The main ideas of CFS are as follows:
- A weight is set based on the priority nice value of the normal process, which is used to calculate the conversion of the actual run time of the process to the virtual run time (vruntime). It goes without saying that processes with higher priority run more time and processes with lower priority run less time are equivalent to vruntime.
- Calculate a total period cycle based on the number of processes in rq->cfs_rq, each process calculates its ideal_runtime based on its own weight as a percentage of the total, and in scheduler_tick(), determine if the actual running time of the process (exec_runtime) has reached its ideal_runtime, then the process needs to be scheduled to test_tsk_need_resched(curr).With period, all processes in cfs_rq must be scheduled within the period
- At the same time, set a schedule cycle (sched_latency_ns) with the goal of giving each process at least one chance to run in that cycle, in other words, each process can wait for CPU for no more than this schedule cycle
- Another scenario in which the sched_min_granularity_ns parameter works is when the CFS divides the scheduling cycle sched_latency equally by the number of processes, and evenly allocates CPU time slices to each process (weight ed by the nice value, of course), but if there are too many processes, the CPU time slices will be too small, if less than sched_min_granularity_ns, SCHed_min_granularity_ns prevails, and the scheduling cycle is no longer sched_latency_ns compliant, but is based on the product of (sched_min_granularity_ns * number of processes).
- Another scenario where the parameter sched_min_granularity_ns works is that the parameter defines a condition that must be met before the wake-up process can preempt the current process: it can only preempt if the vruntime of the wake-up process is smaller than the vruntime of the current process and the difference (vdiff) between the two is greater than sched_wakeup_granularity_ns, otherwise it cannot.The larger this parameter is, the harder wake-up preemption will occur.
- Organize the processes in rq->cfs_rq into a red-black tree (balanced binary tree) based on the virtual run time (vruntime) of the process. The leftmost node of the tree in pick_next_entity is the process with the least run time and is the best candidate for scheduling.
- Today September 1st, I need to add fuel.Ha-ha.
Since task organizes red and black trees by vruntime time, the scheduling algorithm also schedules task by the leftmost leaf node (the smallest vruntime).Let's see how vruntime calculates first.
How does ##vruntime calculate
vruntime = runtime * (NICE_0_LOAD/nice_n_weight) for each process
We can see that the weight corresponding to the priority is set as follows:
Nice(0)=NICE_0_LOAD=1024, nice(1)=nice(0)/1.25,nice(-1)=nice(0)*1.25, as shown in the following table:
/* The main idea of this table is that weight s one level higher are 1.25 times lower */
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
NICE_0_LOAD(1024) is a magical number in the schedule calculation, meaning benchmark "1".Since kernel s cannot represent decimals, enlarging 1 is called 1024.
The TICK_NSEC cycle updates vruntime as follows:
Scheduler_tick---->task_tick_fair-->enqueue_tick--->update_curr, as follows:
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
sched_clock_tick();
raw_spin_lock(&rq->lock);
/*Set window_start time for rq*/
walt_set_window_start(rq);
/*Update runnable time, pre runnable time and demand time of current task*/
walt_update_task_ravg(rq->curr, rq, TASK_UPDATE,
walt_ktime_clock(), 0);
update_rq_clock(rq); /*Update rq run time*/
#ifdef CONFIG_INTEL_DWS
if (sched_feat(INTEL_DWS))
update_rq_runnable_task_avg(rq);
#endif
/*task Update of vruntime virtual run time per cycle*/
curr->sched_class->task_tick(rq, curr, 0);
/*load Used as load balancing, load decay and computation will be discussed separately later*/
update_cpu_load_active(rq); /*Update cpu load*/
calc_global_load_tick(rq); /*Update system load*/
raw_spin_unlock(&rq->lock);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
if (curr->sched_class == &fair_sched_class)
check_for_migration(rq, curr);
}
/*
* scheduler tick hitting a task of our scheduling class:
*/
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
struct sched_domain *sd;
/*This is the vruntime for calculating se (dispatch entity)*/
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
if (static_branch_unlikely(&sched_numa_balancing))
task_tick_numa(rq, curr);
#ifdef CONFIG_64BIT_ONLY_CPU
trace_sched_load_per_bitwidth(rq->cpu, weighted_cpuload(rq->cpu),
weighted_cpuload_32bit(rq->cpu));
#endif
#ifdef CONFIG_SMP
rq->misfit_task = !task_fits_max(curr, rq->cpu);
rcu_read_lock();
sd = rcu_dereference(rq->sd);
/*More cpu overload, whether there is Misfit task in rq to determine whether sched domain s are overloaded, and how
Judging overload has been described in a special article*/
if (sd) {
if (cpu_overutilized(task_cpu(curr)))
set_sd_overutilized(sd);
if (rq->misfit_task && sd->parent)
set_sd_overutilized(sd->parent);
}
rcu_read_unlock();
#endif
}
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq); /*Update Runtime and Virtual Runtime*/
/*
* Ensure that runnable average is periodically updated.
*/
update_load_avg(curr, UPDATE_TG); /*Update entity's load,PELT algorithm*/
update_cfs_shares(curr);
……………………………….
/*Whether check needs to be scheduled when the task in the runnable within rq is longer than one time.*/
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}
/*Compute vruntime*/
/*
* Update the current task's runtime statistics.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
/*curr Runtime*/
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
/*Remark run start time to facilitate next tick and calculate run time*/
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
/*Accumulated run time*/
curr->sum_exec_runtime += delta_exec;
/*Update proc/schedstat data*/
schedstat_add(cfs_rq, exec_clock, delta_exec);
/*Update vruntime for each task per tick cycle*/
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
/*
* delta /= w
*/
/*Calculate virtual run time*/
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
So how does the system calculate vruntime based on the weights when updating the virtual run time of a process based on its actual run time only? We know:
static void set_load_weight(struct task_struct *p)
{ /*Get priority for task*/
int prio = p->static_prio - MAX_RT_PRIO;
struct load_weight *load = &p->se.load;
/*
* SCHED_IDLE tasks get minimal weight:
*//*Set priority weight for idle thread*/
if (idle_policy(p->policy)) {
load->weight = scale_load(WEIGHT_IDLEPRIO);
load->inv_weight = WMULT_IDLEPRIO;
return;
}
/*Weight to set normal process priority,*/
load->weight = scale_load(prio_to_weight[prio]);
/*The inverse of the process weight, which is 2^32/weight*/
load->inv_weight = prio_to_wmult[prio];
/*Both values can be obtained by looking up a table*/
}
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
/*
* Inverse (2^32/x) values of the prio_to_weight[] array, precalculated.
*
* In cases where the weight does not change often, we can use the
* precalculated inverse to speed up arithmetics by turning divisions
* into multiplications:
*/ /*The reciprocal of the process weight, which is 2^32/weight: 2^32=4294967296, 2^32/NICE_0_LOAD=2^32/1024=4194304, is expected*/
static const u32 prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};
/*Calculate virtual run time*/
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
/*
* delta_exec * weight / lw.weight
* OR
* (delta_exec * (weight * lw->inv_weight)) >> WMULT_SHIFT
*
* Either weight := NICE_0_LOAD and lw \e prio_to_wmult[], in which case
* we're guaranteed shift stays positive because inv_weight is guaranteed to
* fit 32 bits, and NICE_0_LOAD gives another 10 bits; therefore shift >= 22.
*
* Or, weight =< lw.weight (because lw.weight is the runqueue weight), thus
* weight/lw.weight <= 1, and therefore our shift will also be positive.
*/
static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw)
{
u64 fact = scale_load_down(weight);
int shift = WMULT_SHIFT;
__update_inv_weight(lw);
if (unlikely(fact >> 32)) {
while (fact >> 32) {
fact >>= 1;
shift--;
}
}
/* hint to use a 32x32->64 mul */
fact = (u64)(u32)fact * lw->inv_weight;
while (fact >> 32) {
fact >>= 1;
shift--;
}
return mul_u64_u32_shr(delta_exec, fact, shift);
}
| You know that the core calculation function is u calc_delta and how it is calculated. vruntime = runtime * (NICE_0_LOAD/nice_n_weight) = (runtime*NICE_0_LOAD*inv_weight) >> shift =(runtime * NICE_0_LOAD * 2^32 / nice_n_weight) > 32 is the essence of the u calc_delta function. Because 2^32/nice_n_weight precomputed and generated the calculated table, prio_to_wmult[] |
Now that you know the value of vruntime, how does scheduler decide whether to schedule a task?
##Ideal run time/sched period
The purpose of periods is to calculate the time that each task can run over a period of time, that is, the time slice allocated.The time slices allocated in cfs_rq are calculated from the weight of the task.
During the code analysis above, we saw that if nr_running >1 for cfs_rq, it detects whether a task needs to be scheduled: scheduler_tick->task_tick_fair->entity_tick->check_preempt_tick:
/*
* Preempt the current task with a newly woken task if needed:
*/
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
/*Compute period and ideal_runntime*/
ideal_runtime = sched_slice(cfs_rq, curr);
/*Calculate actual run time*/
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
/* If the actual run time has exceeded ideal_time,
Current process needs to be scheduled, set TIF_NEED_RESCHED flag
*/
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* Ensure that a task that missed wakeup preemption by a
* narrow margin doesn't have to wait for a full slice.
* This also mitigates buddy induced latencies under load.
*/ /*Running time less than minimum granularity guaranteed, return directly, this task continues to run*/
if (delta_exec < sysctl_sched_min_granularity)
return;
/*Select the leftmost node of the red-black tree to run*/
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
/*Determine the size of the virtual run time of the current task and pick task*/
if (delta < 0)
return;
/*I don't know why delta is comparing???,*/
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
How does sched_slice calculate ideal_runtime?
/*
* We calculate the wall-time slice from the period by taking a part
* proportional to the weight.
*
* s = p*P[w/rw]
*/
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
u64 slice = __sched_period(cfs_rq->nr_running + !se->on_rq);
for_each_sched_entity(se) {
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load;
if (unlikely(!se->on_rq)) {
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
slice = __calc_delta(slice, se->load.weight, load);
}
return slice;
}
/*
* The idea is to set a period in which each task runs once.
*
* When there are too many tasks (sched_nr_latency) we have to stretch
* this period because otherwise the slices get too small.
*
* p = (nr <= nl) ? l : l*nr/nl
*/ /*If the number of nr_runnings in the cfs_rq queue is greater than eight, the sched_period time becomes nr_running
*0.75ms,Otherwise, 6ms, the number of nr_running s is rarely more than eight, but I have not seen them before*/
static u64 __sched_period(unsigned long nr_running)
{
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
return sysctl_sched_latency;
}
/*
* Targeted preemption latency for CPU-bound tasks:
* (default: 6ms * (1 + ilog(ncpus)), units: nanoseconds)
*
* NOTE: this latency value is not the same as the concept of
* 'timeslice length' - timeslices in CFS are of variable length
* and have no persistent notion like in traditional, time-slice
* based scheduling concepts.
*
* (to see the precise effective timeslice length of your workload,
* run vmstat and monitor the context-switches (cs) field)
*/
unsigned int sysctl_sched_latency = 6000000ULL;
/*
* Minimal preemption granularity for CPU-bound tasks:
* (default: 0.75 msec * (1 + ilog(ncpus)), units: nanoseconds)
*/
unsigned int sysctl_sched_min_granularity = 750000ULL;
/*
* is kept at sysctl_sched_latency / sysctl_sched_min_granularity
*/
static unsigned int sched_nr_latency = 8;
How does ##process insert into a red-black tree
The red-black tree is composed of the vruntime of the process, which calls the path:
enqueue_task---->enqueue_task_fair—>enqueue_entity---->__enqueue_entity:
/*In the core.c file*/
static inline void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{
update_rq_clock(rq);
if (!(flags & ENQUEUE_RESTORE))
sched_info_queued(rq, p);
#ifdef CONFIG_INTEL_DWS
if (sched_feat(INTEL_DWS))
update_rq_runnable_task_avg(rq);
#endif
p->sched_class->enqueue_task(rq, p, flags);
}
/*
* Enqueue an entity into the rb-tree:
*/
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/*Root node of a red-black tree*/
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
int leftmost = 1;
/*
* Find the right place in the rbtree:
*/
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_entity, run_node);
/*
* We dont care about collisions. Nodes with
* the same key stay together.
*/
/*Comparing the vruntime of se, the smaller one will be placed in the rb_left of the rb tree*/
if (entity_before(se, entry)) {
link = &parent->rb_left;
} else {
link = &parent->rb_right;
leftmost = 0;
}
}
/*
* Maintain a cache of leftmost tree entries (it is frequently
* used):
*/
if (leftmost)
cfs_rq->rb_leftmost = &se->run_node;
rb_link_node(&se->run_node, parent, link);
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
}
Decide which task to insert into the rb tree based on when enqueue task is scheduled:
- Newly created process
- idle process wakeup
- Balance of task (migration)
- Changing cpu affinity of task
- Change the priority of task
- Set task from a task group to a new task group, if you change the rq of task
Changing the behavior of a task generally triggers the recalculation of the value of the task's vruntime, which in turn causes the rq rb tree to be re-inserted on the corresponding cpu
Relationship between ##sched_entity and task group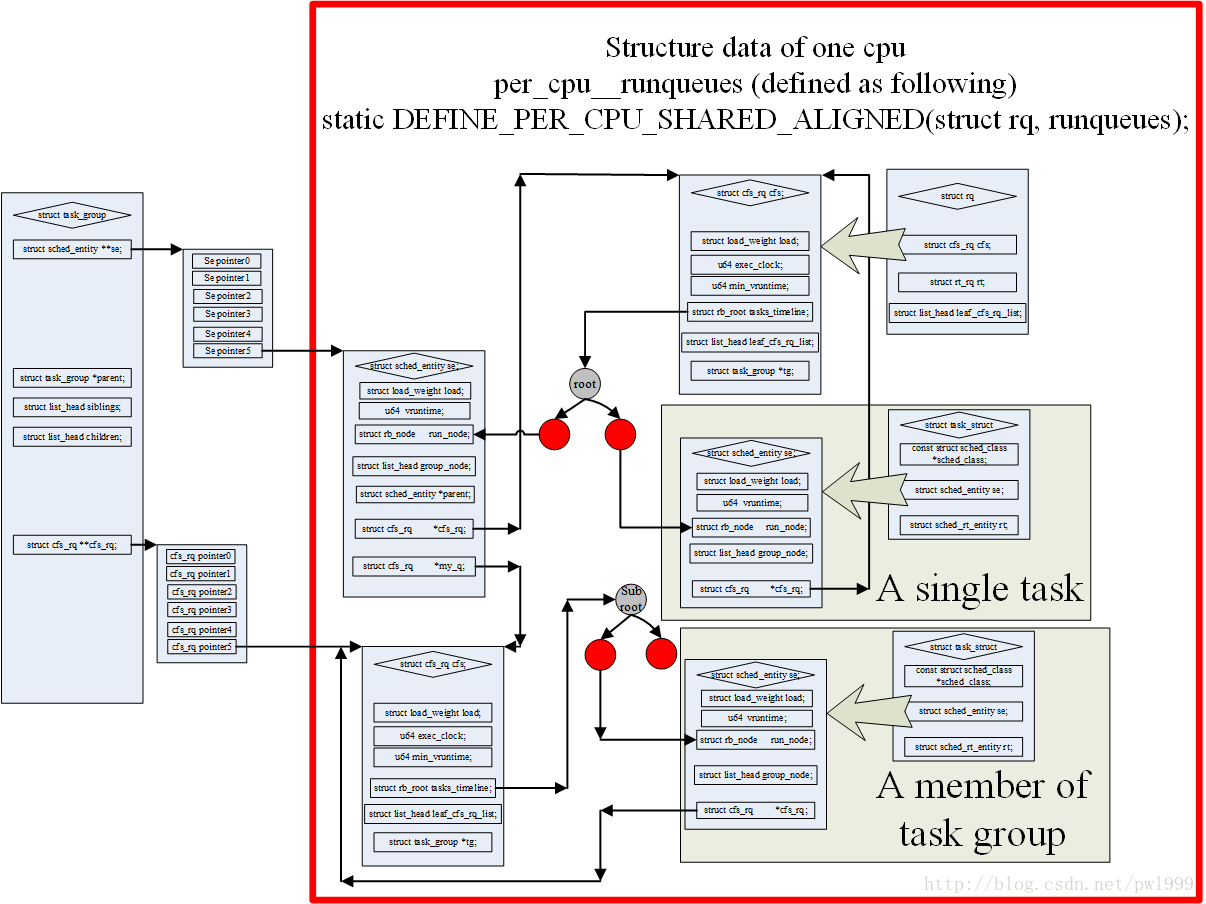
Because the new kernel incorporates the concept of task_group, instead of directly participating in a schedule calculation using the task_struct structure, it now uses the sched_entity structure.A sched_entity structure may be a task or a task_group->se[cpu].The relationship between these structures is well described in the figure above.
The main hierarchical relationships are as follows:
- One cpu corresponds to only one rq;
- One RQ has a cfs_rq;
- cfs_rq uses red-black trees to organize multiple sched_entity of the same hierarchy;
- If sched_entity corresponds to a task_struct, then sched_entity and task are one-to-one relationships;
- If the sched_entity corresponds to a task_group, then it is one of several sched_entities for a task_group.Task_group has an array se[cpu], with a sched_entity on each cpu.This type of sched_entity has its own cfs_rq, one sched_entity corresponds to one cfs_rq (se->my_q), and cfs_rq then continues to use red-black trees to organize multiple sched_entities at the same level; hierarchical relationships between 3 and 5 can continue to be recursive.
Changes in vruntime at ##Special moments
Regular scheduler_tick updates the vruntime according to tickless ness, which changes the vruntime value both in the state of the process and in the timing of the schedule.
- What is the newly created process vruntime?
If the initial vruntime value of the new process is 0, which is much smaller than that of the old process, it will maintain the advantage of seizing CPU for a considerable period of time and the old process will starve to death, which is obviously unfair.
CFS assigns a new creation process the maximum value between the parent process vruntime (curr->vruntime) and (cfs_rq->min_vruntime+, assuming that se has run through one round).Minimize the scheduling impact of new processes on existing processes.
_do_fork() -> copy_process() -> sched_fork() -> task_fork_fair()-
>place_entity:
/*
* called on fork with the child task as argument from the parent's context
* - child not yet on the tasklist
* - preemption disabled
*/
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
struct rq *rq = this_rq();
raw_spin_lock(&rq->lock);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current);
curr = cfs_rq->curr;
/*If curr exists, the new task's vruntime is curr's vruntime, which inherits from father's vruntime*/
if (curr) {
update_curr(cfs_rq);
se->vruntime = curr->vruntime;
}
/*Update the vruntime of the new task dispatch entity se, described below*/
place_entity(cfs_rq, se, 1);
/* If the sysctl_sched_child_runs_first flag is set,
Ensure that the fork child process executes before the parent process*/
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {
/*
* Upon rescheduling, sched_class::put_prev_task() will place
* 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
}
/* To prevent new processes from running on other cpu s,
This adds the min_vruntime value of another cfs_rq queue when adding another cfs_rq
(Specifically, you can see the enqueue_entity function)
*/
se->vruntime -= cfs_rq->min_vruntime;
raw_spin_unlock(&rq->lock);
}
/*Recalculate the vruntime time of a process based on its state*/
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;
// printk("[samarxie] min_vruntime = %llu\n",vruntime);
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
// printk("[samarxie] vruntime = %llu,load_weight=%lu\n",vruntime,se->load.weight);
/* sleeps up to a single latency don't count.task flag For ENQUEUE_WAKEUP
Then initial=0 */
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/ /*The effect of sleep time is halved to produce a mild effect, equivalent to attenuation, on the sleeper.*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
}
/*In (curr->vruntime) and (cfs_rq->min_vruntime+, assuming se has run a round of values),
Maximum between */
/* ensure we never gain time by being placed backwards. */
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
/*The vruntime corresponding to cfs_rq is subtracted when task_fork_fair creates the process, but when queued,
It's really clever to add the corresponding values again to avoid problems caused by different min_vruntime processes on different cpu s.*/
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Update the normalized vruntime before updating min_vruntime
* through calling update_curr().
*/
/* Add cfs_rq->min_vruntime to se->vruntime when enqueue */
if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))
se->vruntime += cfs_rq->min_vruntime;
}
- Does the vruntime of the dormant process remain the same?
If the vruntime of the hibernating process remains unchanged and the vruntime of the other running processes keeps advancing, then when the hibernating process finally wakes up, its vruntime will be much smaller than others, giving it the advantage of taking CPU for a long time, and the other processes will starve to death.This is obviously another form of injustice.
The CFS does this by resetting the vruntime value when the dormant process wakes up, giving some compensation based on the min_vruntime value, but not much compensation.
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
if (flags & ENQUEUE_WAKEUP) {
/* (1) Compute vruntime after process wakes up */
place_entity(cfs_rq, se, 0);
enqueue_sleeper(cfs_rq, se);
}
}
|→
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
/* (1.1) Initial value is the current minimum min_vruntime of cfs_rq */
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
/* sleeps up to a single latency don't count. */
/* Compensation is based on the minimum min_vruntime.
The default compensation value is 3ms(sysctl_sched_latency/2) wakeup initial=0
*/
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
}
/* ensure we never gain time by being placed backwards. */
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
- Does the hibernating process immediately grab CPU when it wakes up?
By default, a process is waked up to check for library preemption immediately, because the waked vruntime compensates for the minimum min_vruntime of cfs_rq, so it is certain that it will preempt the current process.
CFS can prevent wake-up preemption by prohibiting WAKEUP_PREEMPTION, but this also loses the preemption feature.
wake_up_process(p)->try_to_wake_up() -> ttwu_queue() -> ttwu_do_activate() -> ttwu_do_wakeup() -> check_preempt_curr() -> check_preempt_wakeup()
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags)
{
const struct sched_class *class;
/*Preemption settings based on the current dispatch class*/
if (p->sched_class == rq->curr->sched_class) {
rq->curr->sched_class->check_preempt_curr(rq, p, flags);
} else { /*Otherwise traverse from the highest priority sched_class*/
for_each_class(class) {
if (class == rq->curr->sched_class)
break;
/*Set rescheduling if a process's dispatch class is found*/
if (class == p->sched_class) {
resched_curr(rq);
break;
}
}
}
/*
* A queue event has occurred, and we're going to schedule. In
* this case, we can save a useless back to back clock update.
*/
if (task_on_rq_queued(rq->curr) && test_tsk_need_resched(rq->curr))
rq_clock_skip_update(rq, true);
}
/*cfs Schedule class, defined preemption function*/
const struct sched_class fair_sched_class = {
.............
.check_preempt_curr = check_preempt_wakeup,
.............
}
/*
* Preempt the current task with a newly woken task if needed:
*/
/*It is mainly a judgment of some conditions to decide whether or not preemption is necessary.*/
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
struct task_struct *curr = rq->curr;
struct sched_entity *se = &curr->se, *pse = &p->se;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
/*nr_running Is it greater than 8*/
int scale = cfs_rq->nr_running >= sched_nr_latency;
int next_buddy_marked = 0;
if (unlikely(se == pse))
return;
/*
* This is possible from callers such as attach_tasks(), in which we
* unconditionally check_prempt_curr() after an enqueue (which may have
* lead to a throttle). This both saves work and prevents false
* next-buddy nomination below.
*/
if (unlikely(throttled_hierarchy(cfs_rq_of(pse))))
return;
if (sched_feat(NEXT_BUDDY) && scale && !(wake_flags & WF_FORK)) {
set_next_buddy(pse);
next_buddy_marked = 1;
}
/*
* We can come here with TIF_NEED_RESCHED already set from new task
* wake up path.
*
* Note: this also catches the edge-case of curr being in a throttled
* group (e.g. via set_curr_task), since update_curr() (in the
* enqueue of curr) will have resulted in resched being set. This
* prevents us from potentially nominating it as a false LAST_BUDDY
* below.
*/
if (test_tsk_need_resched(curr))
return;
/* Idle tasks are by definition preempted by non-idle tasks. */
if (unlikely(curr->policy == SCHED_IDLE) &&
likely(p->policy != SCHED_IDLE))
goto preempt;
/*
* Batch and idle tasks do not preempt non-idle tasks (their preemption
* is driven by the tick):
*/ /*Whether to set preemption flags*/
if (unlikely(p->policy != SCHED_NORMAL) || !sched_feat(WAKEUP_PREEMPTION))
return;
find_matching_se(&se, &pse);
update_curr(cfs_rq_of(se));
BUG_ON(!pse);
if (wakeup_preempt_entity(se, pse) == 1) {
/*
* Bias pick_next to pick the sched entity that is
* triggering this preemption.
*/
if (!next_buddy_marked)
set_next_buddy(pse);
goto preempt;
}
return;
preempt:
resched_curr(rq); /*Rescheduling*/
/*
* Only set the backward buddy when the current task is still
* on the rq. This can happen when a wakeup gets interleaved
* with schedule on the ->pre_schedule() or idle_balance()
* point, either of which can * drop the rq lock.
*
* Also, during early boot the idle thread is in the fair class,
* for obvious reasons its a bad idea to schedule back to it.
*/
if (unlikely(!se->on_rq || curr == rq->idle))
return;
if (sched_feat(LAST_BUDDY) && scale && entity_is_task(se))
set_last_buddy(se);
}
So generally the wake-up process runs immediately, even if you wakup sleep immediately, it will preempt to sleep first
- Will vruntime change when a process is migrated from one CPU to another?
The load of different CPUs is different, so vruntime levels of se in different cfs_rq are different.It is also very unfair for a process migration vruntime to remain unchanged.CFS uses a smart approach: subtract min_vruntime from old cfs_rq when exiting old cfs_rq, and add min_vruntime from new cfs_rq when adding new cfq_rq.
static void
dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
……………….
/*
* Normalize the entity after updating the min_vruntime because the
* update can refer to the ->curr item and we need to reflect this
* movement in our normalized position.
*/
/* Minus min_vruntime of old cfs_rq when exiting old cfs_rq */
if (!(flags & DEQUEUE_SLEEP))
se->vruntime -= cfs_rq->min_vruntime;
……………….
}
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
……………….
/*
* Update the normalized vruntime before updating min_vruntime
* through calling update_curr().
*/
/* Add min_vruntime of new cfs_rq when adding new cfq_rq */
if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))
se->vruntime += cfs_rq->min_vruntime;
……………….
}
This is a simple part of how the basic scheduling algorithm picks up a task and inserts rb tree and dispatch se based on vruntime values.
Today is September 1st. It's a memorable day for all of you. You can't go back.But the revolution has not yet succeeded, and comrades need to work hard.