Problem description
The following error occurred during running WordCount program in Eclipse with plug-ins (instead of manually packing and uploading servers):
DEBUG - LocalFetcher 1 going to fetch: attempt_local938878567_0001_m_000000_0 WARN - job_local938878567_0001 java.lang.Exception: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in localfetcher#1 at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462) at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:529) Caused by: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in localfetcher#1 at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:134) at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:376) at org.apache.hadoop.mapred.LocalJobRunner$Job$ReduceTaskRunnable.run(LocalJobRunner.java:319) at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source) at java.util.concurrent.FutureTask.run(Unknown Source) at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) at java.lang.Thread.run(Unknown Source) Caused by: java.io.FileNotFoundException: G:/tmp/hadoop-Ferdinand%20Wang/mapred/local/localRunner/Ferdinand%20Wang/jobcache/job_local938878567_0001/attempt_local938878567_0001_m_000000_0/output/file.out.index at org.apache.hadoop.fs.RawLocalFileSystem.open(RawLocalFileSystem.java:198) at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:766) at org.apache.hadoop.io.SecureIOUtils.openFSDataInputStream(SecureIOUtils.java:156) at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:70) at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:62) at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:57) at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.copyMapOutput(LocalFetcher.java:124) at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.doCopy(LocalFetcher.java:102) at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.run(LocalFetcher.java:85) DEBUG - LocalFetcher 1 going to fetch: attempt_local938878567_0001_m_000000_0 DEBUG - LocalFetcher 1 going to fetch: attempt_local938878567_0001_m_000000_0
Reason
The final problem is the directory in error reporting. This directory is spliced by Hadoop bottom layer with code:
G:/tmp/hadoop-Ferdinand%20Wang/mapred/local/localRunner/Ferdinand%20Wang/jobcache/job_local938878567_0001/attempt_local938878567_0001_m_000000_0/output/file.out.index
Pay attention to% 20, the root cause is that the user name of the computer contains spaces
So we need to change the user name to solve this problem. Of course, we can also create a new user without spaces
Solve the problem
To modify this USERNAME is not so easy, we can test it in one way.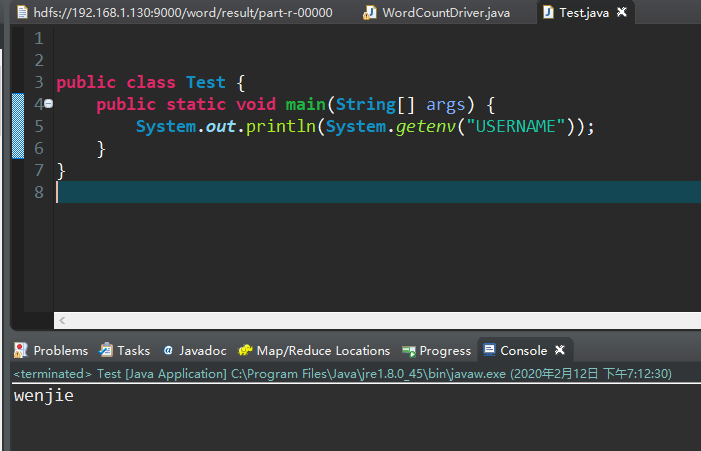
System.getenv("USERNAME") //Java provides a method to obtain environment variables. If the method is correct, the problem will be solved
I found a lot of blogs and found that many people just changed the user name in the control panel, which is bound to be useless
The solution is as follows
1. Click start in the lower right corner - select run, or click win + R on the keyboard to call up run;
2. Enter [netplwiz] and click OK
3. Open the user account and double-click Administrator
4. Enter the name you want to change;
5. Click OK in the lower right corner, a warning will pop up, and click Yes.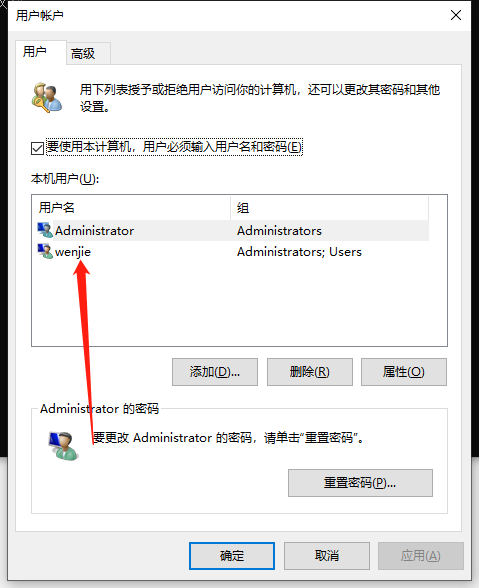
Change the direction indicated by the arrow, and then restart the computer. It's done!
Thinking is more important than coding -- Leslie Lamport

