text()").extract()
for q,w,e in zip(ip_list,port_list,http):
item = ProxypoolItem()
url = "{}://{}:{}".format(e, q, w)
item['url'] = url
print("Being tested%s"%url)
yield Request('https://www.baidu.com/', callback=self.test_parse,errback=self.error_parse,meta={"proxy": url, "dont_retyr": True, 'download_timeout': 10, 'item': item},dont_filter=True)
def test_parse(self, response):
yield response.meta['item']
def error_parse(self,response):
passLike worry free agent, the national agent has js encryption for port number. The difference is that its ip number also has some anti crawling and css confusion. By adding some "display: none" attribute tags to the source code, those who have learned a little about the front end know that this tag will not be displayed. So in order to crawl ip information, we must first remove such confusion tags in the source code.
Spider code
from scrapy import Spider
from scrapy import Request
from ..items import ProxypoolItem
import re
from lxml import etree
class GoubanSpider(Spider):
name = 'gouban'
start_urls = ['http://www.goubanjia.com/']
def parse(self, response):
# Removing tags with display:none; with regular
html = re.sub(r"<p style='display:none;'>.*?</p>", "", response.text)
html = re.sub(r"<p style='display: none;'>.*?</p>", "", html)
html = re.sub(r"<span style='display:none;'>.*?</span>", "", html)
html = re.sub(r"<span style='display: none;'>.*?</span>", "", html)
html = re.sub(r"<div style='display:none;'>.*?</div>", "", html)
html = re.sub(r"<div style='display: none;'>.*?</div>", "", html)
data = etree.HTML(html)
ip_info = data.xpath('//td[@class="ip"]')
for i in ip_info:
# Take out all the text in the td tag, connect it to a string through the join function, and replace the fake port with the regular one
ip_addr = re.sub(r":\d+", "", "".join(i.xpath('.//text()')))
# Extract the uppercase letters in the class attribute of the span tag to be processed
port = "".join(i.xpath('./span[last()]/@class')).replace(r"port", "").strip()
# Define an empty list to save where to find the letters
num = []
# Traverse the extracted letters, and find the position of each traversed letter in the string "ABCDEFGHIZ"
for j in port:
num.append(str("ABCDEFGHIZ".find(j)))
# First connect num to string, then convert it to integer, and finally get the real port at 8
ip_port = str(int(int("".join(num)) / 8))
# Splicing the processed ip address and port together to get the complete ip address and port
url = 'http://'+ip_addr + ':' + ip_port
item = ProxypoolItem()
item['url'] = url
# print("testing% s"%url)
yield Request('https://www.baidu.com/', callback=self.test_parse,errback=self.error_parse,meta={"proxy": url, "dont_retyr": True, 'download_timeout': 10, 'item': item},dont_filter=True)
def test_parse(self, response):
print("This is useful ip%s"%response.meta['item'])
yield response.meta['item']
def error_parse(self,response):
passPipelines code
This is stored in the redis database. My database does not have a password set, so no password is required for remote connection. If the password is set, add the password.
import redis
class ProxypoolPipeline(object):
def open_spider(self, spider):
# self.db_conn = redis.StrictRedis(host=spider.settings.get['IP'],port=spider.settings.get['PORT'],decode_responses=True)
self.db_conn = redis.StrictRedis(host='xxx', port=6379,decode_responses=True)
a = spider.settings.get['ROBOTSTXT_OBEY']
if spider.name == 'gouban':
self.db_conn.delete('ip')
def process_item(self, item, spider):
item_dict = dict(item)
self.db_conn.sadd("ip", item_dict['url'])
return item

