Apache Spark is a fast and versatile computing engine designed for large-scale data processing. It can perform a wide range of operations, including SQL queries, text processing, machine learning, etc. Before the advent of Spark, we generally needed to learn a variety of engines to handle these requirements separately.The main purpose of this article is to provide you with a very simple way to deploy a Spark cluster on the Ali cloud.
adopt <Aliyun ROS Resource Arrangement Service> , create VPC, NAT Gateway, ECS, automate Hadoop and Spark deployment process, and make it very convenient for you to deploy a Spark cluster.The Spark cluster created in this paper consists of three nodes: master.hadoop, slave1.hadoop, and slave2.hadoop.
Rapid Deployment of Spark Clusters
One-Click Deployment of Spark Cluster >>

Be careful:
- You must ensure that you can download the Jdk, Hadoop, Scala, and Spark installation packages correctly. We can choose URL s like the following:
- http://download.oracle.com/otn-pub/java/jdk/8u121-b13/e9e7ea248e2c4826b92b3f075a80e441/jdk-8u121-linux-x64.tar.gz
- http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.7.1/hadoop-2.7.1.tar.gz
- https://downloads.lightbend.com/scala/2.12.1/scala-2.12.1.tgz
- http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.7.tgz
- When creating with this template, only the CentOS system can be selected;
- To prevent Timeout from failing, set it to 120 minutes;
- The data center we selected is in Shanghai/Beijing.
ROS Template Install Spark Quartets
Spark relies on many environments. Generally, there are four steps to install Spark: install and configure the Hadoop cluster, install and configure Scala, install and configure the Spark package, and start the test cluster.
1. Install Configuration Hadoop
Installing Hadoop is complicated, as we did on our previous blog Ali Cloud One-Click Deployment of Hadoop Distributed Clusters Detailed descriptions have already been made and will not be repeated here.
2. Install Configuration Scala
Spark is implemented in Scala, which uses Scala as its application framework and makes it as easy to manipulate distributed datasets as local collection objects.
"aria2c $ScalaUrl \n",
"mkdir -p $SCALA_HOME \ntar zxvf scala-*.tgz -C $SCALA_HOME \ncd $SCALA_HOME \nmv scala-*.*/* ./ \nrmdir scala-*.* \n",
"echo >> /etc/profile \n",
"echo export SCALA_HOME=$SCALA_HOME >> /etc/profile \n",
"echo export PATH=$PATH:$SCALA_HOME/bin >> /etc/profile \n",
"ssh root@$ipaddr_slave1 \"mkdir -p $SCALA_HOME; mkdir -p $SPARK_HOME; exit\" \n",
"ssh root@$ipaddr_slave2 \"mkdir -p $SCALA_HOME; mkdir -p $SPARK_HOME; exit\" \n",
"scp -r $SCALA_HOME/* root@$ipaddr_slave1:$SCALA_HOME \n",
"scp -r $SCALA_HOME/* root@$ipaddr_slave2:$SCALA_HOME \n",
3. Install Configuration Spark
Install Spark on Master, remotely copy the correctly configured Spark Home directory to the Slave host, and set environment variables.
"aria2c $SparkUrl \n",
"mkdir -p $SPARK_HOME \ntar zxvf spark-*hadoop*.tgz -C $SPARK_HOME \ncd $SPARK_HOME \nmv spark-*hadoop*/* ./ \nrmdir spark-*hadoop* \n",
"echo >> /etc/profile \n",
"echo export SPARK_HOME=$SPARK_HOME >> /etc/profile \n",
"echo export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin >> /etc/profile \n",
"source /etc/profile \n",
" \n",
"cp $SPARK_HOME/conf/slaves.template $SPARK_HOME/conf/slaves \n",
"echo $ipaddr_slave1 > $SPARK_HOME/conf/slaves \n",
"echo $ipaddr_slave2 >> $SPARK_HOME/conf/slaves \n",
"cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh \n",
"echo export SCALA_HOME=$SCALA_HOME > $SPARK_HOME/conf/spark-env.sh \n",
"echo export JAVA_HOME=$JAVA_HOME >> $SPARK_HOME/conf/spark-env.sh \n",
"scp -r $SPARK_HOME/* root@$ipaddr_slave1:$SPARK_HOME \n",
"scp -r $SPARK_HOME/* root@$ipaddr_slave2:$SPARK_HOME \n",
" \n",
"ssh root@$ipaddr_slave1 \"echo >> /etc/profile;echo export SCALA_HOME=$SCALA_HOME >> /etc/profile;echo export PATH=$PATH:$SCALA_HOME/bin >> /etc/profile;echo export SPARK_HOME=$SPARK_HOME >> /etc/profile;echo export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin >> /etc/profile;exit\" \n",
"ssh root@$ipaddr_slave2 \"echo >> /etc/profile;echo export SCALA_HOME=$SCALA_HOME >> /etc/profile;echo export PATH=$PATH:$SCALA_HOME/bin >> /etc/profile;echo export SPARK_HOME=$SPARK_HOME >> /etc/profile;echo export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin >> /etc/profile;exit\" \n",
4. Start a test cluster
Finally, format the HDFS, close the firewall, and start the cluster.
"hadoop namenode -format \n",
"systemctl stop firewalld \n",
"$HADOOP_HOME/sbin/start-dfs.sh \n",
"$HADOOP_HOME/sbin/start-yarn.sh \n",
"$SPARK_HOME/sbin/start-all.sh \n",
Test deployment results
Once created, review the resource stack overview: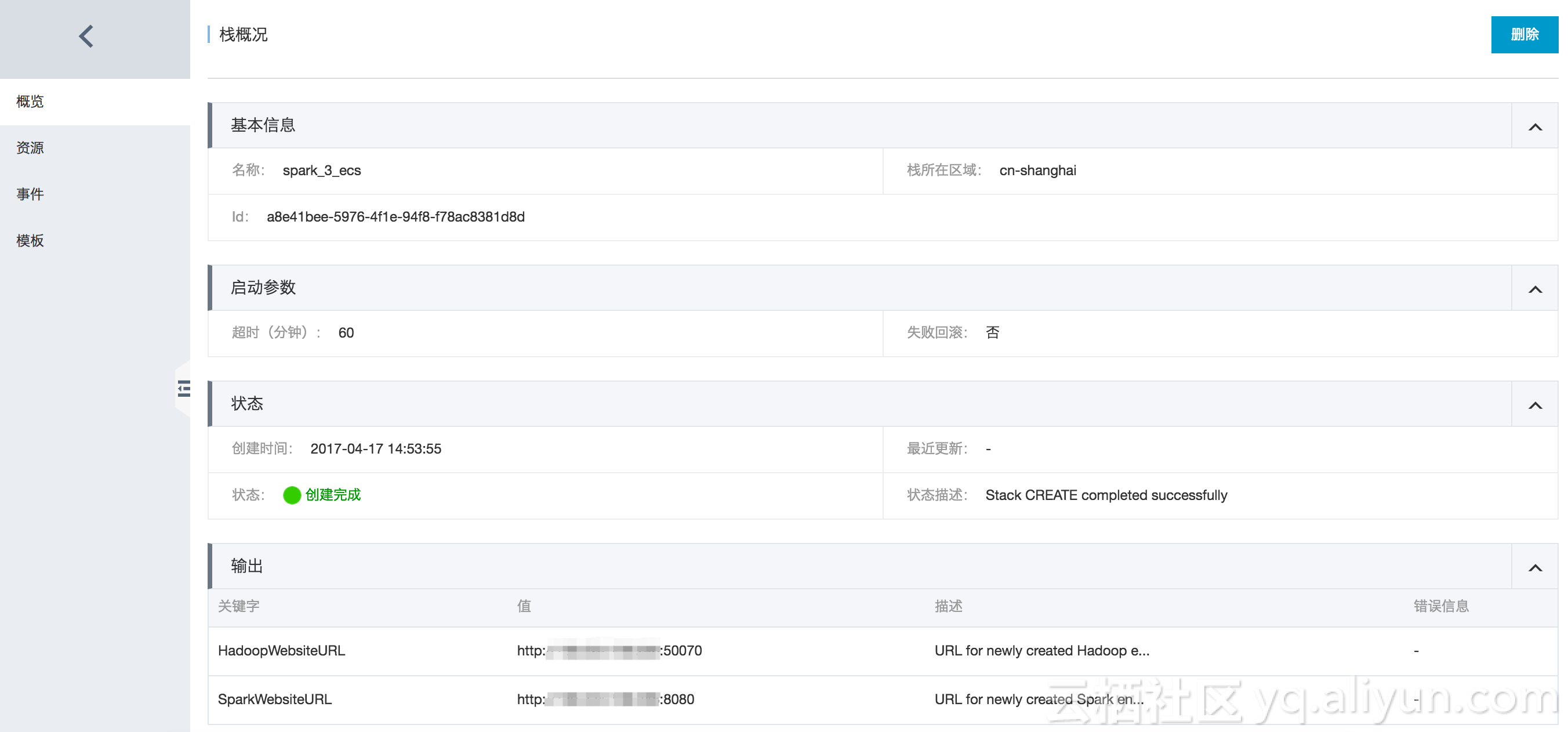
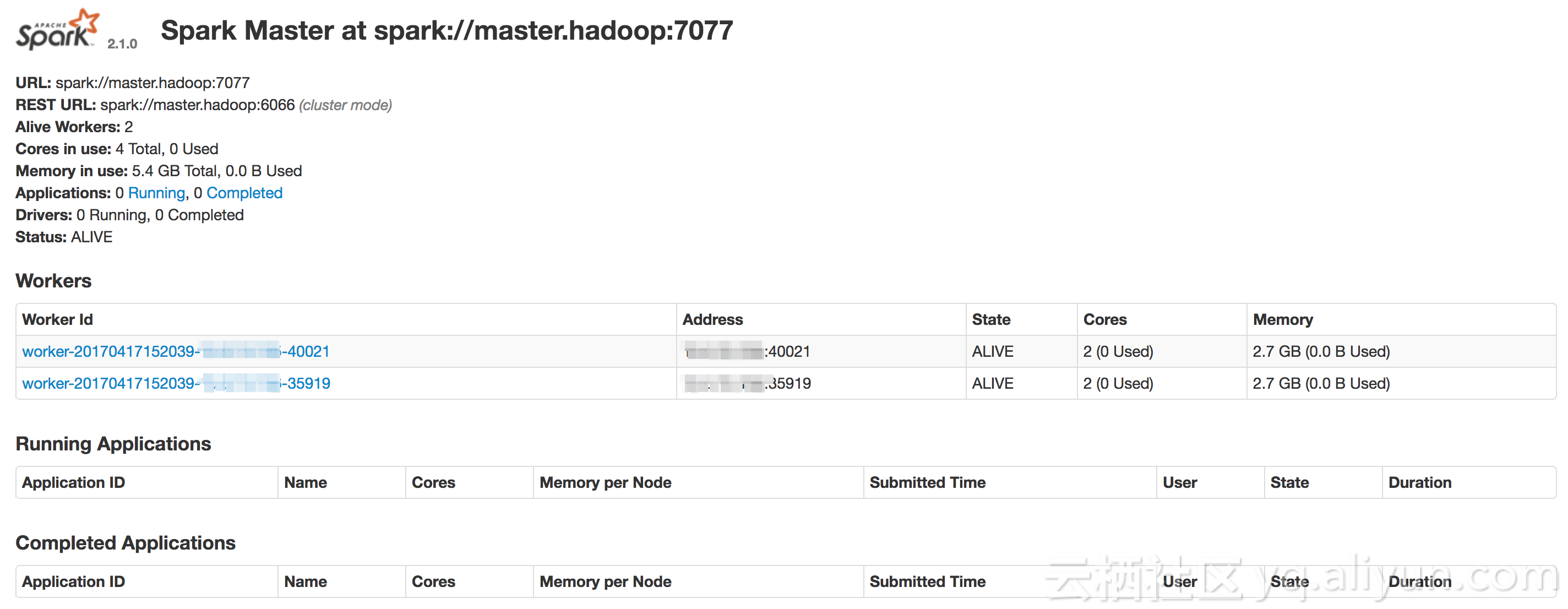
Enter the SparkWebsiteURL in the diagram in the browser and the following results will be successful: