Preface
The text and pictures of this article are from the Internet, only for learning and communication, not for any commercial purpose. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Author: Xiaozhan & Arbor
PS: if you need Python learning materials, you can click the link below to get them by yourself
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
Invalid bookmarks
When we visit the website every day, we often encounter something new (you know. jpg), so we silently click a collection or bookmark. However, when we face hundreds of bookmarks and favorites, we always have a headache 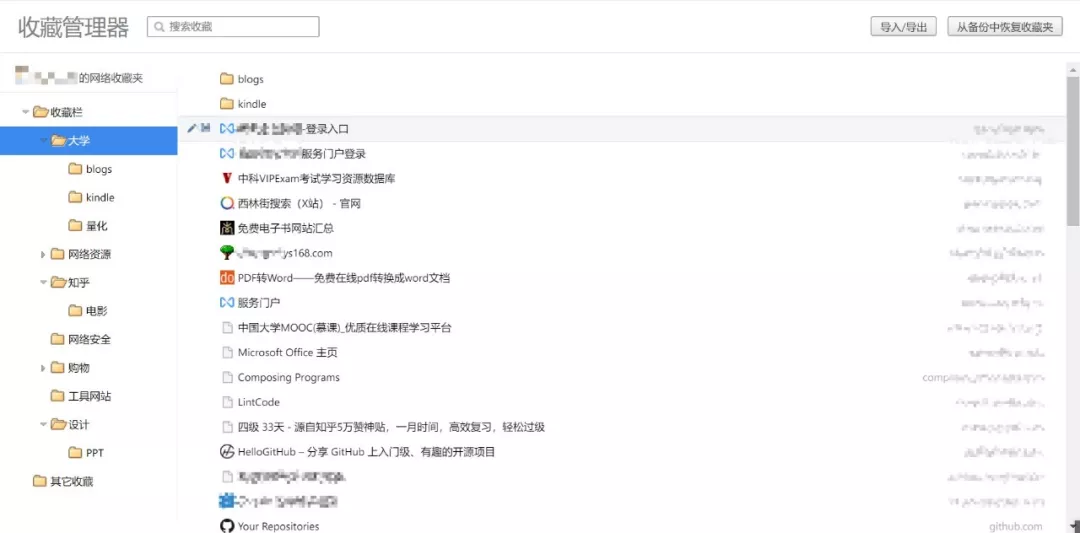
Especially yesterday's program design blog, which was still updated, hangs today and never updates. Or the vigorous movie website I saw yesterday, today is 404. There are so many invalid pages. Every time I open them, I know they are invalid, and they need to be deleted manually. Can this be the work of a programmer?
However, no matter Google browser or domestic browser, it can provide a backup service for favorites at most, which can only be started by Python.
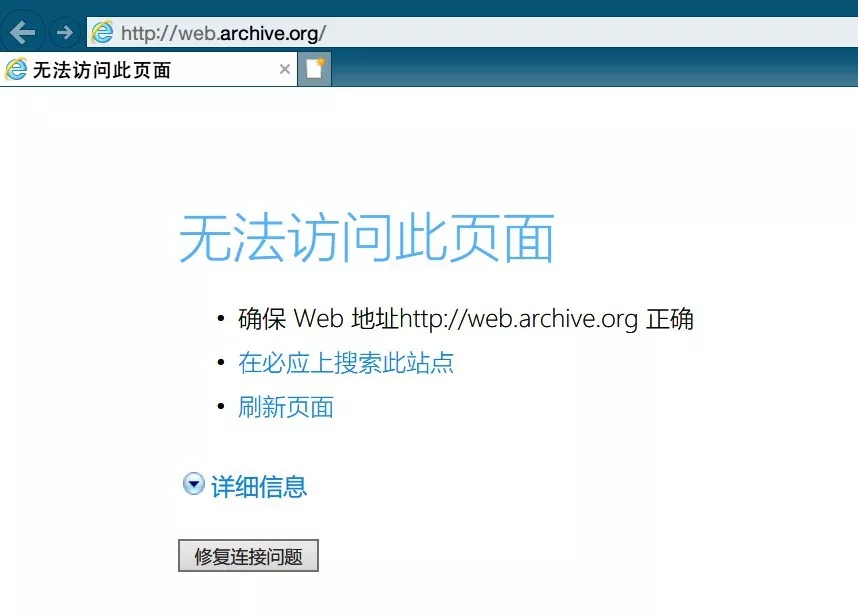
Favorite file formats supported by Python
There is little support for favorites, mainly because they are hidden in the browser. We can only manually export the htm file for management

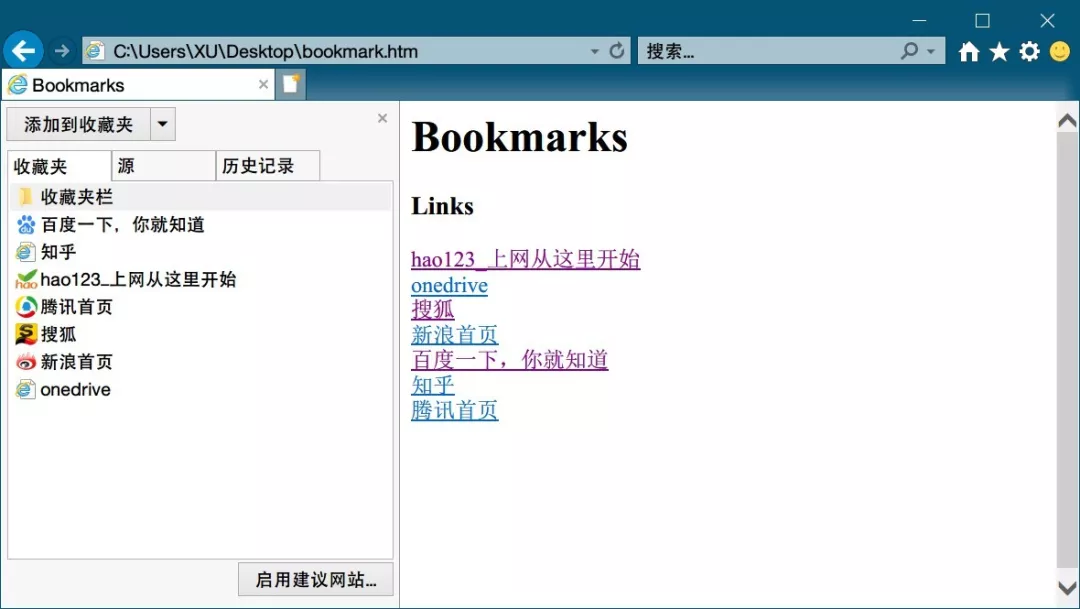
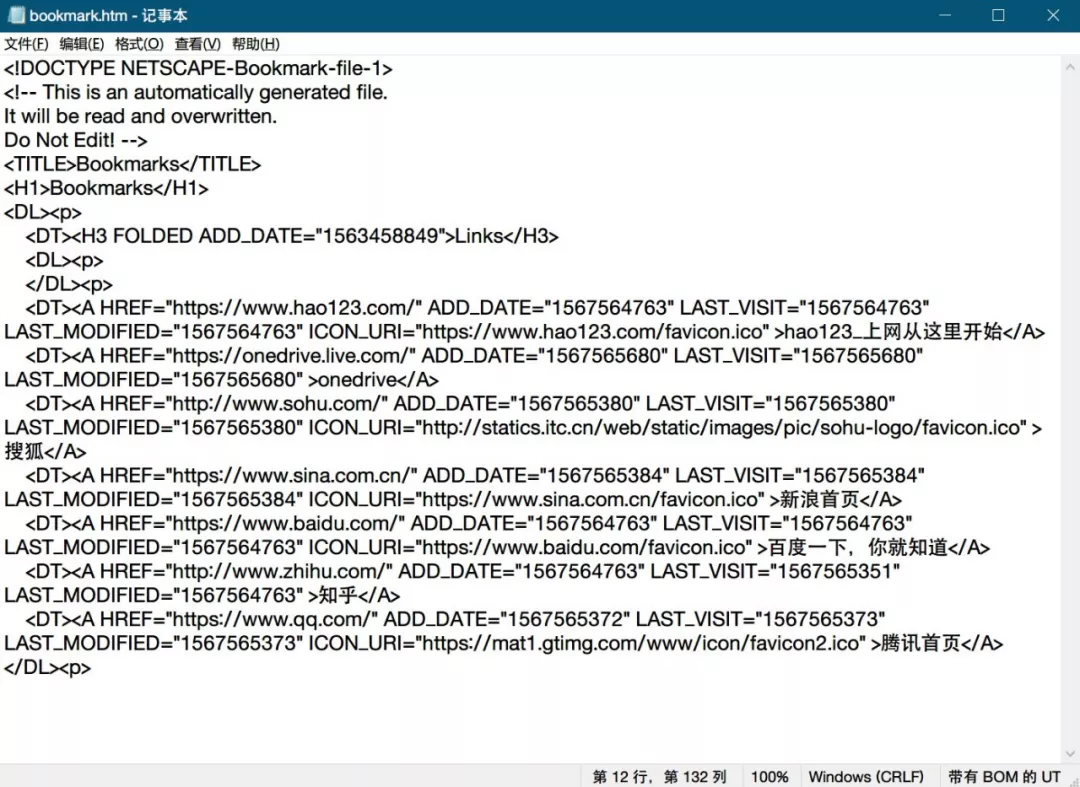
The content is relatively simple, and I don't know much about the front end. I can also clearly see the tree structure and internal logic. Fixed format URL fixed format page name fixed format
It's easy to think of regular matching, which has two substrings. Extract it and visit it one by one. If it fails, delete it and you will get the cleaned favorites.
Read favorites file
1 path = "C:\\Users\\XU\\Desktop" 2 3 fname = "bookmarks.html" 4 5 os.chdir(path) 6 7 bookmarks_f = open(fname, "r+" ,encoding='UTF-8') 8 9 booklists = bookmarks_f.readlines() 10 11 bookmarks_f.close()
Because you are not familiar with the front end, the exported favorites can be divided into abstract parts
-
Structure code
-
Key code to save web bookmarks
We can't move the structure code, we need to keep it intact, but we need to extract the content and judge whether to keep or delete the key code to save the bookmark.
So here we use the readlines function to read each line and judge separately.
Regular matching
1 pattern = r'HREF="(.*?)" .*?>(.*?)</A>' 2 while len(booklists)>0: 3 bookmark = booklists.pop(0) 4 detail = re.search(pattern, bookmark)
If it is a key code: the extracted substrings are in detail.group(1) and detail.group(2)
And if it's a structure code: detail == None
Access page
1 import requests 2 r = requests.get(detail.group(1),timeout=500)
There are four situations after coding attempts
-
r.status_code == requests.codes.ok
-
r.status_code==404
-
R.status_code! = 404 & & can't access (it may be blocked crawler, it is recommended to keep it)
-
requests.exceptions.ConnectionError
Similar to Zhihu and Jianshu, they are basically anti climbing, so simple get can't be accessed effectively, the details are not worth much effort, just keep them directly. For error, just throw an exception with try, or the program will stop running.
After adding logic: (code can be dragged left and right)
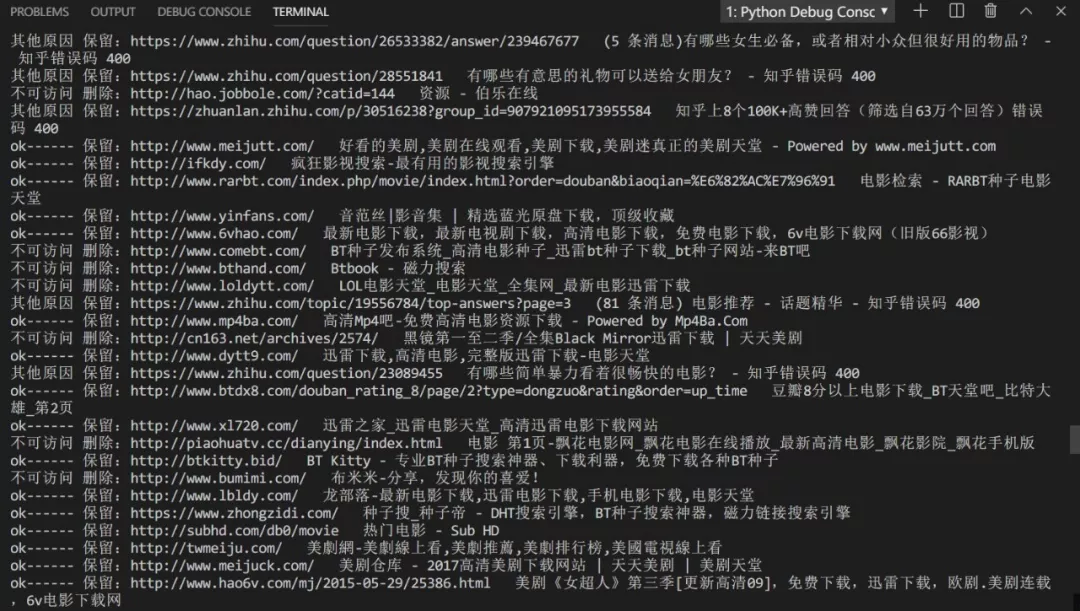
1 while len(booklists)>0: 2 bookmark = booklists.pop(0) 3 detail = re.search(pattern, bookmark) 4 if detail: 5 #print(detail.group(1) +"----"+ detail.group(2)) 6 try: 7 #Visit 8 r = requests.get(detail.group(1),timeout=500) 9 #Add if available 10 if r.status_code == requests.codes.ok: 11 new_lists.append(bookmark) 12 print( "ok------ Retain:"+ detail.group(1)+" "+ detail.group(2)) 13 else: 14 if(r.status_code==404): 15 print("Inaccessible delete:"+ detail.group(1)+" "+ detail.group(2) +'Error code '+str(r.status_code)) 16 else: 17 print("Reserved for other reasons:"+ detail.group(1)+" "+ detail.group(2) +'Error code '+str(r.status_code)) 18 new_lists.append(bookmark) 19 except: 20 print( "Inaccessible delete:"+ detail.group(1)+" "+ detail.group(2)) 21 #new_lists.append(bookmark) 22 else:#No matching to structure statement 23 new_lists.append(bookmark)
Procedure implementation
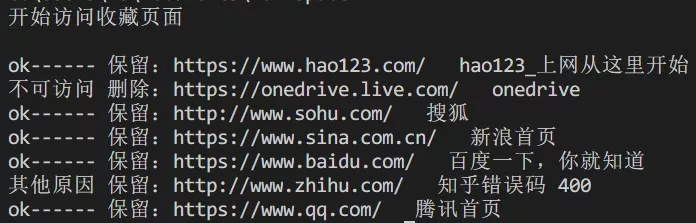
Export htm
1 bookmarks_f = open('new_'+fname, "w+" ,encoding='UTF-8') 2 bookmarks_f.writelines(new_lists) 3 bookmarks_f.close()
Import browser
Apply to my browser
.