Storage system architecture:
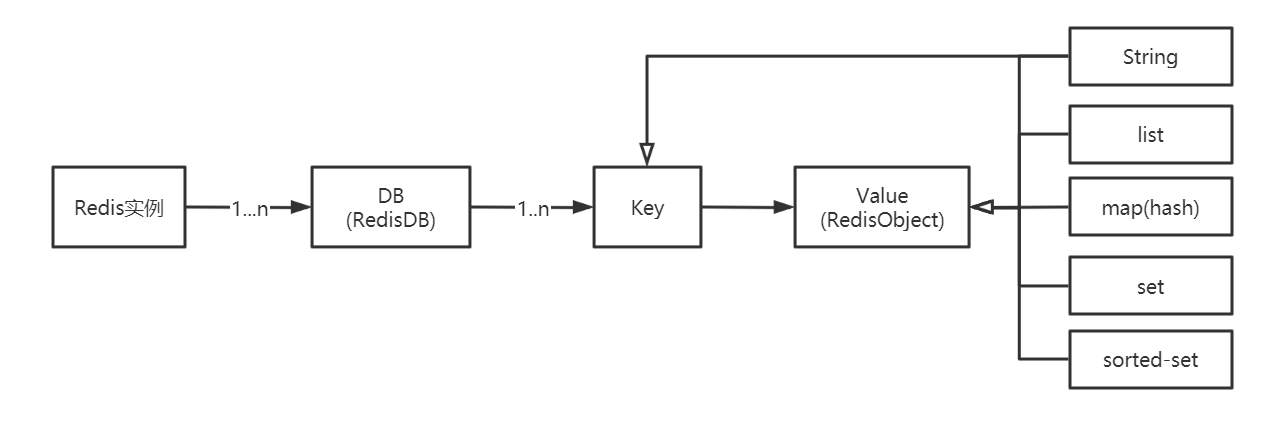
The concept of "database" exists in Redis. This structure is defined by redisDb in redis.h. When the Redis server is initialized, 16 databases will be allocated in advance. All databases are saved to the redisServer.db array, a member of the redisServer structure. In the redisClient, a pointer named DB points to the currently used database.
RedisDB structure
typedef struct redisDb {
int id; //id is the database serial number, 0-15 (Redis has 16 databases by default)
long avg_ttl; //The average ttl (time to live) of stored database objects, which is used for statistics
dict *dict; //Store all key values in the database
dict *expires; //Expiration time of stored key
dict *blocking_keys;//blpop stores blocking key s and client objects
dict *ready_keys;//Post blocking push response the blocking client stores the key and client object of the post blocking push
dict *watched_keys;//Store the key and client object monitored by the watch
} redisDb;id
Database serial number, 0-15 (Redis has 16 databases by default)
dict
Store all key values in the database
expires
Expiration time of stored key
RedisObject structure
Value is an object that contains five common data structures: String object, list object, hash object, collection object and ordered collection object.
typedef struct redisObject {
unsigned type:4;//Type object type
unsigned encoding:4;//code
unsigned lru:LRU_BITS; //LRU_BITS is 24bit, which records the time of the last access by the command program
int refcount;//Reference count
void *ptr;//Pointer to the underlying implementation data structure
}robj;- type
Represents the type of object, accounting for 4 bits; Common redis_ String, REDIS_LIST, redis_ Hash, redis_ Set, redis_ Zset (ordered set).
- encoding
Internal code of the object, accounting for 4 bits; There are at least two codes for each type supported by redis.
Redis can set different codes for objects according to different usage scenarios, which greatly improves the flexibility and efficiency of redis.
- lru
Record the last access time of the object, accounting for 24 bits;
- refcount
Records the number of times the object is referenced. The type is integer; refcount is mainly used for object reference counting and memory recycling.
Redis to save memory, when some objects appear repeatedly, the new program will not create new objects, but still use the original objects. When the refcount of an object is greater than 1, it is called a shared object.
- ptr
Pointer to the underlying data structure
Common types and application scenarios:
- String: cache, counter, distributed lock, etc.
- List: linked list, queue, Weibo followers timeline list, etc.
- Hash: user information, hash table, etc.
- Set: de weight, like, step on, common friends, etc.
- Zset: traffic ranking, hits ranking, etc.
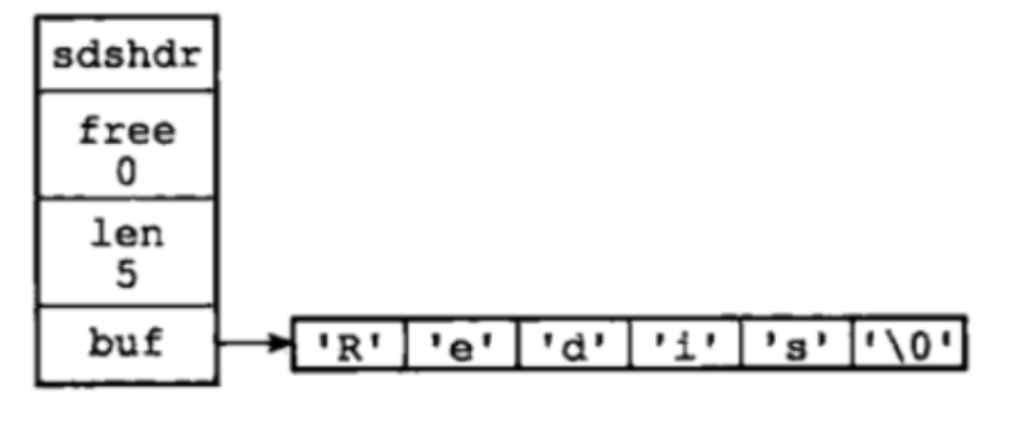
Simple dynamic string SDS
Redis does not directly use the traditional string of C language, but builds a simple dynamic string. The simple dynamic string SDS is variable and follows C. the string ends with a 1-byte null character with a maximum length of 512M.
struct sdshdr{
//Records the number of bytes used in the buf array
int len;
//Records the number of unused bytes in the buf array
int free;
//An array of characters used to hold strings
char buf[];
}
Advantages:
1. Add free and len fields on the basis of C string to obtain the string length: SDS is o(1), C string is o (n),
Length of buf [] = len+free+1;
2. Because SDS records the length, it will automatically reallocate memory when buffer overflow may occur, so as to eliminate buffer overflow.
3. Binary data can be accessed, and the string length len is used as the end identifier
quicklist is an important data structure at the bottom of Redis. Is the underlying implementation of the list( Before Redis3.2, Redis adopted
It is implemented with two-way linked list (adlist) and compressed list (ziplist) After Redis 3.2, Redis is set up by combining the advantages of adlist and ziplist
Calculated the quicklist.
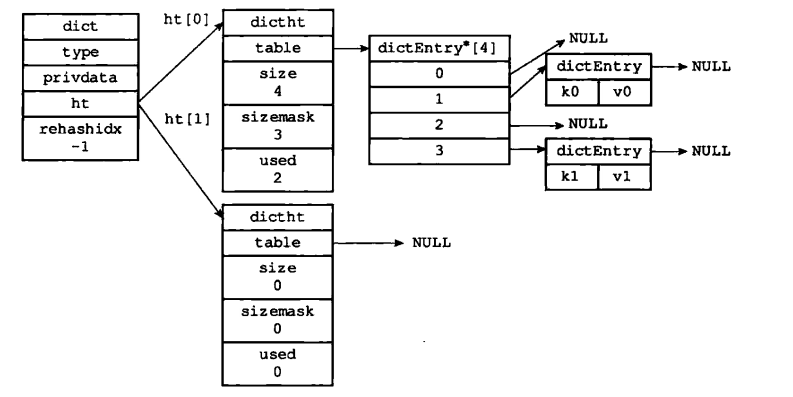
Dictionary dict
Also known as symbol table, associative array or mapping, is an abstract data structure used to store key value pairs.
The entire Redis database is stored in a dictionary (K-V structure). The dictionary uses a hash table as the underlying implementation. A dictionary has two hash tables. There can be multiple hash table nodes in a hash table, and each hash table node stores a key value pair in the dictionary.
Dictionary structure
typedef struct dict {
dictType *type; // The specific operation function corresponding to the dictionary
void *privdata; // Optional parameters corresponding to functions of the above types
dictht ht[2]; /* Two hash tables store key value pair data. ht[0] is the native hash table and ht[1] is the rehash hash table */
long rehashidx; /*rehash When it is equal to - 1, it indicates that there is no rehash, otherwise it indicates that rehash operation is in progress, and the stored value indicates the index value (array subscript) to which rehash of the hash table ht[0] is going*/
int iterators; // Number of iterators currently running
} dict;- The type field points to the dictType structure. Each dictType stores a cluster of functions used to operate key value pairs of a specific type;
- The privdata attribute holds the optional parameters that need to be passed to those type specific functions;
- ht attribute is an array containing two items. Each item in the array is a dictht hash table. ht[1] is only used when rehash the ht[0] hash table;
- The trehashidx attribute is a rehash index. When rehash operation is not performed, the value is - 1.
Hash table structure
typedef struct dictht {
dictEntry **table; // Hash table array
unsigned long size; // Size of hash table array
unsigned long sizemask; // The mask used to map the location. The value is always equal to (size-1)
unsigned long used; // The number of existing nodes in the hash table, including the next single linked list data
} dictht;- Table is an array. Each element in the array is a pointer to the hash table node, and each node stores a key value pair;
- Size records the size of the hash table, that is, the size of the table array;
- The value of sizemask is always equal to size-1. This attribute, together with the hash value, determines that a key should be placed on the index of the table array;
- used records the number of existing nodes in the hash table.
Hash table node
typedef struct dictEntry {
void *key; // key
union { // The value v can be of the following four types
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // Point to the next hash table node to form a one-way linked list to solve hash conflicts
} dictEntry;- The key field stores the key in the key value pair
- The v field is a union that stores the value in the key value pair
- Next points to the next hash table node, which is used to resolve hash conflicts
Diagram
Application scenario
1. K-V data storage of master database
2. Hash object (hash)
3. Master-slave node management in sentinel mode
Jump table
Jump table is the bottom implementation of ordered set, which is efficient and simple to implement.
Basic idea: layer some nodes in the ordered linked list, and each layer is an ordered linked list.