catalogue
2. Creation and operation of the scratch project
4. Basic composition of crawler file:
3. Working principle of scratch
1: Scarpy
(1) What is Scrapy:
Scrapy is an application framework written for crawling website data and extracting structural data. It can be applied to a series of programs, including data mining, information processing or storing historical data.
(2) To install the scene:
pip install scrapy
2. Creation and operation of the scratch project
1. Create a scene project:
Enter the name of the scene startproject project project in the terminal
2. Project composition:
spiders
__init__.py
Custom crawler file.py ‐‐‐> Created by ourselves, it is a file to realize the core functions of the crawler
__init__.py
items.py ‐‐‐> Where the data structure is defined, it is a class that inherits from scene.item
middlewares.py ‐‐‐> Middleware agent
pipelines.py ‐‐‐> There is only one class in the pipeline file, which is used for subsequent processing of downloaded data
The default is 300 priority. The smaller the value, the higher the priority (1-1000)
)
settings.py ‐‐‐> Configuration files, such as whether to comply with robots protocol,
User‐Agent
Definition, etc
3. Create a crawler file
a: Jump to spiders folder cd directory name
/Directory name
/spiders
b: scrapy genspider
The domain name of the crawler name page
4. Basic composition of crawler file:
Inherit the script
.
Spider
class
name
=
'baidu'
‐‐‐
>The name used to run the crawler file
allowed_domains
‐‐‐
>The domain name allowed by the crawler will be filtered out if it is not the url under the domain name
start_urls
‐‐‐
>It declares the starting address of the crawler and can write multiple
url
, usually a
parse
(
self
,
response
)
‐‐‐
>Callback function for parsing data
response
.
text
‐‐‐
>The response is a string
response
.
body
‐‐‐
>The response is binary
response
.
xpath
()
‐
>
xpath
The return value type of the method is
selector
list
extract
()
‐‐‐
>Extracted is
selector
The object is
data
extract_first
()
‐‐‐
>Extracted is
selector
First data in the list
5. Run crawler file:
Crawler name
Note: this should be done in the spiders folder
3. Working principle of scratch
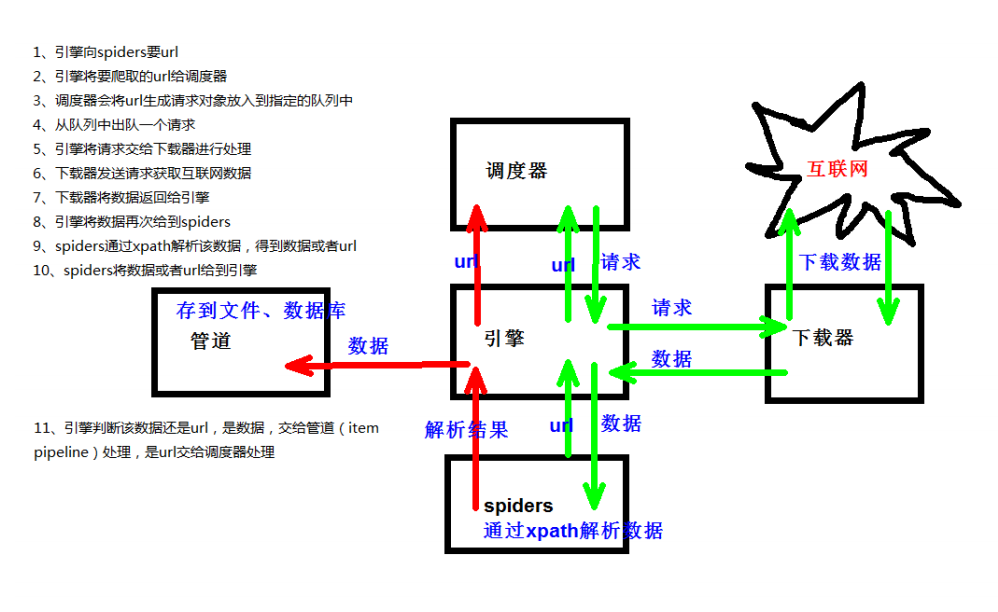
3.yield
1. With
yield
The function of is no longer an ordinary function, but a generator
generator
, available for iteration
2. yield is a similar
return
Keywords encountered once in iteration
yield
Return when
yield
behind
(
right
)
The key point is: the yield encountered in the next iteration from the previous iteration
Later code
(
next row
)
Start execution
4. Climbing Dangdang case
1: Project structure
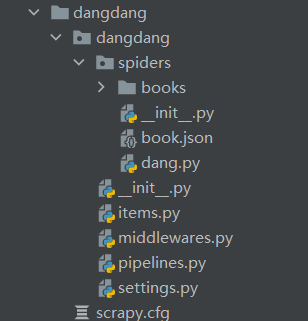
2: dang.py file
import scrapy
from dangdang.items import DangdangItem
class DangSpider(scrapy.Spider):
name = 'dang'
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
# src = //ul[@id="component_59"]/li//a/img/@src
# name = //ul[@id="component_59"]/li//a/img/@alt
# price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
print("========================================")
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
# Use @ src for the first picture and @ data original for other pictures
src = li.xpath('.//a/img/@data-original').extract_first()
if src:
src = src
else:
src = li.xpath('.//a/img/@src').extract_first()
name = li.xpath('.//a/img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
print(src,name,price)
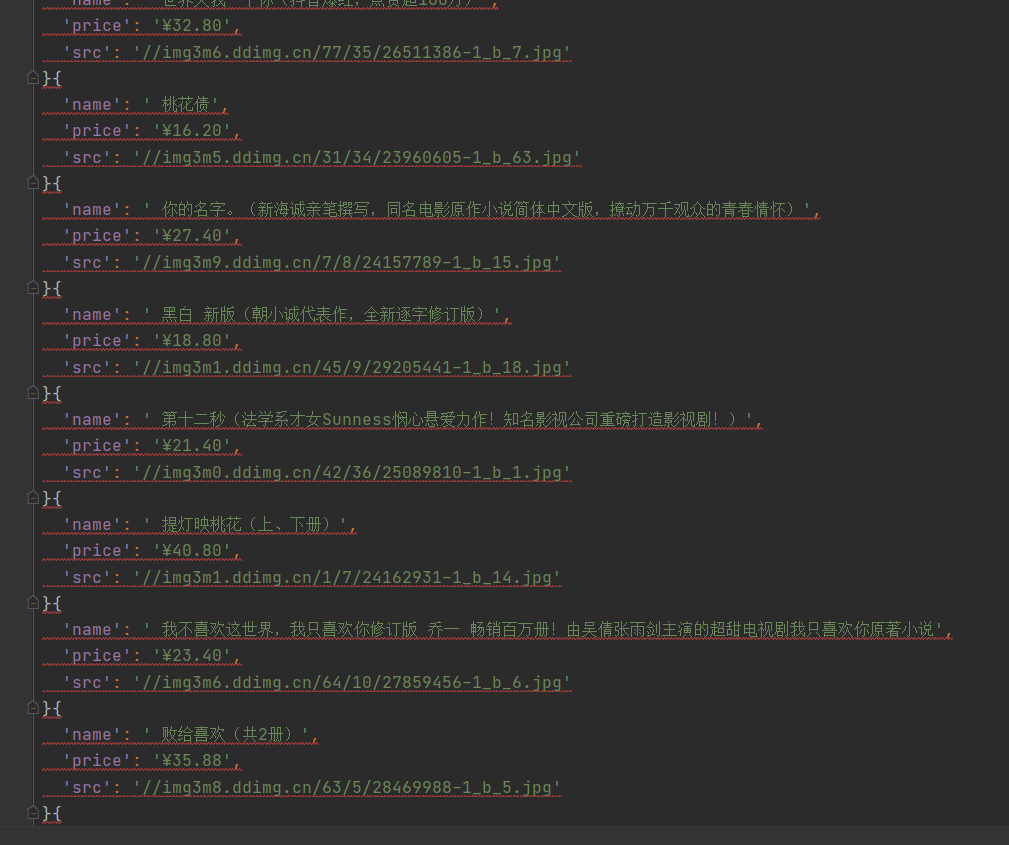
book = DangdangItem(src=src,name=name,price=price)
yield book
if self.page<100:
self.page =self.page+1
url =self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
# get request for a scratch
yield scrapy.Request(url=url,callback=self.parse)
2.items file
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field() # picture
name = scrapy.Field() # name
price = scrapy.Field() # Price3.pipelines file
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class DangdangPipeline:
# Before
def open_spider(self,spider):
self.f = open('book.json','w',encoding='utf-8')
# After
def close_spider(self,spider):
self.f.close()
# item is the book returned by yield
def process_item(self, item, spider):
# write must be a string
self.f.write(str(item))
return item
import urllib.request
# 'dangdang.pipelines.DangdangDownloadPipeline': 301, which needs to be enabled in setting
class DangdangDownloadPipeline:
# item is the book returned by yield
def process_item(self, item, spider):
url = 'http:'+item.get('src')
# The folder books needs to be established in advance
filename = './books/' + item.get('name') + '.jpg'
urllib.request.urlretrieve(url=url,filename=filename)
return item
5 operation screenshot