Introduction to ###Scheduler
A good scheduling algorithm should consider the following aspects:
- Fairness: Reasonable CPU time is guaranteed for each process.
- Efficient: Keep the CPU busy, that is, there are always processes running on the CPU.
- Response time: Make the response time of the interactive user as short as possible.
- Turnover time: Make the batch user wait as short as possible for output.
- Throughput: Maximize the number of processes processed per unit time.
- Load Balancing: Provides better performance in multicore multiprocessor systems
The entire scheduling system contains at least two scheduling algorithms, one for real-time processes and the other for ordinary processes. So in the linux kernel, real-time processes and ordinary processes coexist, but they use different scheduling algorithms. Common processes use CFS scheduling algorithms (red-black tree scheduling).It then describes how the scheduler schedules both processes.
###Process
As explained above, there are two main types of processes in linux, one is real-time process and the other is normal process.
- Real-time process: The response time of the system is very high, they need a short response time, and the change of this time is very small. Typical real-time processes are music player, video player, etc.
- Normal processes: Including interactive and non-interactive processes, such as text editors, which sleep and wake up continuously with the mouse keyboard. Non-interactive processes, such as background maintenance processes, do not require high IO response times, such as compilers.
They coexist when the linux kernel is running. The priority of the real-time process is 099. The priority of the real-time process will not change during the running time (static priority). The priority of the ordinary process is 100139. The priority of the ordinary process will change accordingly during the running time of the kernel (dynamic priority).
###Scheduling Policy
In linux systems, scheduling strategies are divided into
- SCHED_NORMAL: The scheduling policy used by ordinary processes, which now uses the CFS scheduler.
- SCHED_FIFO: A scheduling policy used by a real-time process that runs once the CPU is used until a higher priority real-time process is queued or automatically discards the CPU, suitable for processes that require more time but have a shorter run time each time.
- SCHED_RR: A time slice rotation policy used by real-time processes. When the time slice of a real-time process is exhausted, the scheduler places it at the end of the queue so that each real-time process can execute for a period of time.Suitable for real-time processes that take longer to run each time.
###Scheduling
First, we need to be clear which processes will enter the scheduler to choose from, that is, processes in the TASK_RUNNING state, and processes in other states will not enter the scheduler for scheduling.Scheduling occurs at the following times:
- When cond_resched() is called
- When schedule() is explicitly called
- When returning to user space from a system call or an abnormal interrupt
- When user space is returned from interrupt context
When kernel preemption is turned on (by default), there are several more scheduling times, as follows:
- When preempt_enable() is called in the context of a system call or an abnormal interruption (when preempt_enable() is called multiple times, the system will only schedule on the last call)
- In the interrupt context, when the interrupt handler returns to the preemptive context (in this case, the lower half of the interrupt, the upper half of the interrupt actually shuts down the interrupt, while the new interrupt will only be registered, because the upper part is processed very quickly, the new interrupt signal will not be executed until the upper part is processed, thus creating an interrupt reentrant)
A schedule timer is initialized when the system starts dispatcher initialization. The schedule timer executes an interrupt at regular intervals, which updates the current running time of the process. If the process needs to be dispatched, a schedule flag bit is set in the schedule timer interrupt and returned from the timer interrupt, as mentioned above, from the interruptWhen returning below is scheduled, all interrupt return processing in the assembly code of the kernel source code must determine whether the scheduler bit is set or not, and if set, schedule() is executed for scheduling.However, we know that real-time processes and normal processes coexist. How does the scheduler coordinate the scheduling between them? In fact, it is very simple. Each time the scheduler schedules, it first checks whether there are real-time processes in the real-time process running queue. If not, it goes to the normal process running queue to find the next normal process that can run. If not, the scheduler uses I.The dle process runs.Later chapters are detailed with code.
Scheduling is not allowed to occur at all times in the system. When a hard interrupt occurs, scheduling is prohibited by the system, and then the hard interrupt is allowed again.For exceptions, the system does not prohibit scheduling, that is, in the context of exceptions, it is possible for the system to schedule.
###Data Structure
In this section, we all take ordinary processes as the object of explanation, because the scheduling algorithm used by ordinary processes is CFS scheduling algorithm, which is a red-black tree-based scheduling algorithm. Compared with real-time processes, the scheduling algorithm of real-time processes is much more complex, but the organization structure of real-time processes is not very different from that of ordinary processes, and the algorithm is simpler.
Form of Composition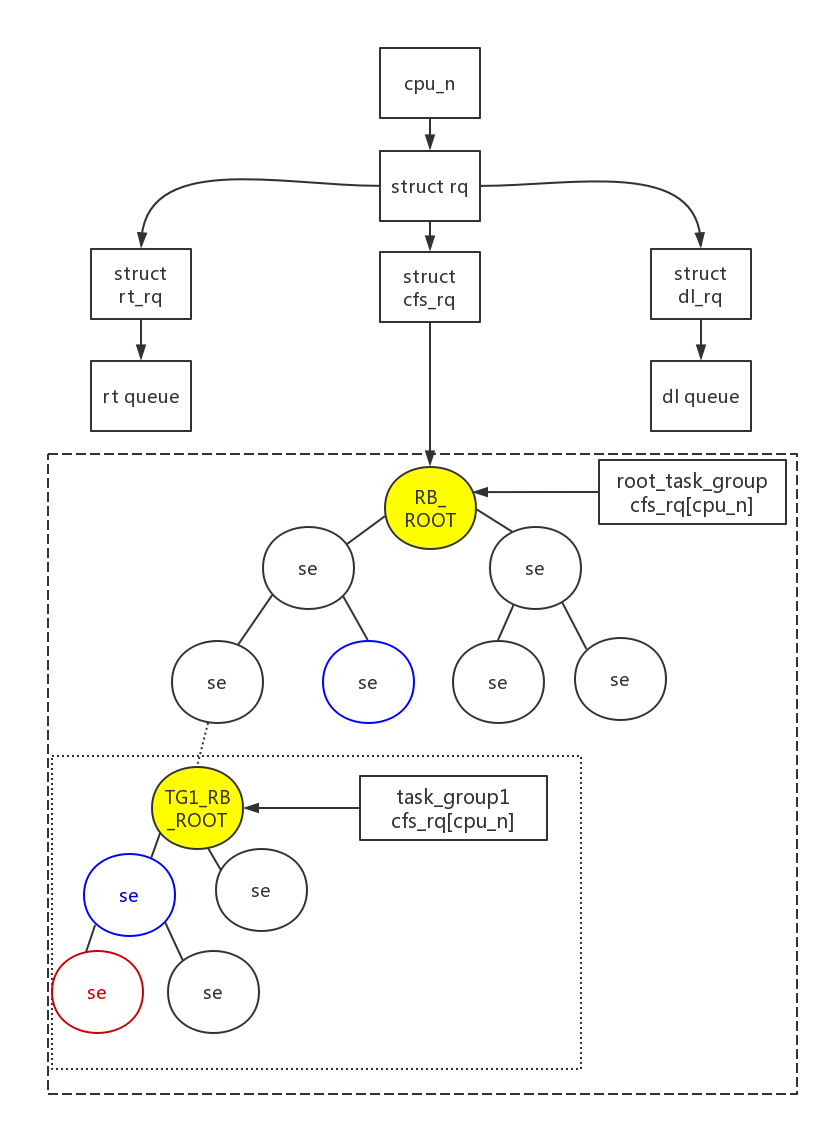
From this picture, learn about the relationship between task_group,sched_entity,cfs_rq, root_task_group.
- One rq per cpu
- Each RQ contains cfs_rq/rt_rq/dl_rq, cfs_rq is a normal process rq, rt_rq is a real-time process rq, dl_rq is not clear at present. In future research, the above diagram is analyzed with cfs_rq diagram
- se is a sched_entity that is a dispatch entity, may be a task, may be a task_group, or a process group, which contains multiple tasks, and each task within this task group can run on a different CPU mask
- If the dispatching entity is only a task, because the root node root_task_group organizes, that is, cfs rq on each cpu organizes the RB tree with root_task_group, the node is the dispatching entity (a single task/task group).A process group composed of a single task, with the dispatcher directly selecting the leftmost leaf node as the dispatching entity to run in the running queue based on the RB tree
- If the dispatch entity is a task group, the process group exists as a dispatch entity, it contains several tasks, and several tasks may not run on the same cpu, then this dispatch group is equivalent to a self-contained rb tree, which, like the basic root_task_group, forms an rb tree.For example, the TG1_RB_ROOT shown in the figure is actually mounted under other dispatching entities as the following nodes of this group.
- When the scheduler picks task, if it is a process group, it enters TG1_RB_ROOT and looks for the leftmost leaf node of the rb tree to schedule.
- Since processes in a process group may run simultaneously on different cpUs in multiple CPU scenarios, each process group must assign its dispatch entity (struct sched_entity/struct sched_rt_entity) and run queue (struct cfs_rq/struct_rq) to each cpu.This initialization process is explained later.
The following diagram illustrates more graphically the relationship between a dispatching entity and a process group, looking at the bridging effect of my_q:
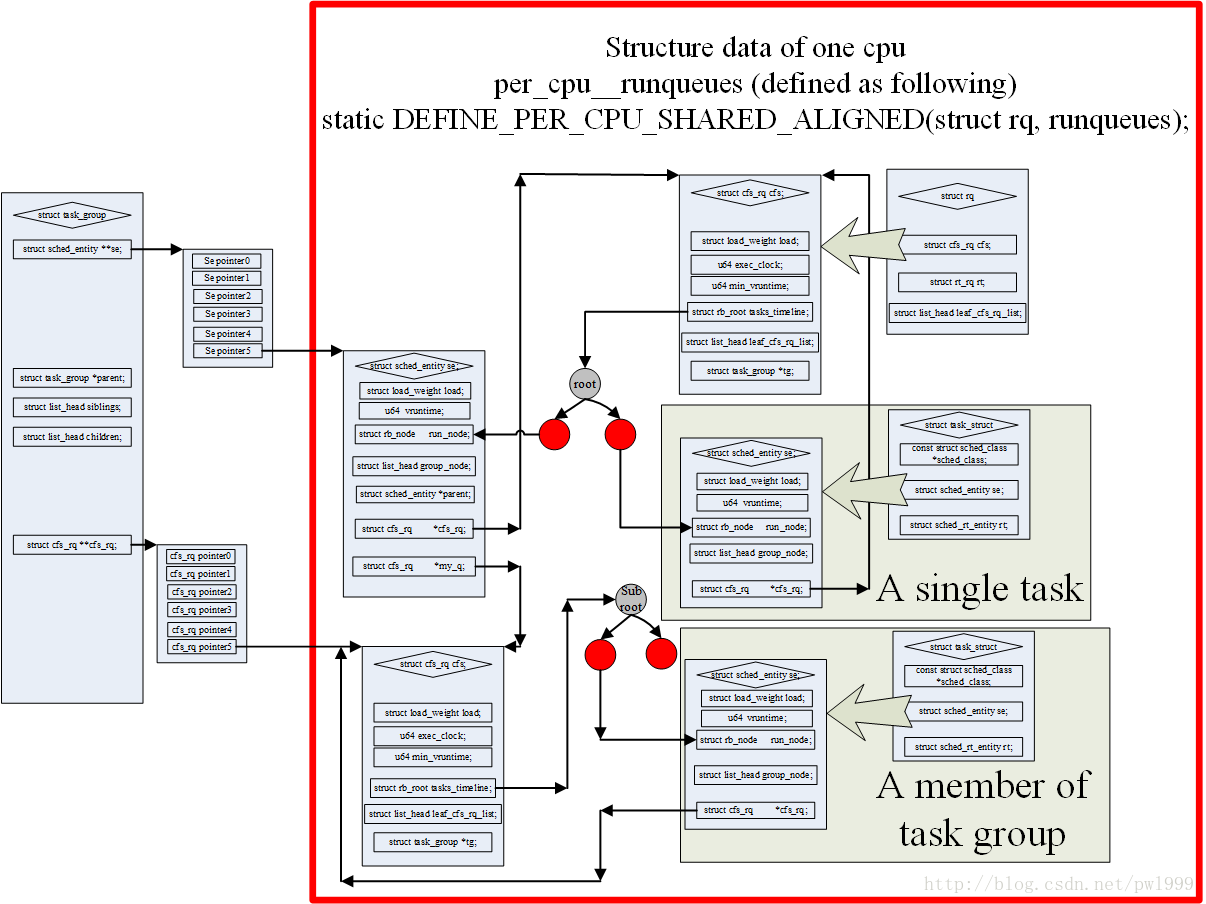
Group Scheduling (struct task_group)
We know that linux is a multiuser system. If two processes belong to two users and the priority of the processes is different, the CPU time used by the two users will be different. This is obviously unfair (if the priority gap is large, the CPU time used by the users belonging to the low priority processes will be small), so the kernel introduces group scheduling.If grouped based on users, both users will use 50% CPU time, even if the process priority is different.This is why CPU0 in Figure 1 has two programs that will be scheduled in blue. If the run time in task_group1 has not been used up yet, the next scheduled process in task_group1 will be scheduled when the current process run time is used up; otherwise, if the run time in task_group1 ends, the next scheduled process in the previous layer will be called.It is important to note that some of the group scheduling may be real-time processes and some ordinary processes, which also results in the group scheduling in real-time scheduling and CFS scheduling.
linux can group processes in two ways:
- User ID: Grouped by the USER ID of the process, a cpu.share file is generated in the corresponding/sys/kernel/uid/directory, which can be configured to configure the proportion of CPU time the user spends
- cgourp(control group): A build group is used to limit all its processes, such as I build a group (empty after the build), set its CPU usage to 10%, and drop a process into the group. This process can only use up to 10% of the CPU. If we drop multiple processes into this group, all processes in this group will be divided equally by 10%.
Note that the concept of process group here is different from that of parent-child process group produced by fork call. The concept of process group used in this article is the concept of process group in group scheduling.In order to manage group scheduling, the kernel introduced the struct task_group structure as follows:
/* task group related information */
struct task_group {
/* Used for processes to find the process group structure to which they belong */
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* CFS Scheduler's process group variable, process initialization and memory allocation in alloc_fair_sched_group() */
/* The process group has a corresponding dispatch entity on each CPU because it is possible that the process group is on both CPUs at the same time
Run (its process A runs on CPU0 and process B runs on CPU1) */
/* schedulable entities of this group on each cpu */
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
/* Process groups have a CFS run queue on each CPU (why, explained later) */
struct cfs_rq **cfs_rq;
/* Used to save the priority that defaults to NICE 0, which is a constant*/
unsigned long shares;
#ifdef CONFIG_SMP
atomic_long_t load_avg;
#endif
#endif
#ifdef CONFIG_RT_GROUP_SCHED
/* Process group variable for real-time process scheduler, same as CFS */
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
/* Used to create a process chain table (a process chain table belonging to this scheduling group) */
struct list_head list;
/* Process groups pointing to the upper layer, each of which is a dispatching entity of the running queue of the upper layer's process group
,At the same level, process groups and processes are treated equally */
struct task_group *parent;
/* Brother Node Chain List of Process Groups */
struct list_head siblings;
/* Son node list for process group */
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
};
In the struct task_group structure, the most important members are struct sched_entity ** se and struct cfs_rq ** cfs_rq.In Figure 1, both root_task_group and task_group1 have only one, and they initially allocate space based on the number of CPUs, Se and cfs_rq, that is, one Se and cfs_rq are assigned to each CPU in task_group1 and root_task_group, as are struct sched_rt_entity ** rt_se and struct_rq ** rt_rq for real-time processes.The reason for this is that in the case of multi-core and multi-CPUs, processes of the same process group may run on different CPUs at the same time, so each process group must assign its dispatch entity (struct sched_entity and struct sched_rt_entity) and run queue (struct cfs_rq and struct_rq) to each CPU.How to initialize it will be explained later.
###Scheduling Entities (struct sched_entity)
In group scheduling, the concept of dispatching entity is also involved. Its structure is struct sched_entity (se), which is the Se in the red and black tree of Figure 1.It actually represents a dispatch object, either a process or a process group.For the root red-black tree, a group of processes is equivalent to a dispatching entity, and a process is equivalent to a dispatching entity.We can look at its structure first, as follows:
/* A scheduling entity (a node of a red-black tree) that contains a set of processes or a specified process, including its own running queue, a father pointer, and a pointer to the running queue that needs to be scheduled */
struct sched_entity {
/* Weight, which contains the value of priority to weight in the array prio_to_weight[] */
struct load_weight load; /* for load-balancing */
/* Node information for entities in red and black trees */
struct rb_node run_node;
/* The process group in which the entity is located */
struct list_head group_node;
/* Is the entity in a red-black tree running queue */
unsigned int on_rq;
/* Start Runtime */
u64 exec_start;
/* Total run time */
u64 sum_exec_runtime;
/* Virtual run time, updated when time is interrupted or task status changes
* It will keep growing. The growth rate is inversely proportional to the load weight. The higher the load, the slower the growth rate.
The more likely it is to be dispatched on the far left side of a red-black tree
* Each clock interruption modifies its value
* See the calc_delta_fair() function specifically
*/
u64 vruntime;
/* The sum_exec_runtime value of the process when switching into the CPU */
u64 prev_sum_exec_runtime;
/* Number of processes moved to other CPU groups in this dispatch entity */
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
/* For statistical purposes */
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
/* Represents the depth of this process group, where each process group is 1 deeper than its parent dispatch group */
int depth;
/* The parent dispatches entity pointer, which points to the dispatching entity whose running queue is a process, or to a process group
Dispatching entity to its last process group
* Set in set_task_rq function
*/
struct sched_entity *parent;
/* The red-black tree running queue where the entity is located */
struct cfs_rq *cfs_rq;
/* Entity's Red-Black Tree runs queue if it's NULL indicating it's a process and if it's not NULL indicating it's a dispatch group */
struct cfs_rq *my_q;
#endif
#ifdef CONFIG_SMP
/* Per-entity load-tracking */
struct sched_avg avg;
#endif
};
In fact, the red-black tree is based on struct rb_node, but struct rb_node and struct sched_entity are one-to-one correspondence, or simply a red-black tree node is a dispatching entity.You can see that in the struct sched_entity structure, all the data for the scheduling of a process (or process group) is contained in the se of the struct task_struct structure, as follows:
struct task_struct {
........
/* Indicates whether the queue is running */
int on_rq;
/* Process Priority
* prio: Dynamic priority, ranging from 100 to 139, related to static priority and bonus
* static_prio: Static priority, static_prio = 100 + nice + 20
(nice The value is -20~19, so the static_prio value is 100~139)
* normal_prio: No general priority affected by priority inheritance, see normal_prio function
,What type of process does it belong to
*/
int prio, static_prio, normal_prio;
/* Real-time process priority */
unsigned int rt_priority;
/* Dispatch class, Dispatch Processing Function class */
const struct sched_class *sched_class;
/* Dispatch Entity (a red-black tree node) */
struct sched_entity se;
/* Dispatch Entities (real-time dispatch use) */
struct sched_rt_entity rt;
#ifdef CONFIG_CGROUP_SCHED
/* Point to the process group it belongs to */
struct task_group *sched_task_group;
#endif
........
}
In the struct sched_entity structure, the members that deserve our attention are:
- load: Weights, converted by priority, are the key to vruntime calculations.
- On_rq: To indicate whether or not you are in the CFS red-black tree running queue, it needs to be clear that there is a red-black tree in the CFS running queue, but this red-black tree is not all of the CFS running queue, because the red-black tree is just an algorithm for selecting the next scheduler.A simple example is that when a normal program is running, it is not in the red-black tree, but it is still in the CFS run queue and its on_rq is true.Only processes that are ready to exit, sleep waiting, and transition to a real-time process have on_rq fake on their CFS run queue.
- Vruntime: Virtual run time, the key to scheduling, its calculation formula: virtual run time of a schedule interval = actual run time* (NICE_0_LOAD/weight).It can be seen that the red-black tree is the criterion for sorting. The higher the priority process runs, the slower its vruntime grows, the longer its runtime is, and the more likely it is to be at the leftmost node of the red-black tree. The scheduler chooses the leftmost node each time as the next scheduling process.Note that the value is monotonically increasing, and the virtual run time of the current process is accumulated when each scheduler's clock is interrupted.Simply put, processes are all smallest vruntime than anyone else and the smallest will be scheduled.
- cfs_rq: The CFS run queue in which this dispatching entity resides.
- my_q: If this dispatch entity represents a process group, then this dispatch entity has its own CFS run queue, which is in the CFS run queue
The processes in this process group are stored and will not be included in the red and black trees of other CFS run queues (including the top red and black trees that do not contain them, they belong only to this process group).
It is a good idea to understand how a process group has its own CFS running queue. For example, there is a process A and a process group B on the red-black tree of the root CFS running queue, each accounting for 50% of the CPU. For the root red-black tree, they are two dispatching entities.Scheduler schedules either process A or process group B. If process group B is scheduled to process group B, process group B chooses a program for CPU to run. How process group B chooses a program for CPU is the red and black tree selection of its own CFS run queue. If process group B has a subprocess group C, the principle is the same, it is a hierarchy.
In the struct task_struct structure, we notice a dispatch class that contains a dispatch handler as follows:
struct sched_class {
/* Next priority scheduling class
* Scheduling class priority order: stop_sched_class -> dl_sched_class ->
rt_sched_class -> fair_sched_class -> idle_sched_class
*/
const struct sched_class *next;
/* Add a process to the running queue, place the dispatching entity (process) in the red-black tree, and run nr_running
Variable plus 1 */
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
/* Delete the process from the run queue and subtract 1 from the nr_running variable */
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
/* Abandons the CPU, and when compat_yield sysctl is turned off, the function actually executes first-out then-queue; in this case, it places the dispatch entity at the rightmost end of the red-black tree */
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
/* Check if the current process can be preempted by a new process */
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
/*
* It is the responsibility of the pick_next_task() method that will
* return the next task to call put_prev_task() on the @prev task or
* something equivalent.
*
* May return RETRY_TASK when it finds a higher prio class has runnable
* tasks.
*/
/* Select the next process to run */
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev);
/* Put the process back on the running queue */
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP
/* Choose an appropriate CPU for the process */
int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
/* Migrate tasks to another CPU */
void (*migrate_task_rq)(struct task_struct *p, int next_cpu);
/* Used after context switching */
void (*post_schedule) (struct rq *this_rq);
/* For process wakeup */
void (*task_waking) (struct task_struct *task);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
/* Modify the CPU affinity of the process */
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
/* Start Run Queue */
void (*rq_online)(struct rq *rq);
/* Prohibit running queues */
void (*rq_offline)(struct rq *rq);
#endif
/* Called when a process changes its dispatch class or process group */
void (*set_curr_task) (struct rq *rq);
/* This function is usually called from the time tick function; it may cause a process switch.
This will drive run-time preemption */
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
/* Called at process creation time, process initialization is different for different scheduling strategies */
void (*task_fork) (struct task_struct *p);
/* Used when the process exits */
void (*task_dead) (struct task_struct *p);
/* For process switching */
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
/* Change Priority */
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq);
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_move_group) (struct task_struct *p, int on_rq);
#endif
};
What's the use of this scheduling class? In fact, different scheduling algorithms in the kernel have different operations. In order to modify and replace the scheduling algorithms, a scheduling class is used. Each scheduling algorithm only needs to implement its own scheduling class. CFS algorithm has its own scheduling class, SCHED_FIFO has its own scheduling class. When a process is created, what is the scheduling class used?The degree algorithm points its task_struct->sched_class to its corresponding dispatch class, and each time the dispatcher dispatches, it operates through the current process's dispatch class function process, which greatly improves portability and modifiability.
###CFS Run Queue (struct cfs_rq)
We now know that there is at least one CFS run queue in the system, which is the root CFS run queue. Other process groups and processes are included in this run queue, except that the process group has its own CFS run queue, which contains all the processes in this process group.When the scheduler chooses a process group from the root CFS run queue for scheduling, the process group chooses a dispatching entity from its own CFS run queue to schedule (the dispatching entity may be a process or a sub-process group), and so on, until the last one is selected to run.
There is little to say about the struct cfs_rq structure, as long as you make sure it represents a CFS run queue and contains a red-black tree to select the scheduling process.
/* CFS Scheduled run queue, where each CPU's RQ contains a cfs_rq, and each group's sched_entity has its own cfs_rq queue */
/* CFS-related fields in a runqueue */
struct cfs_rq {
/* CFS Total load of all processes in the running queue*
struct load_weight load;
/*
* nr_running: cfs_rq Number of dispatched entities in
* h_nr_running: Valid only for process groups, the sum of nr_running for cfs_rq in all process groups below
*/
unsigned int nr_running, h_nr_running;
/*Get the active time of the current cfs_rq*/
u64 exec_clock;
/* Minimum run time on current CFS queue, monotonically increasing
* Update this value in two cases:
* 1、When updating the cumulative run time of the currently running task
* 2、When a task is deleted from the queue, such as when the task sleeps or exits, it checks to see if the remaining task's vruntime is greater than min_vruntime, and if so updates the value.
*/
u64 min_vruntime;
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
/* The root of the red-black tree */
struct rb_root tasks_timeline;
/* Next dispatch node (the leftmost node of the red-black tree, the leftmost node is the next dispatch entity) */
struct rb_node *rb_leftmost;
/*
* 'curr' points to currently running entity on this cfs_rq.
* It is set to NULL otherwise (i.e when none are currently running).
*/
/*
* curr: The currently running sched_entity (although it will not run on the cpu for a group, when it has a task running on the cpu below it, the cfs_rq it is in considers it to be the cfs_rq
Previously running sched_entity)
* next: Indicates that some processes are in urgent need of running and must run even if they do not comply with the CFS schedule. When dispatching, the check is
Whether Next needs scheduling, schedule next if available
*
* skip: Skip processes (skip-specified process scheduling will not be selected)
*/
struct sched_entity *curr, *next, *last, *skip;
#ifdef CONFIG_SCHED_DEBUG
unsigned int nr_spread_over;
#endif
#ifdef CONFIG_SMP
/*
* CFS load tracking The purpose is to determine which task enters the runnable/running state or whether balance is required
*/
struct sched_avg avg;
u64 runnable_load_sum;
unsigned long runnable_load_avg;
#ifdef CONFIG_64BIT_ONLY_CPU
unsigned long runnable_load_avg_32bit;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
unsigned long tg_load_avg_contrib;
unsigned long propagate_avg;
#endif
atomic_long_t removed_load_avg, removed_util_avg;
#ifndef CONFIG_64BIT
u64 load_last_update_time_copy;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
/*
* h_load = weight * f(tg)
*
* Where f(tg) is the recursive weight fraction assigned to
* this group.
*/
unsigned long h_load;
u64 last_h_load_update;
struct sched_entity *h_load_next;
#endif /* CONFIG_FAIR_GROUP_SCHED */
#endif /* CONFIG_SMP */
#ifdef CONFIG_FAIR_GROUP_SCHED
/* CPU rq to which it belongs */
struct rq *rq; /* cpu runqueue to which this cfs_rq is attached */
/*
* leaf cfs_rqs are those that hold tasks (lowest schedulable entity in
* a hierarchy). Non-leaf lrqs hold other higher schedulable entities
* (like users, containers etc.)
*
* leaf_cfs_rq_list ties together list of leaf cfs_rq's in a cpu. This
* list is used during load balance.
*/
int on_list;
struct list_head leaf_cfs_rq_list;
/*Process group belonging to this cfs_rq*/
struct task_group *tg; /* group that "owns" this runqueue */
#ifdef CONFIG_SCHED_WALT
/*walt Calculate the total runnable time for cfs_rq, this RQ*/
u64 cumulative_runnable_avg;
#endif
/*cfs_rq Bandwidth Limit Information*/
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock, throttled_clock_task;
u64 throttled_clock_task_time;
int throttled, throttle_count, throttle_uptodate;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};
Load: It holds the sum of the weights of all processes in the process group, and it is important to note that the load of the process group is used when a child process calculates the vruntime.
###CPU Run Queue (struct rq)
Each CPU has its own struct rq structure, which describes all processes running on this CPU. It includes a real-time process queue and a root CFS running queue. When dispatching, the dispatcher first goes to the real-time process queue to find if there are real-time processes running, and then goes to the CFS running queue to find if there are real-time processes running, which is why it is common toThe real-time process priority mentioned above is higher than that of the ordinary process, not only in prio priority, but also in the design of the scheduler. As for the dl running queue, I do not know what use it is for now. Its priority is higher than that of the real-time process, but if the dl process is created, it will be wrong.
/*
* This is the main, per-CPU runqueue data structure.
*
* Locking rule: those places that want to lock multiple runqueues
* (such as the load balancing or the thread migration code), lock
* acquire operations must be ordered by ascending &runqueue.
*/
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
/*How many running task s exist in this rq, including tasks for RT, fair, DL sched class es*/
unsigned int nr_running;
#ifdef CONFIG_NUMA_BALANCING
unsigned int nr_numa_running;
unsigned int nr_preferred_running;
#endif
#define CPU_LOAD_IDX_MAX 5
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
unsigned long last_load_update_tick;
/*When choosing the next dispatching entity, you need to decide if this task is a misfit task or if you are making a decision?
Not the same, such as forcing balance, etc.*/
unsigned int misfit_task;
#ifdef CONFIG_NO_HZ_COMMON
u64 nohz_stamp;
unsigned long nohz_flags;
#endif
#ifdef CONFIG_NO_HZ_FULL
unsigned long last_sched_tick;
#endif
#ifdef CONFIG_CPU_QUIET
/* time-based average load */
u64 nr_last_stamp;
u64 nr_running_integral;
seqcount_t ave_seqcnt;
#endif
/* capture load from *all* tasks on this cpu: */
/*The total load of all task s that can be run in rq is updated when the number of nr_running s changes*/
struct load_weight load;
/*How many task load s in rq need to be updated*/
unsigned long nr_load_updates;
/*The number of context switches that occur in a process. This statistic is only exported in the proc file system*/
u64 nr_switches;
/*The RQ on each cpu contains the cfs_rq,rt_rq, and dl_rq scheduling queues, including the root of the red-black tree*/
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* list of leaf cfs_rq on this cpu: */
struct list_head leaf_cfs_rq_list;
struct list_head *tmp_alone_branch;
#endif /* CONFIG_FAIR_GROUP_SCHED */
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*//* Number of processes that were once queued but are now in TASK_UNINTERRUPTIBLE state */
unsigned long nr_uninterruptible;
/*curr The pointer indicates the current running task pointer, idle indicates that there are no other processes in rq to run, and finally execute
idle task,This cpu enters idle state, stop denotes the current task sched_class stop scheduling class*/
struct task_struct *curr, *idle, *stop;
/*At the next balance, the system periodically performs a balance action.*/
unsigned long next_balance;
struct mm_struct *prev_mm;
unsigned int clock_skip_update;
/*rq Runtime, is an accumulative value*/
u64 clock;
u64 clock_task;
/*How many iowait s are in the current rq*/
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct root_domain *rd;
/* The basic dispatch domain in which the current CPU resides. Each dispatch domain contains one or more CPU groups, and each CPU group contains the dispatch
One or more subsets of CPU s in the domain, load balancing is done between groups in the dispatch domain and cannot be done across domains */
struct sched_domain *sd;
/*cpu_capacity:The actual capacity of this cpu will change as the system runs, initial value
For capacity_orig, cpu_capacity_orig: is the capacity of each CPU configured by dts, and is a constant*/
unsigned long cpu_capacity;
unsigned long cpu_capacity_orig;
struct callback_head *balance_callback;
unsigned char idle_balance;
/* For active balancing */
/* This bit needs to be set if the process needs to be migrated to another running queue */
int active_balance;
int push_cpu;
struct task_struct *push_task;
struct cpu_stop_work active_balance_work;
/* cpu of this runqueue: */
/* The CPU to which the running queue belongs */
int cpu;
int online;
struct list_head cfs_tasks;
#ifdef CONFIG_INTEL_DWS
struct intel_dws dws;
#endif
/*rt task The load decreases by half with the sched period period.Look at this function: sched_avg_update*/
u64 rt_avg;
/* The run queue lifetime, which is different from the rq run time, is the value update when a cpu starts and the dispatcher
When initializing*/
u64 age_stamp;
/*Mark rq idle timestamp when a cpu becomes idle*/
u64 idle_stamp;
/*rq Average idle time*/
u64 avg_idle;
/* This is used to determine avg_idle's max value */
u64 max_idle_balance_cost;
#endif
/*In the WALT window assist load tracing article, how to calculate these parameters and how
Realized*/
#ifdef CONFIG_SCHED_WALT
u64 cumulative_runnable_avg;
u64 window_start;
u64 curr_runnable_sum;
u64 prev_runnable_sum;
u64 nt_curr_runnable_sum;
u64 nt_prev_runnable_sum;
u64 cur_irqload;
u64 avg_irqload;
u64 irqload_ts;
u64 cum_window_demand;
/*To solve a problem, we've added several flag s ourselves for high load (both windows are high load)
Use the running time of this task in the previous window to calculate the util of this task in the current window
Numeric value (cpu_util_freq calculated by this function).
The current system uses this task's ratio in the current window to calculate util. There may be frequency instability*/
enum {
CPU_BUSY_CLR = 0,
CPU_BUSY_PREPARE,
CPU_BUSY_SET,
} is_busy;
#endif /* CONFIG_SCHED_WALT */
#ifdef CONFIG_IRQ_TIME_ACCOUNTING
/*Calculate the timestamp of irq*/
u64 prev_irq_time;
#endif
#ifdef CONFIG_PARAVIRT
u64 prev_steal_time;
#endif
#ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING
u64 prev_steal_time_rq;
#endif
/* calc_load related fields */
/*Load balancing correlation*/
unsigned long calc_load_update;
long calc_load_active;
#ifdef CONFIG_SCHED_HRTICK
#ifdef CONFIG_SMP
int hrtick_csd_pending;
struct call_single_data hrtick_csd;
#endif
struct hrtimer hrtick_timer;
#endif
/*Statistical Dispatch Information Usage*/
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
unsigned long long rq_cpu_time;
/* could above be rq->cfs_rq.exec_clock + rq->rt_rq.rt_runtime ? */
/* sys_sched_yield() stats */
unsigned int yld_count;
/* schedule() stats */
unsigned int sched_count;
unsigned int sched_goidle;
/* try_to_wake_up() stats */
unsigned int ttwu_count;
unsigned int ttwu_local;
#ifdef CONFIG_SMP
/*Statistics EAS status information, since the new scheduler you see is based on EAS*/
struct eas_stats eas_stats;
#endif
#endif
#ifdef CONFIG_SMP
struct llist_head wake_list;
#endif
#ifdef CONFIG_CPU_IDLE
/* Must be inspected within a rcu lock section */
/*Set in cpu idle_enter_state, that is, when the cpu enters the corresponding idle state
Two parameters*/
struct cpuidle_state *idle_state;
int idle_state_idx;
#endif
};
At this point, the relevant important structures have been explained, but some of the structures involved in the load have not been explained, especially the algorithm for PELT to continue the load decay.
The next section describes initialization of the modem.