2,MapReduce
2.1. Introduction to MapReduce
The core idea of MapReduce is "divide and conquer", which is suitable for a large number of complex task processing scenarios (large-scale data processing scenarios).
Map is responsible for "dividing", that is, dividing complex tasks into several "simple tasks" for parallel processing. The premise of splitting is that these small tasks can be calculated in parallel and have little dependency on each other.
Reduce is responsible for "closing", that is, summarizing the results of the map phase globally.
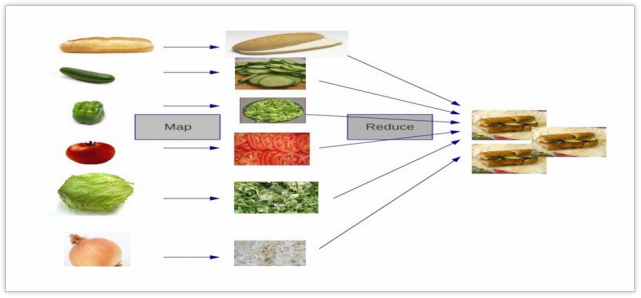
Figure: MapReduce thought model
2.2. Can write Wordcount
- Define a mapper class
//First define the types of four generics
//keyin: LongWritable valuein: Text
//keyout: Text valueout:IntWritable
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//Life cycle of map method: the framework is called every time it passes a row of data
//key: the offset of the starting point of this line in the file
//value: the content of this line
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//Get a row of data and convert it into string
String line = value.toString();
//Cut this line out the words
String[] words = line.split(" ");
//Traverse the array and output < word, 1 >
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
- Define a reducer class
//Life cycle: the reduce method is called once every kv group passed in by the framework
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//Define a counter
int count = 0;
//Traverse all v of this set of kv and add it to count
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
- Define a main class to describe a job and submit it
public class WordCountRunner {
//Describe the information related to business logic (which is mapper, which is reducer, where is the data to be processed, where is the output result...) as a job object
//Submit the described job to the cluster to run
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
//Specify the jar package where this job is located
// wcjob.setJar("/home/hadoop/wordcount.jar");
wcjob.setJarByClass(WordCountRunner.class);
wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
//Set the data types of the output key and value of our business logic Mapper class
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//Set the data types of the output key and value of our business logic Reducer class
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class);
//Specify the location of the data to process
FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt");
//Specifies the location where the results after processing are saved
FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/"));
//Submit this job to the yarn cluster
boolean res = wcjob.waitForCompletion(true);
System.exit(res?0:1);
}
2.3,Combiner
Each map may produce a large number of local outputs. The function of Combiner is to merge the outputs at the map end first, so as to reduce the amount of data transmission between the map and reduce nodes and improve the network IO performance.
For example, for the wordcount provided with hadoop, value is a superimposed number,
Therefore, the value of reduce can be superimposed as soon as the map is completed, instead of waiting until all the maps are completed.
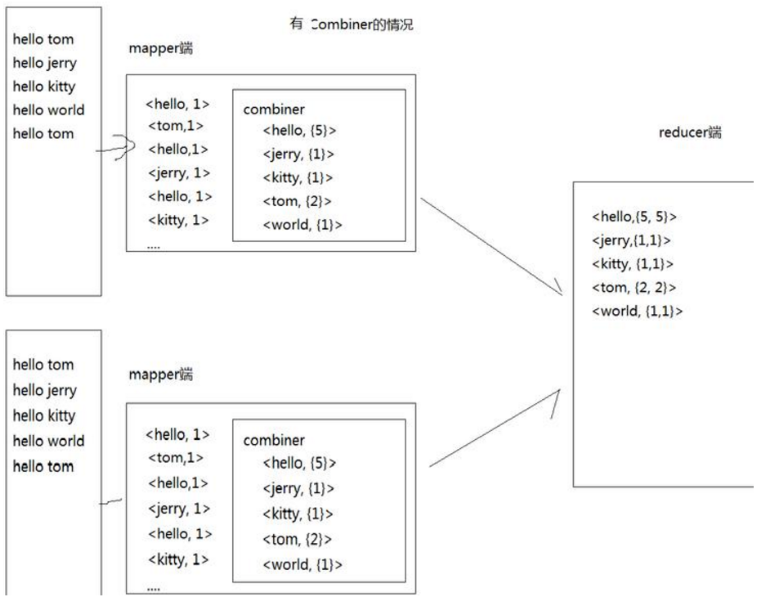
- Specific use
custom Combiner:
public static class MyCombiner extends Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(
Text key, Iterable<LongWritable> values,Context context)throws IOException, InterruptedException {
long count = 0L;
for (LongWritable value : values) {
count += value.get();
}
context.write(key, new LongWritable(count));
};
}
- Add in main class
Combiner set up
// Set Map protocol Combiner
job.setCombinerClass(MyCombiner.class);
See after execution map Output and combine The input statistics are consistent, while combine Output and reduce The input statistics are the same.
2.4,partitioner
During MapReduce calculation, sometimes the final output data needs to be divided into different files. For example, if it is divided according to provinces, the data of the same province needs to be put into one file; According to gender, the data of the same gender need to be put into one file. The class responsible for partitioning data is called Partitioner.
- The source code of HashPartitioner is as follows
package org.apache.hadoop.mapreduce.lib.partition;
import org.apache.hadoop.mapreduce.Partitioner;
/** Partition keys by their {@link Object#hashCode()}. */
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
//By default, the hash value of key and the maximum value of int on are used to avoid data overflow
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
- key and value respectively refer to the output of Mapper task. numReduceTasks refers to the set number of Reducer tasks. The default value is 1. Then the remainder of any integer divided by 1 must be 0. That is, the return value of the getPartition(...) method is always 0. That is, the output of Mapper task is always sent to a Reducer task, and can only be output to one file in the end.
Specific implementation:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class FivePartitioner extends Partitioner<IntWritable, IntWritable>{
/**
* Our demand: partition according to whether it can be divided by 5
*
* 1,If the remainder of dividing by 5 is 0, put it in partition 0
* 2,If the remainder of dividing by 5 is not 0, put it in the 1 partition
*/
@Override
public int getPartition(IntWritable key, IntWritable value, int numPartitions) {
int intValue = key.get();
if(intValue % 5 == 0){
return 0;
}else{
return 1;
}
}
}
- Add the following two lines of code to the main function:
job.setPartitionerClass(FivePartitioner.class); job.setNumReduceTasks(2);//Set to 2
2.5 execution process of MapReduce
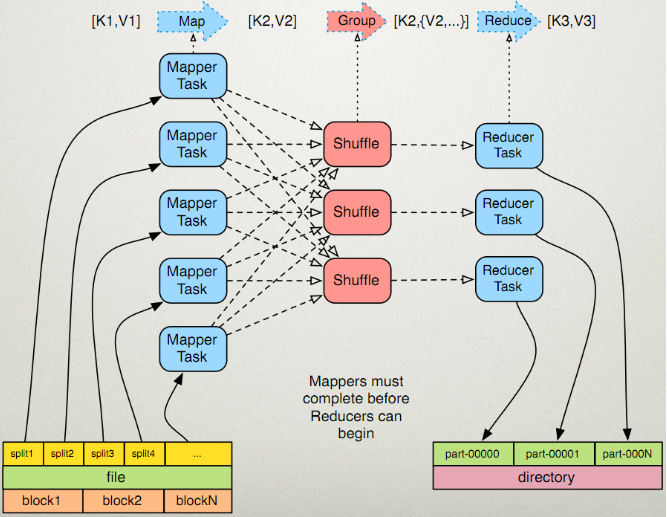
-
Detailed process
-
Map phase
-
l the first stage is to logically slice the files in the input directory one by one according to certain standards to form a slice planning. By default, Split size = Block size. Each slice is processed by a MapTask. (getSplits)
l the second stage is to parse the data in the slice into < key, value > pairs according to certain rules. The default rule is to parse each line of text content into key value pairs. Key is the starting position of each line (in bytes), and value is the text content of the line. (TextInputFormat)
l the third stage is to call the map method in the Mapper class. For each < K, V > parsed in the previous stage, the map method is called once. Zero or more key value pairs are output each time the map method is called.
l the fourth stage is to partition the key value pairs output in the third stage according to certain rules. By default, there is only one zone. The number of partitions is the number of Reducer tasks running. By default, there is only one Reducer task.
l the fifth stage is to sort the key value pairs in each partition. First, sort by key. For key value pairs with the same key, sort by value. For example, for three key value pairs < 2,2 >, < 1,3 >, < 2,1 >, the key and value are integers respectively. Then the sorted results are < 1,3 >, < 2,1 >, < 2,2 >. If there is a sixth stage, enter the sixth stage; If not, output directly to a file.
l the sixth stage is the local aggregation processing of data, that is, combiner processing. Key value pairs with equal keys call the reduce method once. After this stage, the amount of data will be reduced. It is not available by default at this stage.
-
-
reduce phase
-
l in the first stage, the Reducer task will actively copy its output key value pairs from the Mapper task. There may be many Mapper tasks, so Reducer will copy the output of multiple mappers.
l the second stage is to merge all the local data copied to Reducer, that is, merge the scattered data into one large data. Then sort the merged data.
l the third stage is to call the reduce method for the sorted key value pairs. The reduce method is called once for key value pairs with equal keys, and each call will produce zero or more key value pairs. Finally, these output key value pairs are written to the HDFS file.
-
2.6 shuffle phase of MapReduce
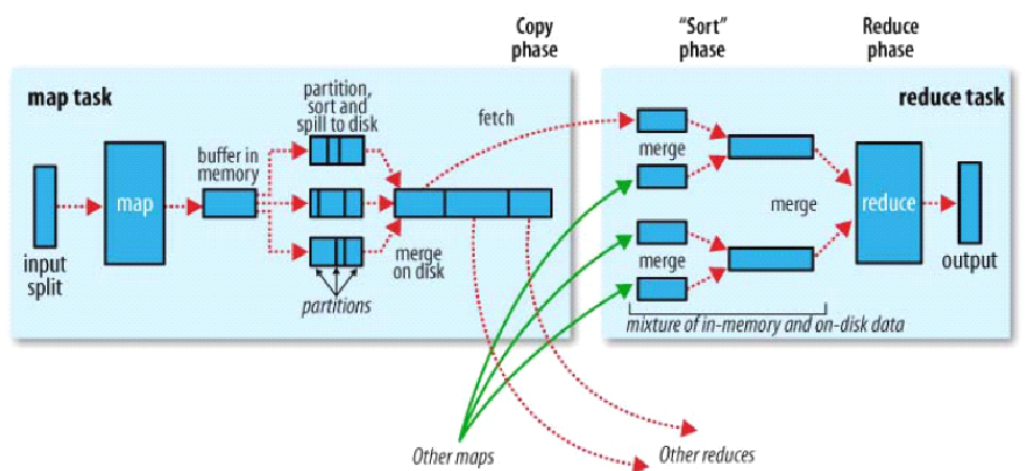
-
shuffle is called the heart of MapReduce and is the core of MapReduce.
-
As can be seen from the above figure, each data slice is processed by a Mapper process, that is, Mapper is only a part of the processing file.
-
Each Mapper process has a ring memory buffer to store the output data of the map. The default size of the memory buffer is 100MB. When the data reaches the threshold of 0.8, that is, 80MB, a background program will overflow the data to the disk. In the process of overflowing data to disk, it needs to go through a complex process. First, the data should be sorted by partition (according to partition number, such as 0, 1, 2). After partition, in order to avoid memory overflow of map output data, the map output data can be divided into small files and then partitioned, In this way, the output data of the map will be divided into sorted data of partitions with multiple small files. Then merge the partition data of each small file into a large file (merge those with the same partition number in each small file).
-
At this time, reducer starts three, which are 0, 1 and 2 respectively. Reducer 0 will get the data of partition 0; Reducer 1 will obtain the data of partition 1; Reducer 2 will get the data of partition 2.
2.7 MapReduce optimization
2.7.1 resource related parameters
//The following parameters are configured in the user's own MapReduce application to take effect
(1) mapreduce.map.memory.mb: the maximum memory available for a Map Task (unit: MB). The default is 1024. If the amount of resources actually used by the Map Task exceeds this value, it will be forcibly killed.
(2) mapreduce.reduce.memory.mb: the maximum number of resources that can be used by a Reduce Task (unit: MB). The default is 1024. If the amount of resources actually used by the Reduce Task exceeds this value, it will be forcibly killed.
(3) mapreduce.map.cpu.vcores: the maximum number of CPU cores available for each Maptask. Default: 1
(4) mapreduce.reduce.cpu.vcores: the maximum number of CPU cores available per Reducetask. Default: 1
(5) Mapreduce.map.java.opts: JVM parameter of map task. You can configure the default java heap here
size and other parameters, for example: "- xmx1024m - verbose: GC - xloggc: / tmp"/@ taskid@.gc ”
(@ taskid @ will be automatically changed to the corresponding taskid by the Hadoop framework). The default value is: ""
(6) Mapreduce.reduce.java.opts: JVM parameter of reduce task. You can configure default Java here
Parameters such as heap size, for example: "- xmx1024m - verbose: GC - xloggc: / tmp"/@ taskid@.gc ”, default: ''
//It should be configured in the server's configuration file before yarn starts to take effect
(1) Yarn.scheduler.minimum-allocation-mb the minimum configuration requested by each container in RM, in MB. The default is 1024.
(2) Yarn.scheduler.maximum-allocation-mb the maximum allocation requested by each container in RM, in MB. The default is 8192.
(3) yarn.scheduler.minimum-allocation-vcores 1
(4)yarn.scheduler.maximum-allocation-vcores 32
(5) yarn.nodemanager.resource.memory-mb indicates the total amount of physical memory available to YARN on the node. The default is 8192 (MB). Note that if your node's memory resources are less than 8GB, you need to reduce this value, and YARN will not intelligently detect the total amount of physical memory of the node.
//The key parameters of shuffle performance optimization should be configured before yarn starts
(1) Mapreduce.task.io.sort.mb is the ring buffer size of 100 shuffle, which is 100m by default
(2) Mapreduce.map.sort.spin.percent 0.8 threshold of ring buffer overflow, 80% by default
2.7.2 fault tolerance related parameters
(1) mapreduce.map.maxattempts: the maximum number of retries per Map Task. Once the retry parameter exceeds this value, it is considered that the Map Task fails to run. The default value is 4.
(2) mapreduce.reduce.maxattempts: the maximum number of retries per Reduce Task. Once the retry parameter exceeds this value, it is considered that the Map Task fails to run. The default value is 4.
(3) mapreduce.map.failures.maxpercent: when the failure ratio of failed map tasks exceeds this value, the whole job will fail. The default value is 0. If your application allows to discard some input data, this value is set to a value greater than 0, such as 5, which means that if less than 5% of map tasks fail (if a Map Task is retried more than mapreduce.map.maxattempts, it is considered that the Map Task fails, and its corresponding input data will not produce any results). The whole job is considered successful.
(4) mapreduce.reduce.failures.maxpercent: when the proportion of failed reduce tasks exceeds this value, the whole job fails. The default value is 0
(5) mapreduce.task.timeout: if a task does not enter for a certain period of time, that is, it will not read new data or output data, it is considered that the task is in block state, which may be temporarily stuck or may be stuck forever. In order to prevent the user program from exiting forever, a timeout (unit: ms) is forcibly set , the default is 600000, and a value of 0 disables timeout.
2.7.3 efficiency and stability parameters
(1) Mapreduce.Map.specific: whether to open the speculative execution mechanism for Map tasks. The default is true. If true, multiple instances of some Map tasks can be executed in parallel.
(2) mapreduce.reduce.speculative: whether to open speculative execution mechanism for Reduce Task. The default value is true
(3)mapreduce.input.fileinputformat.split.minsize: FileInputFormat is the minimum slice size when slicing. The default is 1.
(5)mapreduce.input.fileinputformat.split.maxsize: FileInputFormat maximum slice size when slicing
2.8 execution process of mapreduce program on yarn
Hadoop jar xxx.jar
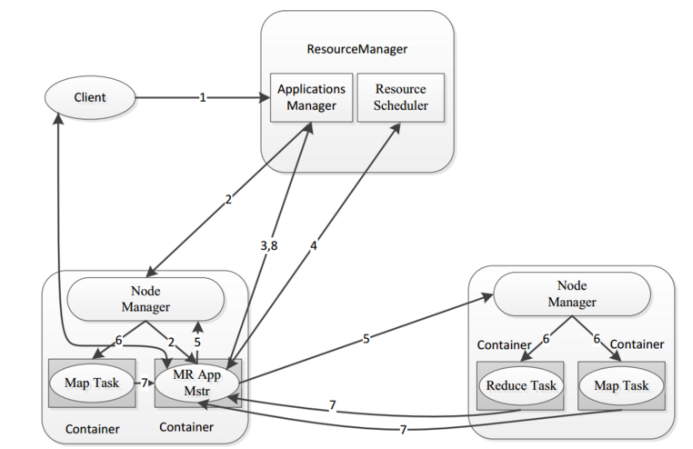
Detailed process:
- 1: The client submits a task to the cluster. The task first goes to the application manager in the resource manager;
- 2: After receiving the task, the application manager will find a NodeManager in the cluster and start an AppMaster process on the DataNode where the NodeManager is located, which is used for task division and task monitoring;
- 3: After the AppMaster is started, it will register its information with the application manager in the resource manager (for communication);
- 4: AppMaster applies to the ResourceScheduler under ResourceManager for the resources required by the calculation task;
- 5: After applying for resources, the AppMaster will communicate with all nodemanagers and ask them to start the tasks required for computing tasks (Map and Reduce);
- 6: Each NodeManager starts the corresponding container to execute Map and Reduce tasks;
- 7: Each task will report its execution progress and execution status to the AppMaster, so that the AppMaster can master the operation status of each task at any time, and restart the execution of a task after it has a problem;
- 8: After the task is executed, the AppMaster reports to the application manager so that the application manager can log off and close itself, so that the resources can be recycled;
2.9 common problems in MapReduce implementation
- The client does not have permission to operate HDFS in the cluster
In the cluster configuration file hdfs-site.xml
property>
<name>dfs.permissions</name>
<value>false</value>
</property>
Then restart
-
The output path of mapreduce already exists. You must delete that path first
-
The cluster operation was submitted and failed
job.setJar("/home/hadoop/wordcount.jar");
-
If the log cannot be typed, a warning message will be reported
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
You need to create a new file named log4j.properties under the src of the project