lab1—util
Before we begin, it is necessary to understand how the parameters we enter on the command line are passed to the program. For this purpose, I refer to the content of csapp.
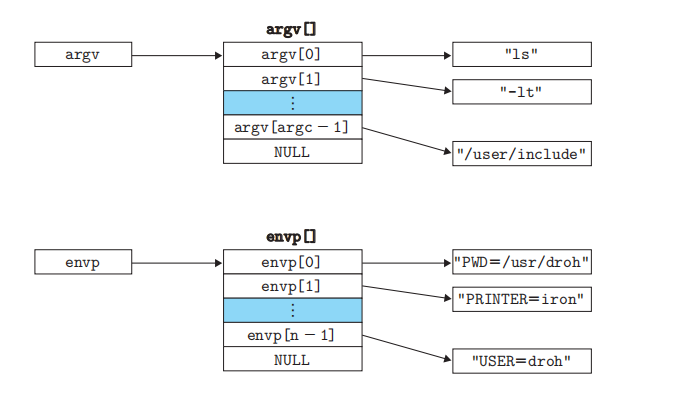
When you input a line of command string in the command line and press enter, the shell program first parses the line of command string you input, and the parser stores the line of string you input in a character array argv, as shown in the following figure. Each element of the array is part of your input. Then the shell program determines whether the command is a shell built-in command according to argv[0]. If it is a shell built-in command, it directly executes the shell built-in instruction. If it is not the shell built-in command, then shell program calls fork() to create a sub process, and then calls execve() function in this sub process, such as execve (argv[0], execve). As shown in the figure below, it stores an environ ment variable string array. The execve function loads and executes the executable argv [0]. The loading process is briefly described below.
This loading process is completed by a program called loader in the operating system. The loader deletes the existing virtual memory segments of the child process and creates a new set of code, data, heap and stack segments. The new stack and heap segments are initialized to zero. By mapping the pages in the virtual address space (note that they are not copied directly) to the page size slice of the executable file, the new code and data segments are initialized to the contents of the executable file. Finally, the loader jumps to_ The address of the start function, which is defined in the system object file ctrl.o_ Start function call function__ libc_start_main, this function is defined in libc.so. It initializes the execution environment (set the stack, that is, the parameters of main, and set the stack as shown in the figure below), calls the main function of the user layer, processes the return value of the main function, and returns the control to the kernel when necessary.
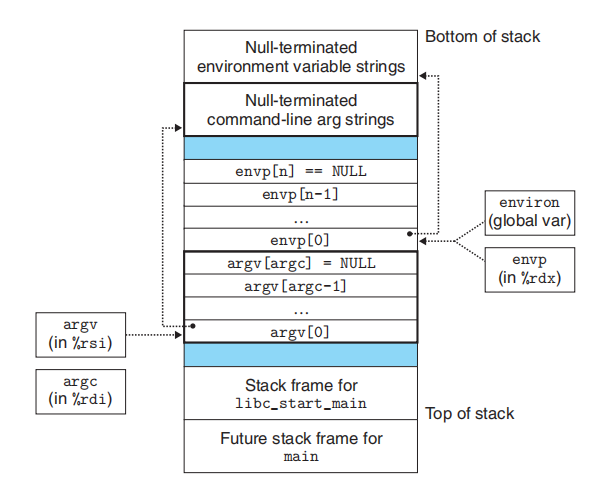
In other words, the parameters we pass on the command line are successively passed to the shell, the shell command parser, execv function and loader_ Start function, libc_ start_ The main function is finally passed to the main function of the command we want to execute.
sleep
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int argc, char *argv[])
{
int i;
const char *str = "sleep: usage: sleep [integer]\n";
if (argc != 2){
write(1, str, strlen(str));
exit(0);
}
i = atoi(argv[1]);
sleep(i);
exit(0);
return 0;
}
The time parameter passed to argv from the command line is a string, which can be converted to integer by calling atoi function according to the prompt. Then you can call the sleep function.
pingpong
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int argc, char *argv[])
{
int pfd[2];
int cfd[2];
int pid;
char buff[1];
if (argc != 1){
fprintf(2, "pingpong: usage: pingpong\n", 26);
exit(1);
}
pipe(pfd);
pipe(cfd);
if ((pid = fork()) == 0){
close(pfd[1]);
close(cfd[0]);
if (read(pfd[0], buff, 1) == 1){
printf("%d: received ping\n", getpid());
write(cfd[1], buff, 1);
close(pfd[0]);
close(cfd[1]);
exit(0);
}
}
else{
close(pfd[0]);
close(cfd[1]);
write(pfd[1], buff, 1);
wait(0);
if (read(cfd[0], buff, 1) == 1){
printf("%d: received pong\n", getpid());
close(pfd[1]);
close(cfd[0]);
exit(0);
}
}
return 0;
}
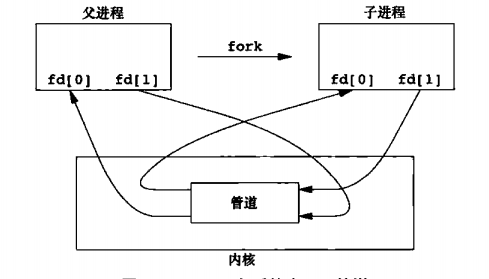
The main purpose here is to understand the pipe() system call. Here I will talk about the pipe system call. The pipeline is half duplex, and data can only flow from one end to the other. Moreover, pipes can only be used between two processes with common ancestors. The most common is that parent-child processes communicate with pipes. To use a pipe, a file descriptor must be turned off at both ends of the pipe, for example:
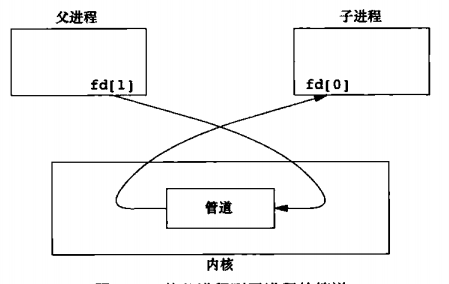
The parent process closes fd[0], the child process closes fd[1], and the data flow direction is parent process → child process, which can be used for the parent process to send data to the child process.
primes
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
void prime(int fd[]){
int i, j;
int pid;
int cfd[2];
close(fd[1]);
if (read(fd[0], &i, 4) == 0){
close(fd[0]);
exit(0);
}
printf("%d\n", i);
pipe(cfd);
if ((pid = fork()) == 0){
close(fd[0]);
prime(cfd);
}
else {
close(cfd[0]);
while (read(fd[0], &j, 4) != 0){
if (j % i != 0)
write(cfd[1], &j, 4);
}
close(fd[0]);
close(cfd[1]);
wait(0);
}
exit(0);
}
int main(int argc, char **argv)
{
if (argc != 1){
fprintf(2, "primes: usage: primes\n");
exit(1);
}
int fd[2];
int pid;
pipe(fd);
if((pid = fork()) == 0)
prime(fd);
else{
close(fd[0]);
for (int i = 2; i <= 35; i++){
write(fd[1], &i, 4);
}
close(fd[1]);
wait(0);
}
exit(0);
return 0;
}
The following figure describes the process of this algorithm:
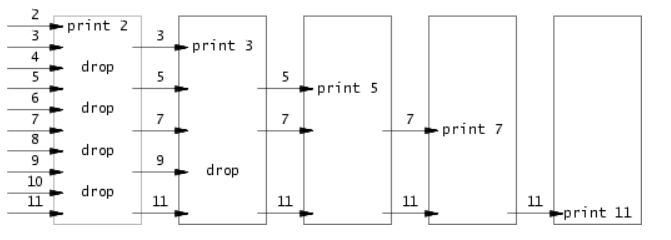
The official also gives the pseudo code of this algorithm:
p = get a number from left neighbor
print p
loop:
n = get a number from left neighbor
if (p does not divide n)
send n to right neighbor
find
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
void find(const char *path, const char *fname){
int fd;
char buf[512], *p;
struct dirent de;
struct stat st;
if ((fd = open(path, 0)) < 0){
fprintf(2, "find: cannot open %s\n", path);
return;
}
strcpy(buf, path);
p = buf + strlen(buf);
*p++ = '/';
while(read(fd, &de, sizeof(de)) == sizeof(de)){
if (strcmp(de.name, ".") == 0 || strcmp(de.name, "..") == 0)
continue;
if (de.inum == 0) //??
continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
if (stat(buf, &st) < 0){
fprintf(2, "find: cannot stat %s\n", buf);
return;
}
switch(st.type){
case T_FILE:
if (strcmp(de.name, fname) == 0)
printf("%s\n", buf);
break;
case T_DIR:
find(buf, fname);
break;
}
}
close(fd);
return;
}
int main(int argc, char **argv)
{
if (argc != 3){
fprintf(2, "find: usage: find [path] [file name]\n");
exit(1);
}
find(argv[1], argv[2]);
exit(0);
return 0;
}
But what I don't quite understand here is that de.inum == 0 in while can't pass without adding these two lines. I think there are these two lines in ls code, so it can pass after adding them. Let's take a look after learning the file system of xv6.
The official prompts us to read the code of usr/ls.c. to understand the code, we need to have a little knowledge of the file system.
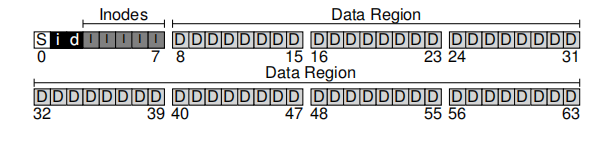
Assuming that the disk is divided into 4KB blocks one by one, these blocks can be divided into areas as shown above. S represents super block, i and d are inode bitmap and data bitmap respectively. The bitmap is used to record the usage of inode blocks or data blocks. Inodes are inodes. A file corresponds to an inode. Inodes store the metadata of the file. The Data Region stores the actual data of the file. The information stored in inode can find the data block belonging to the file.
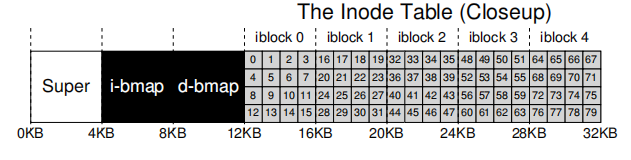
The inode number will be mentioned many times below. What is the inode number? In fact, it is the index of an inode in inodes, which can be regarded as an array. As shown in the figure below, if the size of an inode is 256 bytes, a 4KB block can store 16 inodes. Treat them as an array, then each inode has an index, which is the inode number.
Now I'll just explain the dirent and stat structures. These two structures are defined in kernel/stat.h and kernel/fs.h respectively.
struct stat {
int dev; // File system's disk device
uint ino; // Inode number
short type; // Type of file
short nlink; // Number of links to file
uint64 size; // Size of file in bytes
};
struct dirent {
ushort inum;
char name[DIRSIZ];
};
It can be found that the stat stores inode number, file type, number of hard links and other information, which can be read from the inodes in the figure above. So where is the file name stored? The file name is stored in the directory, that is, in the dirent structure. The directory is also a file, but the data in it is the list of dirent. The inode number and file name of the file are stored in dirent. Each file in the directory can be traversed by reading the dirent in the directory separately.
xargs
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/param.h"
int main(int argc, char **argv)
{
if (argc < 2){
fprintf(1, "xargs: usage: somecommand |xargs command\n");
exit(0);
}
char *params[MAXARG];
char buf[512];
int index = 0;
int n;
for (int i = 1; i != argc; ++i){
params[i-1] = argv[i];
}
while(1){
index = 0;
while((n = read(0, &buf[index], 1)) != 0){
if (buf[index] == '\n'){
buf[index] = 0;
break;
}
++index;
}
if (n == 0)
break;
params[argc - 1] = buf;
if (fork() == 0){
exec(argv[1], params);
}
else{
wait(0);
}
}
exit(0);
return 0;
}
This function is interesting. It involves the transfer of parameters from the parent process to the child process. It reads data from standard input as additional parameters to the command on the right. When a newline character is encountered, you need to re create a process with fork and exec, and add the character before the newline character to the parameter list.
reference material
Computer Systems: A Programmer's Perspective (3rd Edition)
Advanced programming in Unix Environment
operating systems three easy pieces