1. Overview of Redis;
Second, application scenario analysis;
3. Redis's data recovery strategy;
Fourth, case: build Redis high-performance database;
I. Overview of Redis:
Overview: redis is a persistent single-process single-threaded key-value type cache system, similar to Memcached, which supports relatively more value types, including string (string), list (list), set (set), zset(sorted set -- ordered set) and hashs (hash type). These data types all support push/pop, add/remove, intersection, Union and difference sets, and richer operations.
Like memcached, data is cached in memory to ensure efficiency. The difference is that redis regularly saves database data flush to the hard disk through asynchronous operations. Because of the pure memory operation, Redis has excellent performance. It can handle more than 100,000 reads and writes per second. It is the fastest known Key-Value DB. On this basis, it realizes master-slave synchronization. At present, Redis has been widely used in China, such as Sina, Taobao, Flickr, Github and so on. Both use Redis's caching service. Official address: https://redis.io/ At present, the development and maintenance of redis project is supported by vmware vendors.
Advantage:
1. Very high performance - Redis can support more than 100K + per second reading and writing frequency.
2. Rich data types - Redis supports Strings, Lists, Hashes, Sets and Ordered Sets data type operations for binary cases.
3. Atomicity - All operations of Redis are atomic (that is, all operations succeed or fail without execution), and Redis also supports atomic execution after several operations are merged.
4.Redis runs in memory but can be persisted to disk, so it is necessary to balance memory when reading and writing different data sets at high speed, because the amount of data can not be larger than hardware memory. Another advantage of in-memory databases is that compared with the same complex data structure on disk, it is very simple to operate in memory, so Redis can do many things with high internal complexity. At the same time, in terms of disk format, they are compact and appended, because they do not need random access.
2. Application scenario analysis:
MySql+Memcached Architecture Problems: Actual MySQL is suitable for mass data storage. Many companies have used this architecture to load hot data into cache and speed up access through Memcached. However, with the increasing volume of business data and the continuous growth of access, we encounter many problems:
1.MySQL needs to constantly disassemble libraries and tables, Memcached also needs to continue to expand, expansion and maintenance work takes up a lot of development time.
2. Data consistency between Memcached and MySQL database.
3.Memcached data hit rate is low or down loader, a large number of access directly penetrates DB, MySQL can not support.
4. Synchronization of cache across computer rooms.
Redis application scenarios: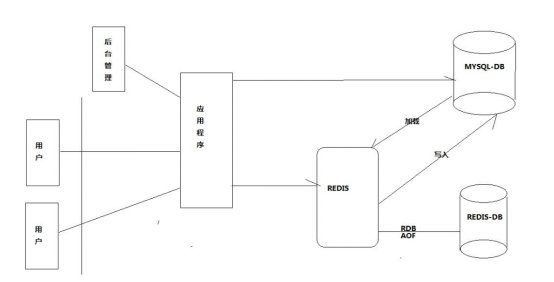
Redis is more like an enhanced version of Memcached, so when to use Memcached and when to use Redis?
1.Redis not only supports simple k/v data, but also provides storage of list, set, zset, hash and other data structures.
2.Redis supports data backup, i.e. master-slave mode.
3.Redis supports data persistence, can keep data in memory on disk, and can be loaded again when restarted for use.
4.Memcached: Reduce the load of database and improve the performance in dynamic system; Cache is suitable for reading more, writing less, and large amount of data (e.g. Renren Web queries user information, friends information, article information, etc.).
Redis: It is suitable for systems that require high efficiency of reading and writing, complex data processing business and high security requirements (such as the counting and publishing system of Sina Weibo, which require high data security and reading and writing requirements).
3. Redis's data recovery strategy:
Redis's recovery strategy:
volatile-lru: Select the least recently used data from the data set (server.db[i].expires) that has set expiration time to eliminate;
volatile-ttl: Select the data that will expire from the data set (server.db[i].expires) that has set expiration time.
volatile-random: Choose data culling arbitrarily from a set of data sets (server.db[i].expires) that have set expiration times;
allkeys-lru: Select the least recently used data from the data set (server.db[i].dict) and eliminate it.
allkeys-random: data elimination by arbitrary selection from a data set (server.db[i].dict);
no-enviction (expulsion): No expulsion of data;
4. Case: Build Redis High Performance Database:

The experimental steps are as follows:
Install and configure Redis services;
Adjust the configuration of Redis services;
Test Redis service with PHP;
String for operation in Redis;
list of operations in Redis;
set of operations in Redis;
zset for operation in Redis;
hash of operation in Redis;
Other operations in Redis;
Install and configure Redis Service;
[root@redis ~]# wget http://download.redis.io/releases/redis-4.0.9.tar.gz
[root@redis ~]# tar zxvf redis-4.0.9.tar.gz
[root@redis ~]# cd redis-4.0.9
[root@redis redis-4.0.9]# make
[root@redis redis-4.0.9]# echo $?
[root@redis redis-4.0.9]# cd
[root@redis ~]# mkdir -p /usr/local/redis
[root@redis ~]# cp /root/redis-4.0.9/src/redis-server /usr/local/redis/ ##Server-side program
[root@redis ~]# cp /root/redis-4.0.9/src/redis-cli /usr/local/redis/ ##Client program
[root@redis ~]# cp /root/redis-4.0.9/redis.conf /usr/local/redis/ ##Master Profile
[root@redis ~]# ls /usr/local/redis/
redis-cli redis.conf redis-server
[root@redis ~]# sed -i '/^bind 127.0.0.1$/s/127.0.0.1/192.168.100.101/g' /usr/local/redis/redis.conf
[root@redis ~]# sed -i '/protected-mode/s/yes/no/g' /usr/local/redis/redis.conf ##Turn off redis protection mode
[root@redis ~]# sed -i '/daemonize/s/no/yes/g' /usr/local/redis/redis.conf ##Open the background daemon mode of redis
[root@redis ~]# sed -i '/requirepass/s/foobared/123123/g' /usr/local/redis/redis.conf ##Set the redis password to 123123
[root@redis ~]# sed -i '/requirepass 123123/s/^#//G'/usr/local/redis/redis.conf # Open redis password
//Attachment: redis.conf Master Profile Detailed
daemonize yes #Running redis in daemon mode
pidfile "/var/run/redis.pid" #Redis runs in the background, default pid file path / var/run/redis.pid
port 6379 #Default port
bind 127.0.0.1 #By default, all ip addresses are bound locally. For security, only intranet ip can be monitored.
timeout 300 #Client timeout settings in seconds
loglevel verbose #Set the log level to support four levels: debug, notice, verbose, warning
logfile stdout #Logging mode, default to standard output, logs do not write files, output to empty device / deb/null
logfile "/usr/local/redis/var/redis.log" #Log file paths can be specified
databases 16 #Number of open databases
save 900 1
save 300 10
save 60 10000
//Create a local database snapshot in the format: save**
900 Within seconds, a snapshot is triggered after a write operation
300 Perform 10 write operations in seconds
60 Perform 10,000 write operations in seconds
rdbcompression yes #Enable database lzf compression, or set to no
dbfilename dump.rdb #Local snapshot database name
dir "/usr/local/redis/var/" #Local snapshot database storage directory
requirepass 123456 #Setting up redis database connection password
maxclients 10000 #Maximum number of client connections at the same time, 0 is unlimited
maxmemory 1024MB #Set redis maximum memory usage, value less than physical memory, must be set
appendonly yes #Open log records, equivalent to MySQL's binlog
appendfilename "appendonly.aof" #Log file name, note: not directory path
appendfsync everysec #Set the frequency of log synchronization, synchronization per second, there are two parameters always, no is generally set to everysec, equivalent to MySQL transaction log writing mode.
Slaveof Setting up a database as a slave database for other databases
Masterauth Password Validation Required for Main Database Connection
vm-enabled Whether to turn on virtual memory support( vm The initial parameters are all configured for virtual memory)
vm-swap-file Setting Exchange File Path for Virtual Memory
vm-max-memory Set up redis Maximum physical memory size used
vm-page-size Setting the page size of virtual memory
vm-pages Setting the total of exchange files page Number
vm-max-threads Settings to use swap The number of threads used to store simultaneous use is usually set to the same number of cores. If set to 0, the number of threads will be serialized, which greatly guarantees the integrity of the data.
Glueoutputbuf Store small output caches together
hash-max-zipmap-entries Set up hash The critical value of
Activerehashing again hash
[root@redis ~]# cat <<END >>/etc/init.d/redis
#!/bin/sh
# chkconfig: 2345 80 90
# description: Start and Stop redis
#PATH=/usr/local/bin:/sbin:/usr/bin:/bin
REDISPORT=6379
EXEC=/usr/local/redis/redis-server
REDIS_CLI=/usr/local/redis/redis-cli
PIDFILE=/var/run/redis_6379.pid
CONF="/usr/local/redis/redis.conf"
AUTH="123123"
LISTEN_IP=\$(netstat -utpln |grep redis-server |awk '{print \$4}'|awk -F':' '{print \$1}')
case "\$1" in
start)
if [ -f \$PIDFILE ]
then
echo "\$PIDFILE exists, process is already running or crashed"
else
echo "Starting Redis server..."
\$EXEC \$CONF
fi
if [ "\$?"="0" ]
then
echo "Redis is running..."
fi
;;
stop)
if [ ! -f \$PIDFILE ]
then
echo "\$PIDFILE does not exist, process is not running"
else
PID=\$(cat \$PIDFILE)
echo "Stopping ..."
\$REDIS_CLI -h \$LISTEN_IP -p \$REDISPORT -a \$AUTH SHUTDOWN
while [ -x \${PIDFILE} ]
do
echo "Waiting for Redis to shutdown ..."
sleep 1
done
echo "Redis stopped"
fi
;;
restart|force-reload)
\${0} stop
\${0} start
;;
*)
echo "Usage: /etc/init.d/redis {start|stop|restart|force-reload}" >&2
exit 1
esac
END
[root@redis ~]# chmod 755 /etc/init.d/redis
[root@redis ~]# chkconfig --add redis
[root@redis ~]# /etc/init.d/redis start
Starting Redis server...
4390:C 04 May 02:16:45.232 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
4390:C 04 May 02:16:45.232 # Redis version=4.0.9, bits=64, commit=00000000, modified=0, pid=4390, just started
4390:C 04 May 02:16:45.232 # Configuration loaded
Redis is running...
[root@redis ~]# netstat -utpln |grep redis
tcp 0 192.168.100.101:6379 0.0.0.0:* LISTEN 4204/redis-server *
adjustment Redis Configuration of services:
[root@redis ~]# cp /root/redis-4.0.9/src/redis-benchmark /usr/local/redis/
[root@redis ~]# cp /root/redis-4.0.9/src/redis-check-rdb /usr/local/redis/
[root@redis ~]# cp /root/redis-4.0.9/src/redis-check-aof /usr/local/redis/
[root@redis ~]# cp /root/redis-4.0.9/src/redis-sentinel /usr/local/redis/
[root@redis ~]# ls /usr/local/redis/
dump.rdb redis-benchmark redis-cli redis.conf redis-server
[root@redis ~]# ln -s /usr/local/redis/redis-cli /usr/bin/redis
[root@redis ~]# redis -h 192.168.100.101 -p 6379 -a 123123
192.168.100.101:6379> set name lwh
OK
192.168.100.101:6379> get name
"lwh"
192.168.100.101:6379> exit
[root@redis ~]# ln -s /usr/local/redis/redis-benchmark /usr/bin/redis-benchmark
[root@redis ~]# redis-benchmark -h 192.168.100.101 -p 6379 -c 1000 -n 10000
Combination PHP test Redis Service;
[root@redis ~]# yum -y install httpd php php-redis php-devel
[root@redis ~]# php -v
PHP 5.4.16 (cli) (built: Mar 7 2018 13:34:47)
Copyright (c) 1997-2013 The PHP Group
Zend Engine v2.4.0, Copyright (c) 1998-2013 Zend Technologies
[root@redis ~]# wget https://codeload.github.com/phpredis/phpredis/tar.gz/4.0.2
[root@redis ~]# tar zxvf phpredis-4.0.2.tar.gz
[root@redis ~]# cd phpredis-4.0.2
[root@redis phpredis-4.0.2]# /usr/bin/phpize
Configuring for:
PHP Api Version: 20100412
Zend Module Api No: 20100525
Zend Extension Api No: 220100525
[root@redis phpredis-4.0.2]# ./configure --with-php-config=/usr/bin/php-config
[root@redis phpredis-4.0.2]# make && make install
[root@redis phpredis-4.0.2]# echo $?
0
[root@redis phpredis-4.0.2]# cd
[root@redis ~]# echo -e "extension_dir = \"/usr/lib64/php/modules/\"\nextension = redis.so" >>/etc/php.ini
[root@redis ~]# systemctl start httpd
[root@redis ~]# netstat -utpln |grep 80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 19008/httpd
[root@redis ~]# cat <<END >>/var/www/html/index.php
<?php
phpinfo();
?>
END
[root@redis ~]# cat <<END >>/var/www/html/test.php
<?php
\$redis = new Redis();
\$redis->connect('192.168.100.101',6379);
\$redis->auth('123123');
\$keys = \$redis->keys("*");
var_dump(\$keys);
?>
END

Redis In operation String -- String (Note: redis Statements in the tab Completion; //Summary: String is a simple key-value pair. Value can be either a String or a number. String is stored in redis by default as a string, which is referenced by redisObject. When encountering incr,decr and other operations, String will be converted to numerical calculation. At this time, the encoding field of redisObject is int. [root@redis ~]# redis -h 192.168.100.101 -p 6379 -a 123123 192.168.100.101:6379> set hello world OK 192.168.100.101:6379> get hello "world" 192.168.100.101:6379> EXISTS hello ##Verify that the key exists (integer) 1 192.168.100.101:6379> type hello string 192.168.100.101:6379> substr hello 1 2 ##Look at the first and second characters of key "or" 192.168.100.101:6379> append hello ! ##Add characters after key! (integer) 6 192.168.100.101:6379> get hello "world!" 192.168.100.101:6379> set haha heihei OK 192.168.100.101:6379> keys h* ##View the Key starting with h 1) "haha" 2) "hello" 192.168.100.101:6379> set name xiaoming OK 192.168.100.101:6379> keys * 1) "haha" 2) "hello" 3) "name" 192.168.100.101:6379> RANDOMKEY ##Random return of a Key "name" 192.168.100.101:6379> keys * 1) "haha" 2) "hello" 3) "name" 192.168.100.101:6379> RANDOMKEY "haha" 192.168.100.101:6379> RENAME haha hehe OK 192.168.100.101:6379> keys * 1) "hehe" 2) "name" 3) "hello" 192.168.100.101:6379> DEL hehe (integer) 1 192.168.100.101:6379> keys * 1) "name" 2) "hello" 192.168.100.101:6379> get name "xiaoming" 192.168.100.101:6379> set name xiaohong OK 192.168.100.101:6379> get name "xiaohong" 192.168.100.101:6379> expire name 10 ##Setting the timeout time of KEY value (integer) 1 192.168.100.101:6379> ttl name ##View the current remaining timeout time for KEY values (integer) 4 192.168.100.101:6379> get name "xiaohong" 192.168.100.101:6379> get name (nil) 192.168.100.101:6379> keys * 1) "hello"
list -- list of operations in Redis;
Summary: Redis list is a simple list of strings, which can be analogized to std::list in C++, simply a linked list or a queue. You can add elements from the head or tail to the Redis list. The maximum length of the list is 2 ^ 32 - 1, which means that each list supports more than 4 billion elements. Redis list is implemented as a two-way linked list to support reverse lookup and traversal, which is more convenient to operate, but it brings some extra memory overhead. Many implementations in Redis, including sending buffer queues, are also using this data structure.
Application scenarios: Redis list has many application scenarios, and it is also one of Redis's most important data structures. For example, twitter's list of concerns and fans can be implemented by Redis's list structure. For example, some applications use Redis's list type to implement a simple lightweight message queue, producer push, consumer. pop/bpop.
[root@redis ~]# redis -h 192.168.100.101 -p 6379 -a 123123 192.168.100.101:6379> rpush list1 1 ##Create lists and insert elements at the end (integer) 1 192.168.100.101:6379> rpush list1 2 (integer) 2 192.168.100.101:6379> lrange list1 0 1 ##Validate from element 0 to element 1 in the list 1) "1" 2) "2" 192.168.100.101:6379> lpush list1 0 ##Insert elements at the head of the list (integer) 3 192.168.100.101:6379> lrange list1 0 1 1) "0" 2) "1" 192.168.100.101:6379> lrange list1 0 2 ##Validate from element 0 to element 2 in the list 1) "0" 2) "1" 3) "2" 192.168.100.101:6379> llen list1 ##View the number of elements in the list (integer) 3 192.168.100.101:6379> lindex list1 1 ##Locate the first element in the list "1" 192.168.100.101:6379> ltrim list1 1 2 ##Intercept the first element to the second element in the list OK 192.168.100.101:6379> lrange list1 0 10 ##View elements 0 to 10 in the list 1) "1" 2) "2" 192.168.100.101:6379> lset list1 1 haha ##Change the value of the first element in the list to haha OK 192.168.100.101:6379> lrange list1 0 10 1) "1" 2) "haha" 192.168.100.101:6379> lset list1 2 haha ##Validate that the location of the element when the change is made cannot be greater than the number of existing elements (error) ERR index out of range 192.168.100.101:6379> lrange list1 0 10 1) "1" 2) "haha" 192.168.100.101:6379> rpush list1 haha ##Insert new elements at the end of the list (integer) 3 192.168.100.101:6379> lrange list1 0 10 1) "1" 2) "haha" 3) "haha" 192.168.100.101:6379> lrem list1 2 haha ##Delete two haha-valued elements from the list (integer) 2 192.168.100.101:6379> lrange list1 0 10 1) "1" 192.168.100.101:6379> rpush list1 haha (integer) 2 192.168.100.101:6379> rpush list1 haha (integer) 3 192.168.100.101:6379> rpush list1 haha (integer) 4 192.168.100.101:6379> rpush list1 haha (integer) 5 192.168.100.101:6379> lrange list1 0 10 1) "1" 2) "haha" 3) "haha" 4) "haha" 5) "haha" 192.168.100.101:6379> lpop list1 ##Delete the first element at the beginning of the list "1" 192.168.100.101:6379> lrange list1 0 10 1) "haha" 2) "haha" 3) "haha" 4) "haha" 192.168.100.101:6379> lpop list1 "haha" 192.168.100.101:6379> lrange list1 0 10 1) "haha" 2) "haha" 3) "haha"
Set of operations in Redis -- an unordered set;
Overview: It can be understood as a set of non-repetitive lists, similar to the concept of sets in the field of mathematics, and Redis also provides operations for intersection, Union and difference sets of sets. Set's internal implementation is a HashMap whose value is always null. In fact, it can be quickly ranked by calculating hash, which is why set can provide a way to determine whether a member is in a set.
Application scenario: Redis set is similar to list in that it can automatically arrange the set. Set is a good choice when you need to store a list of data and don't want duplicate data. Set also provides a way to determine whether a member is in a set set set. This is also an important interface that list can't provide. Or in the microblog application, it is easy to achieve the function of finding two people's common friends when there is a set of people that each user cares about.
[root@redis ~]# redis -h 192.168.100.101 -p 6379 -a 123123 192.168.100.101:6379> sadd set1 0 ##Create set1 and assign 0 (integer) 1 192.168.100.101:6379> sadd set1 1 ##Additional value 1 after set1 (integer) 1 192.168.100.101:6379> smembers set1 ##Display all values of set1 1) "0" 2) "1" 192.168.100.101:6379> scard set1 ##Display the cardinality of set1 (integer) 2 192.168.100.101:6379> sismember set1 0 ##Shows whether set1 contains elements with a value of 0 (integer) 1 192.168.100.101:6379> srandmember set1 ##Random return of element values in set1 "0" 192.168.100.101:6379> sadd set2 0 ##Create set2 and add elements (integer) 1 192.168.100.101:6379> sadd set2 2 (integer) 1 192.168.100.101:6379> sinter set1 set2 ##Intersection of filtering set1 and set2 1) "0" 192.168.100.101:6379> sinterstore set3 set1 set2 ##Save the intersection of set1 and set2 to set3 (integer) 1 192.168.100.101:6379> smembers set3 1) "0" 192.168.100.101:6379> sunion set1 set2 ##Combination of filtering set1 and set2 1) "0" 2) "1" 3) "2" 192.168.100.101:6379> sdiff set1 set2 ##The difference set of set1 relative to set2 1) "1" 192.168.100.101:6379> sdiff set2 set1 ##In contrast to set1, the difference set of set2 1) "2" 192.168.100.101:6379> keys * ##View keys for various data types that already exist 1) "set1" 2) "hello" 3) "list" 4) "list1" 5) "set2"
zset-ordered set of operations in Redis;
Summary: Redis ordered sets are similar to Redis disordered sets, except that a function is added, that is, the set is ordered. Each member of an ordered set has a score for sorting. The time complexity of adding, deleting and testing ordered Redis sets is O (1) (fixed time, regardless of the number of element sets contained therein). The maximum length of the list is 2 ^ 32 - 1 elements (4294967295, a collection of more than 4 billion elements).
Redis sorted set uses HashMap and SkipList to ensure the storage and ordering of data. HashMap places the mapping of members to score, while the jump table stores all members. The ranking is based on the score stored in HashMap. Using the structure of jump table can achieve higher search efficiency, and in reality. It's relatively simple now.
Use scenarios: Redis sorted set uses scenarios similar to set, except that set is not automatically ordered, while sorted set can rank members by providing an additional priority (score) parameter to the user, and is insert ordered, that is, automatic sorting. When you need an ordered and non-repetitive list of collections, you can choose the sorted set data structure.
[root@redis ~]# redis -h 192.168.100.101 -p 6379 -a 123123 192.168.100.101:6379> zadd zset1 1 baidu.com ##Create the set zset1, add the element baidu.com, and set the score value of the element (the serial number of the ordered set) to 1 (integer) 1 192.168.100.101:6379> zadd zset1 2 sina.com (integer) 1 192.168.100.101:6379> zadd zset1 3 qq.com (integer) 1 192.168.100.101:6379> zrange zset1 0 2 ##View the elements in the collection zset1 1) "baidu.com" 2) "sina.com" 3) "qq.com" 192.168.100.101:6379> zcard zset1 ##View the cardinality in set zset1 (integer) 3 192.168.100.101:6379> zscore zset1 baidu.com ##Validate the score value of baidu.com in set zset1 "1" 192.168.100.101:6379> zscore zset1 qq.com ##Verify the score value of the element qq.com in set zset1 "3" 192.168.100.101:6379> zrevrange zset1 0 1 ##Look up elements in the set in reverse order. 1) "qq.com" 2) "sina.com" 192.168.100.101:6379> zrem zset1 qq.com ##Delete the element qq.com in the collection (integer) 1 192.168.100.101:6379> zrange zset1 0 5 ##Verify all elements in a collection 1) "baidu.com" 2) "sina.com" 192.168.100.101:6379> zincrby zset1 5 taobao.com ##Set the score value of the element to 5. If this element does not exist, it will be added to the collection. "5" 192.168.100.101:6379> zrange zset1 0 5 ##Verify Primary Colors in Sets 1) "baidu.com" 2) "sina.com" 3) "taobao.com" 192.168.100.101:6379> zrange zset1 0 5 withscores ##View element values in a collection and output their own score values 1) "baidu.com" 2) "1" 3) "sina.com" 4) "2" 5) "taobao.com" 6) "5" 192.168.100.101:6379> zincrby zset1 10 haha.com ##Add a new element, haha.com, and specify its own score value "10" 192.168.100.101:6379> zrange zset1 0 5 withscores ##Sorting of Validation Elements 1) "baidu.com" 2) "1" 3) "sina.com" 4) "2" 5) "taobao.com" 6) "5" 7) "haha.com" 8) "10" 192.168.100.101:6379> zincrby zset1 15 baidu.com ##If the newly added element already exists, the specified score value will be added to the original score value. "16" 192.168.100.101:6379> zrange zset1 0 5 withscores ##The score value of the validation element baidu.com changes to 16, increases by 15, and ranks at the end of the collection 1) "sina.com" 2) "2" 3) "taobao.com" 4) "5" 5) "haha.com" 6) "10" 7) "baidu.com" 8) "16" //Note: In addition, there are operations such as zrevrank, zrevrange, zrange by score, zremrange by rank, zramrange by score, zinterstore/zunionstore, etc.
hash of operation in Redis;
Overview: Similar to dict type in C# or hash_map type in C++. Redis Hash corresponds to a HashMap inside the Value. When the number of members of the Hash is relatively small, Redis will use a one-dimensional array-like way to compact storage, rather than a real HashMap structure. The encoding of the corresponding value redisObject is a zipmap, which automatically turns into a real one when the number of members increases. HashMap, where encoding is ht.
Application scenario: Assuming that there are multiple users and corresponding user information, it can be used to store user ID as key and serialize user information into json format as value for saving.
[root@redis ~]# redis -h 192.168.100.101 -p 6379 -a 123123 192.168.100.101:6379> hset hash1 key1 value1 ##Set the key value hash1 and specify that the internal key corresponds to value (integer) 1 192.168.100.101:6379> hget hash1 key1 ##View the value of key1 in hash1 "value1" 192.168.100.101:6379> hexists hash1 key1 ##Check whether there is key1 in hash1 (integer) 1 192.168.100.101:6379> hset hash1 key2 value2 ##Create key2 in hash1 (integer) 1 192.168.100.101:6379> hlen hash1 ##View the cardinality of key values in hash1 (integer) 2 192.168.100.101:6379> hkeys hash1 ##Look at the keys specifically included in hash1 1) "key1" 2) "key2" 192.168.100.101:6379> hvals hash1 ##View the specific values contained in hash1 1) "value1" 2) "value2" 192.168.100.101:6379> hmget hash1 key1 key2 ##See what the value is by specifying the key in hash1 explicitly 1) "value1" 2) "value2" 192.168.100.101:6379> hgetall hash1 ##View the correspondence of all keys and values contained in hash1 1) "key1" 2) "value1" 3) "key2" 4) "value2" 192.168.100.101:6379> hset hash1 key4 10 ##Add a new key key4 with an integer value of 10 (integer) 1 192.168.100.101:6379> hincrby hash1 key4 15 ##Add 10 to key4 execution (integer only) (integer) 25 192.168.100.101:6379> hmset hash1 key5 value5 key6 value6 key7 value7 ##Batch addition of key-value pairs OK 192.168.100.101:6379> hgetall hash1 ##Verify batch-added key-value pairs 1) "key1" 2) "value1" 3) "key2" 4) "value2" 5) "key3" 6) "value3" 7) "key4" 8) "25" 9) "key5" 10) "value5" 11) "key6" 12) "value6" 13) "key7" 14) "value7" Redis Other operations in operation; [root@redis ~]# redis -h 192.168.100.101 -p 6379 -a 123123 192.168.100.101:6379> dbsize ##View the number of key s 192.168.100.101:6379> flushdb ##Delete all key s in the currently selected database 192.168.100.101:6379> flushall ##Delete all key s in all databases 192.168.100.101:6379> save ##Save data to disk synchronously 192.168.100.101:6379> bgsave ##Asynchronous preservation 192.168.100.101:6379> lastsave ##Unix timestamp successfully saved to disk last time 192.168.100.101:6379> info ##Query server information 192.168.100.101:6379> slaveof ##Change replication policy settings