I have written an article to download the novel before, but the speed is worrying, because a lot of time is wasted on the writing of files, so is there any way to optimize it?
Articles Catalogue
Problems in Optimizing
- The article is orderly.
- Reading and writing of a file (generally speaking, other programs are not allowed to access the file when the current file is being read and written)
Solution
The article is orderly.
Queues can be used to perform FIFO operations to ensure orderliness
Reading and writing of a file (generally speaking, other programs are not allowed to access the file when the current file is being read and written)
If we can split the novel into two or more parts (the article is split into two parts in this article), and let the program store different parts in parallel, then we can improve the efficiency of writing files (different processes write different files).
Icon
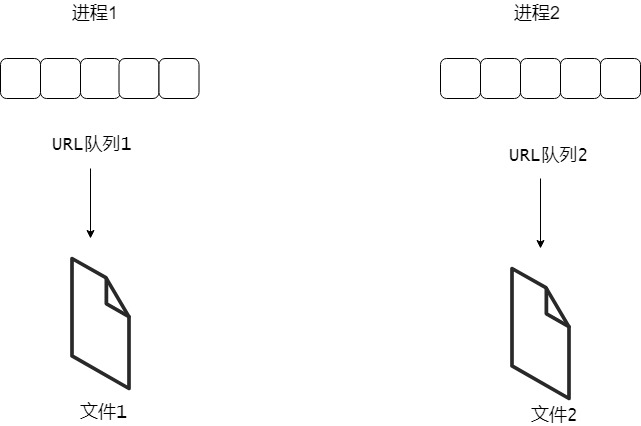
To sum up, it is to create two processes, each thread allocates a URL queue and a file. Threads crawl pages according to the URL queue and store the results in the file.
Establishment of queues
First, we need to get links to all chapters and break them down into two parts.
def add_tasks(dict_queue): original_url = 'http://www.37zw.net/0/761/' original_url_soup = spider(original_url) i = 0 for a in original_url_soup.find(id = "list").find_all('a'): url = original_url + str(a.get('href')) ''' //Put more than 700 chapters into the second queue //Save less than 700 to the second queue ''' if i > 700: dict_queue[2].put(url) else: dict_queue[1].put(url) i += 1 return dict_queue one = multiprocessing.Queue() two = multiprocessing.Queue() dict_queue = {1: one, 2:two} full_queue = add_tasks(dict_queue)
Allocate different queues for different processes
for i in range(1, 3):
'''
full_queue[i] represents different queues
'''
p = multiprocessing.Process(
target=process_tasks, args=(full_queue[i], i))
processes.append(p)
'''
Start the process
'''
p.start()
for p in processes:
'''
Waiting for the process to complete
'''
p.join()
Tasks of the process
Each thread allocates a URL queue and a file, and the thread crawls the page according to the URL queue and stores the results in the file.
def process_tasks(queue, i): ''' //Open different files for different processes ''' f = open('The first{}Part.txt'.format(i), 'w', encoding='utf-8') while not queue.empty(): ''' //Get the URL from the queue ''' url = queue.get() soup = spider(url) ''' //Get chapter names ''' chapter_name = soup.find("div", {"class": "bookname"}).h1.string print(chapter_name) try: f.write('\n' + chapter_name + '\n') except: pass ''' //Getting Chapter Content ''' for each in soup.find(id = "content").strings: try: f.write('%s%s' % (each.replace('\xa0', ''), os.linesep)) except: pass f.close() return True
One or two writing errors will inevitably occur in such frequent file writing operations. My suggestion is that if there are errors, don't care about it. If we do, unfortunately, one of the processes will get stuck. I've tried to write like this.
try: f.write('\n' + chapter_name + '\n') except: f.write("Loss of chapters")
It's a good way to record lost chapters, but don't forget, how do we record them? f.write() Writing is a file operation that may still cause file writing errors
Of course, the best way is not to directly pass out, but to use logs and other records, but for our program to lose a chapter or two completely unaffected, it is difficult not to record the log but to copy and paste it into the file online?
Reptilian self-cultivation
Once I as a ignorant crawler Xiaobai, go up is a shuttle for circulation, do not know that this will bring a great burden to the website, so our crawler program also needs a little rest, in case a website crawls, where to read the novel?
def spider(url): time.sleep(0.01) req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) response = urlopen(req) ''' //Ignore Chinese coding ''' html = response.read().decode('gbk', 'ignore') soup = BeautifulSoup(html, 'html.parser') return soup
Of course, I did not add time.sleep(0.01), but for this example, most of the time is spent writing files, access is basically about 100 times per second, in fact, it is still a bit high.
Complete code
from bs4 import BeautifulSoup from urllib.request import Request, urlopen import os import time import multiprocessing def spider(url): time.sleep(0.01) req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) response = urlopen(req) ''' //Ignore Chinese coding ''' html = response.read().decode('gbk', 'ignore') soup = BeautifulSoup(html, 'html.parser') return soup def add_tasks(dict_queue): original_url = 'http://www.37zw.net/0/761/' original_url_soup = spider(original_url) i = 0 for a in original_url_soup.find(id = "list").find_all('a'): url = original_url + str(a.get('href')) ''' //Put more than 700 chapters into the second queue //Save less than 700 to the second queue ''' if i > 700: dict_queue[2].put(url) else: dict_queue[1].put(url) i += 1 return dict_queue def process_tasks(queue, i): ''' //Open different files for different processes ''' f = open('The first{}Part.txt'.format(i), 'w', encoding='utf-8') while not queue.empty(): ''' //Get the URL from the queue ''' url = queue.get() soup = spider(url) ''' //Get chapter names ''' chapter_name = soup.find("div", {"class": "bookname"}).h1.string print(chapter_name) try: f.write('\n' + chapter_name + '\n') except: pass ''' //Getting Chapter Content ''' for each in soup.find(id = "content").strings: try: f.write('%s%s' % (each.replace('\xa0', ''), os.linesep)) except: pass f.close() return True def run(): one = multiprocessing.Queue() two = multiprocessing.Queue() dict_queue = {1: one, 2:two} full_queue = add_tasks(dict_queue) processes = [] start = time.time() for i in range(1, 3): ''' full_queue[i]Represents different queues ''' p = multiprocessing.Process( target=process_tasks, args=(full_queue[i], i)) processes.append(p) ''' //Start the process ''' p.start() for p in processes: ''' //Waiting for the process to complete ''' p.join() print(f'Time taken = {time.time() - start:.10f}') if __name__ == '__main__': run()
It's only 94 lines of code with comments. Is it easy to write a multi-process crawler?
How to Understand Multiprocess
For this example, I came up with an excellent way to understand it, which is to open two command lines to run two single-process versions of the crawler, and the effect is actually the same as this example.
Running results of this example
You can see that two processes are downloading at the same time.
So let's open two command lines to run the stand-alone version of the crawler, one to let it down the first seven hundred chapters, and the other to let it down the following chapters. Isn't that the same effect as this example? (Just for example, I didn't actually run it.)
Reference material:
Python 3 multiprocessing document