Today we practice crawling a website and summarize the crawling template of similar websites.
Let's take a website like http://www.simm.cas.cn/xwzx/kydt/ as an example. The goal is to crawl the title, release time, article links, picture links, and source of the news.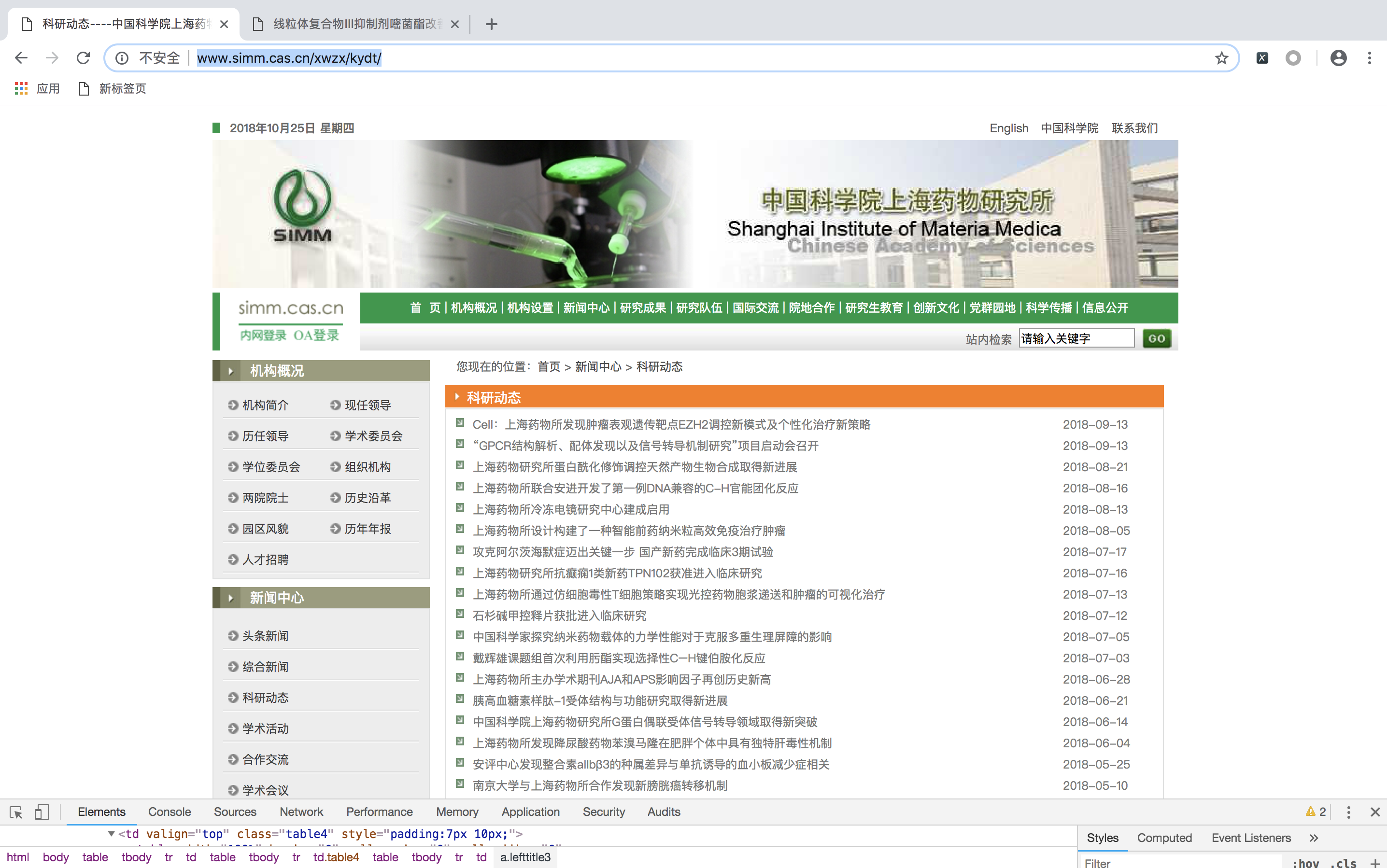
We mainly use requests, re, Beautiful Soup, JSON modules.
Go directly to the code, where there are errors or can be changed, I hope you can criticize and correct.
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import requests
import re
from bs4 import BeautifulSoup
import json
baseurl = "http://www.simm.cas.cn/xwzx/kydt/"
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"}
def reptile_news(url):
book = {}
html = requests.get(url,headers = headers)
soup = BeautifulSoup(html.content,"lxml")
book["title"] = soup.find("td",class_="newtitle").text #Get the text title
html = str(soup.find_all("td",class_ = "hui12_sj2"))
book["time"] = re.search("Date of publication:</td>, <td[^>]+>(.*)</td>",html).group(1) #Get new time
content_items = soup.find("div",class_ = "TRS_Editor").find_all("font")#Getting Text Information from news
content = ""
for i in content_items:
content = content + re.sub("<[^>]+>","",str(i)) + "<br><br>"
book["content"] = "".join(content.split())
img_url = baseurl + url.split("/")[-2] #Get links to news pictures
try:
img = img_url + soup.find("div",class_ = "TRS_Editor").img["src"][1:]
except:
img = "NULL"
book["img_url"] = img_url
return book
def reptile_list(url):
lists = []
book = {}
html = requests.get(url,headers = headers)
soup = BeautifulSoup(html.content,"lxml")
items = soup.find_all("a",class_ ="lefttitle3")
for i in items:
book["news_url"] = baseurl + i["href"][1:]
book.update(reptile_news(book["news_url"]))
lists.append(book)
print(book)
return lists
if __name__ == "__main__":
limit = 10 #Climb 10 pages of news
lists = []
url = baseurl
for i in range(0,limit):
lists.extend(reptile_list(url)) #Add data
html = requests.get(url,headers = headers)
soup = BeautifulSoup(html.content,"lxml")
html_url = str(soup.find_all("a",class_="h12"))
url = baseurl + re.search("href=([^>]*) id=[^>]+>next page</a>",html_url).group(1)[1:-1]
with open("/Users/caipeng/PycharmProjects/practice/simm_base.json", "w", encoding='utf-8') as f:
json.dump(lists, f, ensure_ascii=False)
Final Preservation Effect