The links included in the development and application of machine learning introduce the method and process of running machine learning based on Tensorflow framework on apache hadoop yarn
(Introduction to the links involved in development and application of machine learning, and the method and process of running machine learning based on the Tensorflow framework on Apache hadoop yarn.)
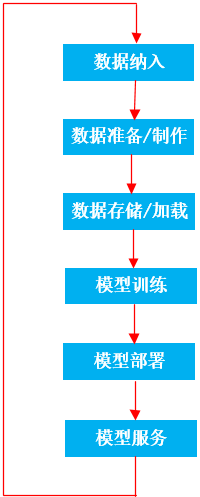
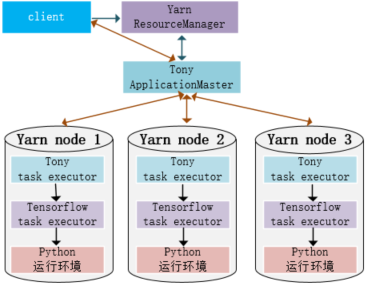
There are many links in the development and application of machine learning, including data inclusion, data preparation / production, data storage / loading, model training, model deployment and model service; After the data we produce and collect in production and non production environments are incorporated into the machine learning system, we will first preliminarily process, process and prepare the data, and then store it in different places, such as distributed storage system (HDFS) and file system; Loading data into the model during training consumes a lot of memory resources, and training consumes a lot of CPU/GPU resources. With the increase of the amount of data and the complexity of the model, the hardware resources of single node / single host reach the bottleneck. A good way is to let machine learning run directly on multiple machines or distributed clusters. Tensorflow version 2. X supports distributed training, but does not support Hadoop yarn. TonY component is required to support it. The responsibilities of TonY component are as follows:
- Obtain the resources required for machine learning training from Hadoop yarn, such as machine nodes, memory and CPU/GPU resources;
- Provide and initialize the environment required for tensorflow machine learning;
The following describes how machine learning based on tensorflow framework runs on hadoop yarn through a case. The case and data are from the tensorflow film review text classification (reference 1). The case scores the film review text according to positive or negative comments.
1 data preparation
Download the case data, extract the training data and test data, and store the data on hdfs;
-rw-r----- 3 hive hdfs 1641221 2021-11-16 15:57 hdfs://testcs/tmp/tensorflow/imdb/imdb_word_index.json -rw-r----- 3 hive hdfs 13865830 2021-11-16 15:26 hdfs://testcs/tmp/tensorflow/imdb/x_test.npy -rw-r----- 3 hive hdfs 14394714 2021-11-16 15:26 hdfs://testcs/tmp/tensorflow/imdb/x_train.npy -rw-r----- 3 hive hdfs 200080 2021-11-16 15:26 hdfs://testcs/tmp/tensorflow/imdb/y_test.npy -rw-r----- 3 hive hdfs 200080 2021-11-16 15:26 hdfs://testcs/tmp/tensorflow/imdb/y_train.npy
2 environmental preparation
Since only the basic python running environment is installed on the cluster host, we may need various python third-party packages in actual machine learning projects. In order to avoid running conflicts between different projects, we use virtualenv to realize virtualization.
tar -xvf virtualenv-16.0.0.tar.gz #decompression python virtualenv-16.0.0/virtualenv.py venv #Create virtual environment . venv/bin/activate #Activate virtual environment pip install tensorflow #Installation package
After installation, package the virtual environment for runtime use on the yarn cluster.
zip -r venv.zip venv
3 create project
Create a machine learning project and put the code in the src directory. Since the training and test data are stored on hdfs and cannot be read in the way of ordinary file system, you need to refer to hadoop class library and use tensorflow_ Read IO class library;
with tf.io.gfile.GFile('hdfs://testcs/tmp/tensorflow/imdb/x_train.npy', mode='rb') as r:
x_train=np.load(r,allow_pickle=True)
with tf.io.gfile.GFile('hdfs://testcs/tmp/tensorflow/imdb/y_train.npy', mode='rb') as r:
labels_train=np.load(r,allow_pickle=True)
Finally, create a tony configuration file to configure how many resources are needed, such as two instances, and the instance memory resource is 4G;
vi tony-mypro01.xml
<configuration>
<property>
<name>tony.worker.instances</name>
<value>2</value>
</property>
<property>
<name>tony.worker.memory</name>
<value>4g</value>
</property>
</configuration>
After the development, the following project structure is obtained;
/ ├── MyPro01 │ ├── src │ │ └── models │ │ └── movie_comm02.py │ └── tony-mypro01.xml ├── tony-cli-0.4.10-uber.jar └── venv.zip
4 submission and operation
java -cp `hadoop classpath`:tony-cli-0.4.10-uber.jar:MyPro01/*:MyPro01 com.linkedin.tony.cli.ClusterSubmitter \ --python_venv=venv.zip \ --src_dir=MyPro01/src \ --executes=models/movie_comm02.py \ --task_params="--data_dir hdfs://testcs/tmp/tensorflow/input --output_dir hdfs://testcs/tmp/tensorflow/output " \ --conf_file=MyPro01/tony-mypro01.xml \ --python_binary_path=venv/bin/python
The parameters are described in (reference 2). The client submits the job to yarn resourcemanger, applies for the required resources and creates a job;

The job consists of one applicationMaster and two jobs. TonY initializes the tensorflow environment and trains on the two jobs;
21/11/20 17:56:30 INFO tony.TonyClient: Starting client..
21/11/20 17:56:30 INFO client.RMProxy: Connecting to ResourceManager at 192.168.1.13/192.168.1.10:8050
21/11/20 17:56:30 INFO client.AHSProxy: Connecting to Application History server at 192.168.1.12/192.168.1.11:10200
21/11/20 17:56:30 INFO conf.Configuration: found resource resource-types.xml at file:/opt/hadoop/etc/hadoop/resource-types.xml
21/11/20 17:56:33 INFO tony.TonyClient: Running with secure cluster mode. Fetching delegation tokens..
21/11/20 17:56:33 INFO tony.TonyClient: Fetching RM delegation token..
21/11/20 17:56:33 INFO tony.TonyClient: RM delegation token fetched.
21/11/20 17:56:33 INFO tony.TonyClient: Fetching HDFS delegation tokens for default, history and other namenodes...
21/11/20 17:56:33 INFO hdfs.DFSClient: Created token for hive: HDFS_DELEGATION_TOKEN owner=hive/testcs@testcsKDC, renewer=yarn, realUser=, issueDate=1637402193823, maxDate=1638006993823, sequenceNumber=9827, masterKeyId=635 on ha-hdfs:testcs
21/11/20 17:56:33 INFO security.TokenCache: Got delegation token for hdfs://testcs; Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:testcs, Ident: (token for hive: HDFS_DELEGATION_TOKEN owner=hive/testcs@testcsKDC, renewer=yarn, realUser=, issueDate=1637402193823, maxDate=1638006993823, sequenceNumber=9827, masterKeyId=635)
21/11/20 17:56:33 INFO tony.TonyClient: Fetched HDFS delegation token.
21/11/20 17:56:33 INFO tony.TonyClient: Successfully fetched tokens.
21/11/20 17:56:34 INFO tony.TonyClient: Completed setting up Application Master command {{JAVA_HOME}}/bin/java -Xmx1638m -Dyarn.app.container.log.dir=<LOG_DIR> com.linkedin.tony.ApplicationMaster 1><LOG_DIR>/amstdout.log 2><LOG_DIR>/amstderr.log
21/11/20 17:56:34 INFO tony.TonyClient: Submitting YARN application
21/11/20 17:56:34 INFO impl.TimelineClientImpl: Timeline service address: null
21/11/20 17:56:34 INFO impl.YarnClientImpl: Submitted application application_1623855961871_1372
21/11/20 17:56:34 INFO tony.TonyClient: URL to track running application (will proxy to TensorBoard once it has started): http://192.168.1.13:8088/proxy/application_1623855961871_1372/
21/11/20 17:56:34 INFO tony.TonyClient: ResourceManager web address for application: http://192.168.1.13:8088/cluster/app/application_1623855961871_1372
21/11/20 17:56:41 INFO tony.TonyClient: Driver (application master) log url: http://192.168.1.12:8042/node/containerlogs/container_e75_1623855961871_1372_01_000001/hive
21/11/20 17:56:41 INFO tony.TonyClient: AM host: 192.168.1.12
21/11/20 17:56:41 INFO tony.TonyClient: AM RPC port: 42458
21/11/20 17:56:41 WARN ipc.Client: Exception encountered while connecting to the server : java.io.IOException: Connection reset by peer
21/11/20 17:56:43 INFO tony.TonyClient: ------ Application (re)starts, status of ALL tasks ------
21/11/20 17:56:43 INFO tony.TonyClient: RUNNING, worker, 0, http://192.168.1.10:8042/node/containerlogs/container_e75_1623855961871_1372_01_000002/hive
21/11/20 17:56:43 INFO tony.TonyClient: RUNNING, worker, 1, http://192.168.1.10:8042/node/containerlogs/container_e75_1623855961871_1372_01_000003/hive
21/11/20 17:58:04 INFO tony.TonyClient: ------ Task Status Updated ------
21/11/20 17:58:04 INFO tony.TonyClient: SUCCEEDED: worker [1]
21/11/20 17:58:04 INFO tony.TonyClient: RUNNING: worker [0]
21/11/20 17:58:07 INFO tony.TonyClient: ------ Task Status Updated ------
21/11/20 17:58:07 INFO tony.TonyClient: SUCCEEDED: worker [0, 1]
21/11/20 17:58:07 INFO tony.TonyClient: ----- Application finished, status of ALL tasks -----
21/11/20 17:58:07 INFO tony.TonyClient: SUCCEEDED, worker, 0, http://192.168.1.10:8042/node/containerlogs/container_e75_1623855961871_1372_01_000002/hive
21/11/20 17:58:07 INFO tony.TonyClient: SUCCEEDED, worker, 1, http://192.168.1.10:8042/node/containerlogs/container_e75_1623855961871_1372_01_000003/hive
21/11/20 17:58:07 INFO tony.TonyClient: Application 1372 finished with YarnState=FINISHED, DSFinalStatus=SUCCEEDED, breaking monitoring loop.
21/11/20 17:58:07 INFO tony.TonyClient: Link for application_1623855961871_1372's events/metrics: https://localhost:19886/jobs/application_1623855961871_1372
21/11/20 17:58:07 INFO tony.TonyClient: Sending message to AM to stop.
21/11/20 17:58:07 INFO tony.TonyClient: Application completed successfully
21/11/20 17:58:07 INFO impl.YarnClientImpl: Killed application application_1623855961871_1372
The information generated during the training can be found in the work log.

5 Summary
To make the machine learning based on Tensorflow framework run on hadoop yarn, we first need to deploy the basic python running environment on the yarn node; When developing a machine learning project, create an independent python virtual environment with virtualenv, install the packages required by the project, and then package the virtual environment. When running the job, submit it to the yarn cluster together with the machine learning code. TonY component is responsible for applying resources to the yarn resource manager, initializing the environment and running machine learning.
reference material
- one https://tensorflow.google.cn/tutorials/keras/text_ Classification - text classification of film reviews
- 2 https://github.com/tony-framework/TonY - Tony