Preface
stay Last article It reviews three major features of Java: encapsulation, inheritance and polymorphism. This article will introduce the next collection.
Collection introduction
When we develop Java programs, we often use collection-related classes in addition to the most commonly used basic data types and String objects.
Collection classes store references to objects, not objects themselves. For the convenience of expression, we call objects in collections refer to references to objects in collections.
There are three main types of collections: List, Set, and Map.
The relationship between them can be represented by the following figure:
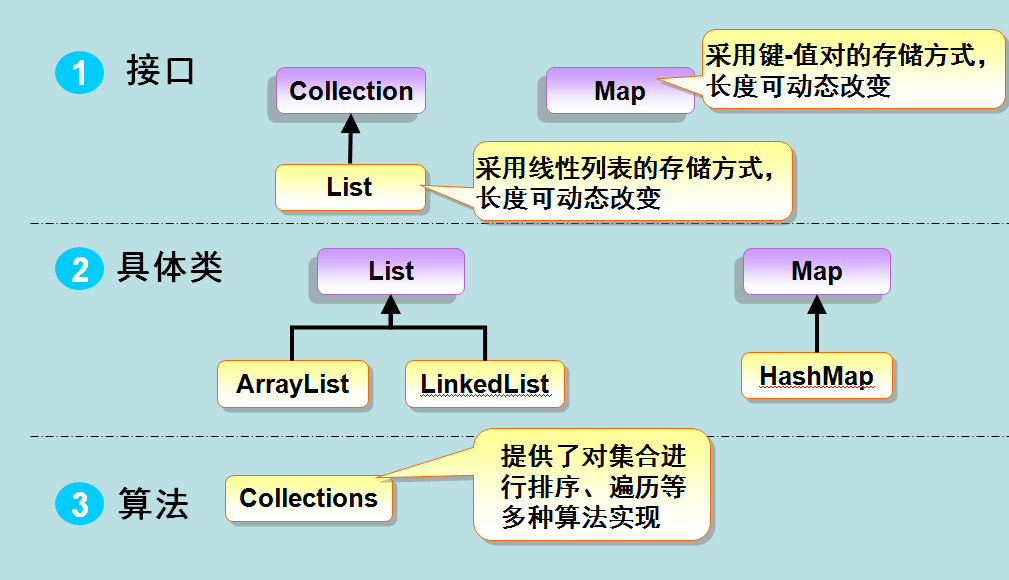
Note: Map s are not subclasses of collections, but they are fully integrated into collections!
List
The List interface inherits from the Collection interface and defines an ordered set that allows duplicates. This interface not only can process part of the list, but also adds location-oriented operations.
Generally speaking, we use ArrayList and LinkedList to implement lists in single thread, while multithreading uses Vector or Collections.sychronizedList to decorate a collection.
The three explanations are as follows:
- ArrayList: Internally implemented through arrays, it allows quick random access to elements. When inserting or deleting elements from the middle of an ArrayList, the array needs to be copied, moved, and expensive. Therefore, it is suitable for random search and traversal, not for insertion and deletion.
- LinkedList: LinkedList is a linked list structure for storing data. It is very suitable for dynamic insertion and deletion of data. Random access and traversal speed is relatively slow. In addition, he provides methods that are not defined in the List interface for manipulating table header and tail elements, which can be used as stacks, queues, and bidirectional queues.
- Vector: It's implemented through arrays, but it supports thread synchronization. Access speed ArrayList is slow.
Their uses are as follows:
List list1 = new ArrayList(); List list2 = new LinkedList(); List list3 = new Vector(); List list4=Collections.synchronizedList(new ArrayList())
After understanding their usage, let's see why ArrayList is faster to query than LinkedList, and LinkedList is faster to add and delete than ArrayList.
The following code is also used here to illustrate, and Vector is also compared by the way.
Code example:
private final static int count=50000;
private static ArrayList arrayList = new ArrayList<>();
private static LinkedList linkedList = new LinkedList<>();
private static Vector vector = new Vector<>();
public static void main(String[] args) {
insertList(arrayList);
insertList(linkedList);
insertList(vector);
System.out.println("--------------------");
readList(arrayList);
readList(linkedList);
readList(vector);
System.out.println("--------------------");
delList(arrayList);
delList(linkedList);
delList(vector);
}
private static void insertList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i=0;i<count;i++){
list.add(0, o);
}
System.out.println(getName(list)+"insert"+count+"Bar data, time-consuming:"+(System.currentTimeMillis()-start)+"ms");
}
private static void readList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i = 0 ; i < count ; i++){
list.get(i);
}
System.out.println(getName(list)+"query"+count+"Bar data, time-consuming:"+(System.currentTimeMillis()-start)+"ms");
}
private static void delList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i = 0 ; i < count ; i++){
list.remove(0);
}
System.out.println(getName(list)+"delete"+count+"Bar data, time-consuming:"+(System.currentTimeMillis()-start)+"ms");
}
private static String getName(List list) {
String name = "";
if(list instanceof ArrayList){
name = "ArrayList";
}
else if(list instanceof LinkedList){
name = "LinkedList";
}
else if(list instanceof Vector){
name = "Vector";
}
return name;
} Output results:
ArrayList inserts 50,000 pieces of data, taking 281 MS
LinkedList inserts 50,000 pieces of data, time-consuming: 2ms
Vector inserts 50,000 pieces of data, time-consuming: 274 MS
--------------------
ArrayList queries 50,000 pieces of data, time-consuming: 1ms
LinkedList queries 50000 pieces of data, time-consuming: 1060ms
Vector queries 50,000 pieces of data, time-consuming: 2ms
--------------------
ArrayList deletes 50,000 pieces of data, time-consuming: 143 MS
LinkedList deletes 50,000 pieces of data, time-consuming: 1ms
Vector deletes 50,000 data, time-consuming: 137 MSFrom the above results, we can clearly see the difference between ArrayList and LinkedList in the performance of adding, deleting and querying.
In collections, we are generally used to store data. Sometimes, however, when there are multiple sets, we want to combine, intersect, difference and union these sets. In List, these methods are already encapsulated, so we don't need to write the corresponding code to use them directly.
The code example is as follows:
/**
* Collection
* @param ls1
* @param ls2
* @return
*/
private static List<String> addAll(List<String> ls1,List<String>ls2){
ls1.addAll(ls2);
return ls1;
}
/**
* Intersection (retainAll deletes elements that ls1 does not have in ls2)
* @param ls1
* @param ls2
* @return
*/
private static List<String> retainAll(List<String> ls1,List<String>ls2){
ls1.retainAll(ls2);
return ls1;
}
/**
* Difference sets (delete elements in ls2 that do not exist in ls1)
* @param ls1
* @param ls2
* @return
*/
private static List<String> removeAll(List<String> ls1,List<String>ls2){
ls1.removeAll(ls2);
return ls1;
}
/**
* Union without duplication (union of ls1 and ls2, without duplication)
* @param ls1
* @param ls2
* @return
*/
private static List<String> andAll(List<String> ls1,List<String>ls2){
//Delete elements that appear in ls1
ls2.removeAll(ls1);
//Add the remaining ls2 elements to ls1
ls1.addAll(ls2);
return ls1;
}Of course, traversal of lists is often used.
List array traversal has three main methods: ordinary for loop, enhanced for loop (after jdk1.5), and Iterator (iterator).
Code example:
List<String> list=new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
for(int i=0;i<list.size();i++){
System.out.println(list.get(i));
}
for (String str : list) {
System.out.println(str);
}
Iterator<String> iterator=list.iterator();
while(iterator.hasNext())
{
System.out.println(iterator.next());
}Explanation: There is little difference between the ordinary for loop and the enhanced for loop. The main difference is that the subscript of the set can be obtained by the ordinary for loop, but not by the enhanced for loop. However, the enhanced for loop writing method is recommended if you do not need to get subscripts for specific sets. As for Iterator (iterator), it is also impossible to obtain data subscripts, but this method does not need to worry about changing the length of the set during traversal. That is to say, add and delete collections while traversing.
This is also true for set operations.
Do not remove / add elements in the foreach loop. Use the Iterator mode for remove elements. If you operate concurrently, you need to lock the Iterator object.
So why not use the foreach loop to remove / add elements?
Here we can do a simple verification.
Code example:
List<String> list = new ArrayList<String>();
list.add("1");
list.add("2");
System.out.println("list Before traversing:"+list);
for (String item : list) {
if ("2".equals(item)) {
list.remove(item);
//If break is not applied here, it will be directly wrong.
break;
}
}
System.out.println("list After traversing:"+list);
List<String> list1 = new ArrayList<String>();
list1.add("1");
list1.add("2");
System.out.println("list1 Before traversing:"+list1);
Iterator<String> iterator = list1.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
if ("2".equals(item)) {
iterator.remove();
}
}
System.out.println("list1 After traversing:"+list1);Output results:
Before list traversal: [1, 2]
After list traversal: [1]
Before traversing list1: [1, 2]
After traversing list1: [1]Note: In the above code, break is added when traversing the list for loop.
In the examples above, we all print the data we want correctly, but in the foreach loop, I added break to it. If no break is added, the Concurrent ModificationException exception will be thrown directly!
Map
The Map interface is not an inheritance of the Collection interface. Map provides key to value mapping. A Map cannot contain the same key, each key can only map to a value. The Map interface provides a view of three sets, the content of which can be treated as a set of keys, a set of values, or a set of key-value mappings.
Map interface is mainly implemented by HashMap, TreeMap, LinkedHashMap, Hashtable and Concurrent HashMap classes.
Their explanations are as follows:
- HashMap: The key of HashMap is obtained according to HashCode, so the corresponding value can be obtained quickly according to the key. However, its key object is not repeatable. It allows keys to be Null, but at most only one record, but it allows multiple records to be Null. Because HashMap is non-thread-safe, it is highly efficient.
- TreeMap: Records saved can be sorted by keys. By default, the ascending order of keys (natural order) is used. You can also specify a sorted comparator, and when traversing a TreeMap with an Iterator, the resulting records are sorted. It also does not allow keys to be null and is not thread-safe.
- LinkedHashMap:LinkedHashMap is basically the same as HashMap. However, the difference between LinkedHashMap and LinkedHashMap is that it maintains a double linked list in which data can be read out in the order in which it is written. You can think of LinkedHashMap as HashMap+LinkedList. That is, it uses both HashMap to manipulate data structures and LinkedList to maintain the sequence of inserted elements. It's not thread-safe either.
- Hashtable:Hashtable is a thread-safe version of HashMap, similar to HashMap. However, it is not allowed to record keys or null values. Because it supports thread synchronization and is thread-safe, Hashtale is also inefficient.
- Concurrent HashMap: Concurrent HashMap was introduced in Java 1.5 as an alternative to Hashtable. Using lock segmentation technology to ensure thread safety can be seen as an upgraded version of Hashtable.
In our work, the Map we use most should be HashMap. Sometimes, however, when using Maps, you need to sort in natural order. Here we can use TreeMap without having to implement it ourselves. The use of TreeMap is similar to HashMap. Note, however, that TreeMap does not allow key s to be null. Here is a brief introduction to the use of TreeMap.
Code example:
Map<String,Object> hashMap=new HashMap<String,Object>();
hashMap.put("a", 1);
hashMap.put("c", 3);
hashMap.put("b", 2);
System.out.println("HashMap:"+hashMap);
Map<String,Object> treeMap=new TreeMap<String,Object>();
treeMap.put("a", 1);
treeMap.put("c", 3);
treeMap.put("b", 2);
System.out.println("TreeMap:"+treeMap);Output results:
HashMap:{b=2, c=3, a=1}
TreeMap:{a=1, b=2, c=3}As can be seen from the above, HashMap is disordered and TreeMap is ordered.
Maps are also traversed when using them. There are three general ways to traverse Map key s and value s:
The first is traversal through Map.keySet.
The second is iterator traversal through Map.entrySet.
The third is traversal through Map.entrySet.
Use as follows:
Map<String, String> map = new HashMap<String, String>();
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}If you only want to get the value in Map, you can use foreach to traverse Map.values().
for (String v : map.values()) {
System.out.println("value= " + v);
}In the above traversal, the first Map.keySet is the one we use most, because it's easy to write. However, when the capacity is large, recommend the use of the third one, the efficiency will be higher! uuuuuuuuuu
Set
Set is a Collection that does not contain duplicate elements, that is, any two elements E1 and E2 have e1.equals(e2)=false, and Set has at most one null element. Because Set is an abstract interface, it is not possible to instantiate a set object directly. Set s = new Set() is incorrect.
Set interface is mainly implemented by HashSet, TreeSet and LinkedHashSet.
They are simply used as follows:
Set hashSet = new HashSet(); Set treeSet = new TreeSet(); Set linkedSet = new LinkedHashSet();
Because Sets cannot have repetitive elements, they are often used to weigh them. For example, if you have two identical data in a list set and want to delete one, you can use the Set mechanism to duplicate it.
Code example:
public static void set(){
List<String> list = new ArrayList<String>();
list.add("Java");
list.add("C");
list.add("C++");
list.add("JavaScript");
list.add("Java");
Set<String> set = new HashSet<String>();
for (int i = 0; i < list.size(); i++) {
String items = list.get(i);
System.out.println("items:"+items);
if (!set.add(items)) {
System.out.println("Repeated data: " + items);
}
}
System.out.println("list:"+list);
}Output results:
items:Java items:C items:C++ items:JavaScript items:Java //Duplicate data: Java list:[Java, C, C++, JavaScript, Java]
Note: If the object is to be de-duplicated, the equals and hashcode methods in the set need to be rewritten.
summary
The summary of List, Map and Set in a collection is as follows:
- List: Lists are similar to arrays and can grow dynamically, automatically increasing the length of lists according to the length of the actual data stored. Finding elements is efficient and inserting and deleting elements is inefficient, because it causes other elements to change their positions.
- ArrayList: Non-thread-safe, suitable for random lookup and traversal, not suitable for insertion and deletion.
- LinkedList: Non-thread-safe, suitable for insertion and deletion, not suitable for search.
Vector: Thread safety. But not recommended.
- Map: A class that maps key s to value s.
- HashMap: Non-thread-safe, keys and values allow null values to exist.
- TreeMap: Non-thread-safe, key traversal in natural or custom order.
- LinkedHashMap: Non-thread-safe, maintains a double-linked list that reads the data in the order in which it is written. Writing is better than HashMap, adding and deleting is worse than HashMap.
- Hashtable: Thread-safe. Keys and values are not allowed to have null values. Not recommended.
Concurrent HashMap: Thread Safety, an upgraded version of Hashtable. Multithreading is recommended.
- Set: No duplicate data is allowed. The retrieval efficiency is low and the deletion and insertion efficiency is high.
- HashSet: Non-thread-safe, disorderly, data can be empty.
- TreeSet: Non-thread-safe, orderly, data can't be empty.
LinkedHashSet: Non-thread-safe, disorderly, data can be empty. Writing is stronger than HashSet, adding and deleting is worse than HashSet.
This is the end of this article. Thank you for reading.
Copyright Statement:
Author: Nothingness
Blog Garden Origin: http://www.cnblogs.com/xuwujing
CSDN origin: http://blog.csdn.net/qazwsxpcm
Personal Blog Origin: http://www.panchengming.com
Originality is not easy, reprint please indicate the source, thank you!