Crawl all the pictures and create a folder for the pictures of a page. Difficulties, there are many. gif pictures in the picture, which need to rewrite the download rules.
Create scrapy projects
scrapy startproject qiumeimei
Creating crawler applications
cd qiumeimei
scrapy genspider -t crawl qmm www.xxx.com
Define download fields in items.py file
import scrapy class QiumeimeiItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() page = scrapy.Field() image_url = scrapy.Field()
Write crawler main program in qmm.py file
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from qiumeimei.items import QiumeimeiItem class QmmSpider(CrawlSpider): name = 'qmm' # allowed_domains = ['www.xxx.com'] start_urls = ['http://www.qiumeimei.com/image'] rules = ( Rule(LinkExtractor(allow=r'http://www.qiumeimei.com/image/page/\d+'), callback='parse_item', follow=True), ) def parse_item(self, response): page = response.url.split('/')[-1] if not page.isdigit(): page = '1' image_urls = response.xpath('//div[@class="main"]/p/img/@data-lazy-src').extract() for image_url in image_urls: item = QiumeimeiItem() item['image_url'] = image_url item['page'] = page yield item
Define download rules in pipelines.py file
import scrapy import os from scrapy.utils.misc import md5sum # Import scrapy Pipeline file in frame for image processing from scrapy.pipelines.images import ImagesPipeline # Import Image Path Name from qiumeimei.settings import IMAGES_STORE as images_store # Must inherit ImagesPipeline class QiumeimeiPipeline(ImagesPipeline): # Define the return file name def file_path(self, request, response=None, info=None): file_name = request.url.split('/')[-1] return file_name # Method of overwriting downloaded files of parent classes def get_media_requests(self, item, info): yield scrapy.Request(url=item['image_url']) # Method name for completing image storage def item_completed(self, results, item, info): # print(results) page = item['page'] print('Downloading section'+page+'Page picture') image_url = item['image_url'] image_name = image_url.split('/')[-1] old_name_list = [x['path'] for t, x in results if t] # The Storage Path of Real Original Pictures old_name = images_store + old_name_list[0] image_path = images_store + page + "/" # Judging whether the catalog for image storage exists if not os.path.exists(image_path): # Create the corresponding directory based on the current page number os.mkdir(image_path) # New name new_name = image_path + image_name # rename os.rename(old_name, new_name) return item # Rewrite download rules def image_downloaded(self, response, request, info): checksum = None for path, image, buf in self.get_images(response, request, info): if checksum is None: buf.seek(0) checksum = md5sum(buf) width, height = image.size if self.check_gif(image): self.persist_gif(path, response.body, info) else: self.store.persist_file( path, buf, info, meta={'width': width, 'height': height}, headers={'Content-Type': 'image/jpeg'}) return checksum def check_gif(self, image): if image.format is None: return True def persist_gif(self, key, data, info): root, ext = os.path.splitext(key) absolute_path = self.store._get_filesystem_path(key) self.store._mkdir(os.path.dirname(absolute_path), info) f = open(absolute_path, 'wb') # use 'b' to write binary data. f.write(data)
Define the request header and open the download pipeline in the settings.py file
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36' ITEM_PIPELINES = { 'qiumeimei.pipelines.QiumeimeiPipeline': 300, }
Run crawler
scrapy crawl qmm --nolog
Check whether the folder was successfully downloaded
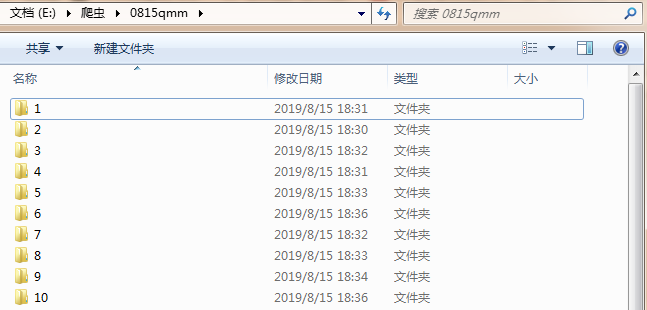
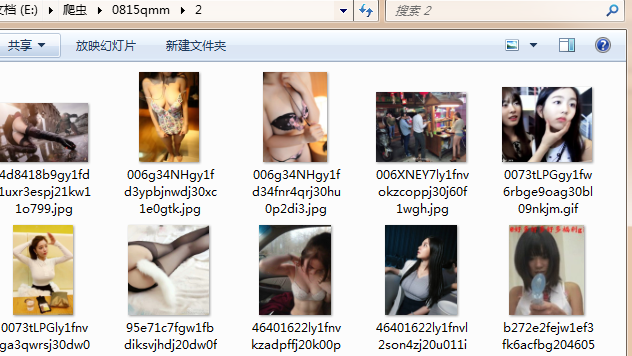

gif is a dynamic graph.
done.
