Python has a very famous HTTP Library - requests Now the author of the requests library has released a new library called requests HTML, which can be guessed from the name. This is a library for parsing HTML (only supports Python 3.6 and above)
https://cncert.github.io/requests-html-doc-cn/#/?id=user_agent

The installation is very simple. You can directly PIP install requests HTML
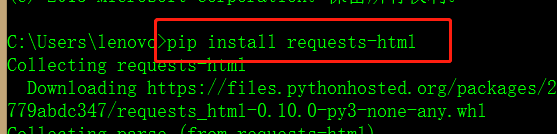
You can check it after you finish.
Basic use
Get web page
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.baidu.com')
print(r.html.html)Get link
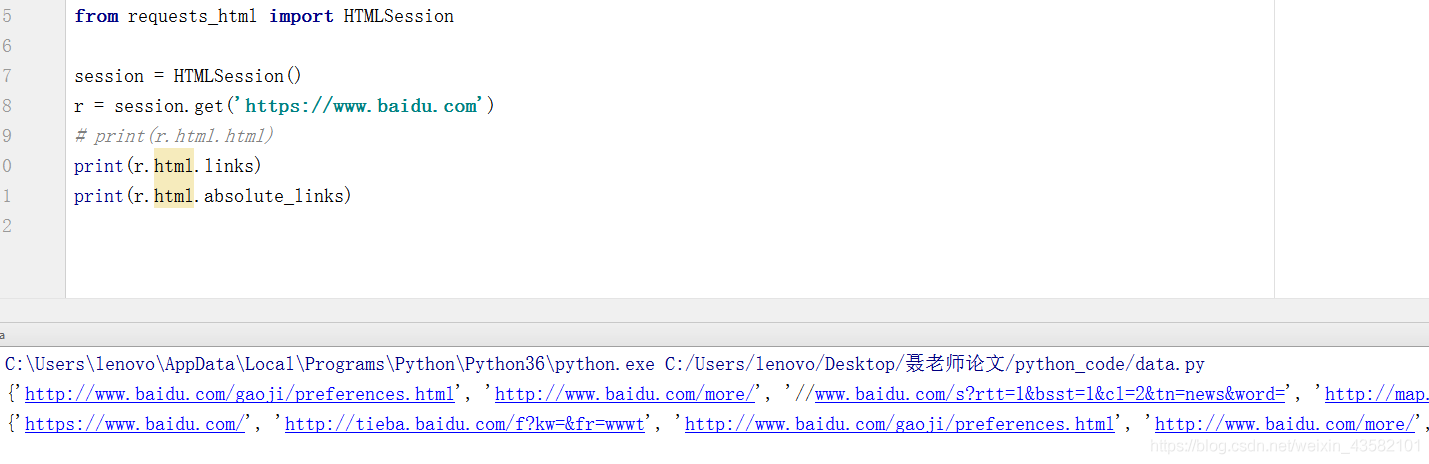
html.html get HTML page html.links, absolute_links get all links and absolute links in HTML
Let's do a test. Take the embarrassing encyclopedia as an example.
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.qiushibaike.com/text/')Get element
Request HTML supports CSS selector and XPATH syntax to select HTML elements.
First, let's take a look at the CSS selector syntax. It needs to use the find function of HTML, which has five parameters and functions as follows:
- Selector, the CSS selector to be used;
- clean, Boolean value. If true, the impact of style and script tags in HTML will be ignored (originally sanitize, probably so understood);
- Containing: if this attribute is set, the label containing the attribute text will be returned;
- First, Boolean value. If true, the first element will be returned; otherwise, the list of elements meeting the conditions will be returned;
- _ Encoding, encoding format.
Here are some simple examples:
print(r.html.find('div#menu', first=True).text)
# Home menu element
print(r.html.find('div#menu a'))
# Paragraph content
print(list(map(lambda x: x.text, r.html.find('div.content span'))))The results are as follows:

Then comes the XPath syntax, which requires the support of another function XPath, which has four parameters as follows:
- Selector, the XPATH selector to be used;
- clean, Boolean value. If true, the impact of style and script tags in HTML will be ignored (originally sanitize, probably so understood);
- First, Boolean value. If true, the first element will be returned; otherwise, the list of elements meeting the conditions will be returned;
- _ Encoding, encoding format.
Similar to the above:
print(r.html.xpath("//div[@id='menu']", first=True).text)
print(r.html.xpath("//div[@id='menu']/a"))
print(r.html.xpath("//div[@class='content']/span/text()"))
Element content The HTML code of the LOGO on the homepage of the embarrassing encyclopedia is as follows:
Embarrassing Encyclopedia
Let's select this element and output it with text:
e = r.html.find("div#hd_logo", first=True)
print(e.text)
To get the attribute of an element, use the attrib attribute:
print(e.attrs)
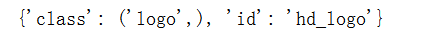
To get the html of an element, use the html attribute:
print(e.html)

Advanced usage
JavaScript support (one of the highlights!)
Some websites are rendered using JavaScript. The results crawled by such websites are only a pile of JS code. Requests HTML of such websites can also be processed. The key step is to call the render function in the HTML results. It will download a chromium in the user directory (the default is ~ /. Pyppeter /), and then use it to execute JS code. The download process is only performed for the first time, and you can directly use chromium to perform it later

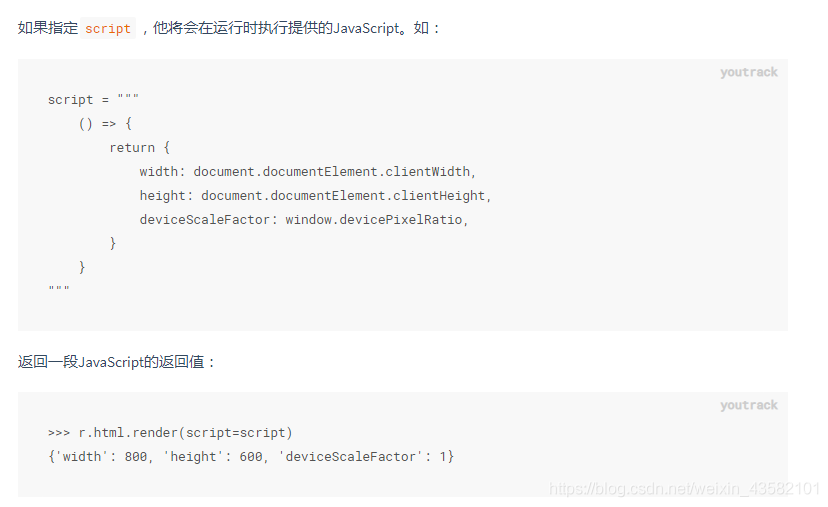
such as: (given script)
Use HTML directly and render JS code directly
All the above descriptions are about requesting HTML content through the network. In fact, requests HTML can be used directly. You only need to construct HTML objects directly:
from requests_html import HTML doc = """""" html = HTML(html=doc) print(html.links)

Directly rendering JS code can also:
script =
"""
() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}
"""
val = html.render(script=script, reload=False)
print(val)Custom request
The above is a simple get method to obtain the request. If you need to log in and other complex processes, you can't use the get method. The HTMLSession class contains rich methods that can help us complete the requirements. These methods are described below.
Custom user agent Some websites will use UA to identify the client type, and sometimes it is necessary to forge UA to realize some operations. If you view the document, you will find that many request methods on the HTMLSession have an additional parameter * * kwargs, which is used to pass additional parameters to the underlying request. We first send a request to the website to see the returned website information.
import json
from pprint import pprint
r = session.get('http://httpbin.org/get')
pprint(json.loads(r.html.html))Both print () and pprint () are python's printing modules with basically the same functions. The only difference is that the data structure printed by pprint () module is more complete. Each line has a data structure, which is more convenient to read the print output results. Especially for very long data printing, the output results of print() are all in one line, which is inconvenient to view, while pprint() uses branch printing. Therefore, pprint() is suitable for data with complex data structure and long data length. Of course, print () is generally used.
You can see that the UA is the one that comes with requests HTML. Let's change it to another one:
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0'
r = session.get('http://httpbin.org/get', headers={'user-agent': ua})
pprint(json.loads(r.html.html))Simulate form login
HTMLSession comes with a complete set of HTTP methods, including get, post, delete, etc., corresponding to each method in http. For example, let's simulate form login:
r = session.post('http://httpbin.org/post', data={'username': 'yitian', 'passwd': 123456})
pprint(json.loads(r.html.html))The results are as follows. You can see that the submitted form values are indeed received in forms:
{'args': {},
'data': '',
'files': {},
'form': {'passwd': '123456', 'username': 'yitian'},
'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'close',
'Content-Length': '29',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'httpbin.org',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) '
'AppleWebKit/603.3.8 (KHTML, like Gecko) '
'Version/10.1.2 Safari/603.3.8'},
'json': None,
'origin': '110.18.237.233',
'url': 'http://httpbin.org/post'}If there is a need to upload files, the practice is similar. If you know about the requests library, you may be familiar with the practice here. This is actually the use of requests. Requests HTML exposes the * * kwargs method so that we can customize the request and pass additional parameters directly to the underlying requests method. So if you have any questions, just go directly to the requests document.
Reptile example After writing the article, I feel a little empty, so I added a few small examples. I have to say that requests html is very cool to use. For some small crawler examples, it feels a little overqualified with scratch, and it feels a little wordy with requests and beautiful soup. The emergence of requests HTML just makes up for this gap. Let's learn about this library. There are still many benefits.
Crawl simple book user articles
The article list of the simple book user page is a typical example of asynchronous loading. It can be easily done with requests HTML, as shown below, with only 5 lines of code.
r = session.get('https://www.jianshu.com/u/7753478e1554')
r.html.render(scrolldown=50, sleep=.2)
titles = r.html.find('a.title')
for i, title in enumerate(titles):
print(f'{i+1} [{title.text}](https://www.jianshu.com{title.attrs["href"]})')Of course, this example has some shortcomings, that is, the generality is slightly poor, because there is no paging mechanism in the article list, and the page needs to be pulled down all the time. Considering the different number of articles of different users, you need to obtain the total number of articles of users first, and then calculate how many times the page should be dropped, so as to achieve better results.