1. Introduction to Redis
- Redis is an open source NoSQL database written in C.
- Redis runs in memory and supports persistence (storage on disk). It uses key-value storage as an indispensable part of the current distributed architecture.
- Redis server program is a single process model
- Redis services can start multiple Redis processes simultaneously on a single server, and the actual processing speed of Redis depends entirely on the execution efficiency of the main process. If only one Redis process is running on the server, the processing power of the server will decrease to some extent when multiple clients access it simultaneously. If multiple Redis processes are started on the same server, Redis can increase concurrent processing power while putting a lot of pressure on the server's CPU. That is, in a real production environment, you need to decide how many Redis processes to start based on your actual needs.
It is recommended that you start two processes Reason: 1,backups 2,Resist high concurrency while trying not to give CPU Cause too much pressure If high concurrency is more demanding, you might consider starting multiple processes on the same server. if CPU Resources are tight, single process can be used.
1. Reasons for fast single process
- Use epoll (default) + I/O multiplexing mechanism
First, Redis runs in a single process, and all operations are performed linearly in sequence. However, since read and write operations wait for user input or output to be blocked, I/O operations usually cannot be returned directly. This can lead to I/O blocking of a file, which prevents the entire process from servicing other customers. I/O multiplexing arises to solve this problem.
2. Advantages of epoll mechanism
- There is no maximum concurrent connection limit for epoll. The upper limit is the maximum number of files that can be opened. This number is generally much greater than 2048. Generally, this number has a large relationship with system memory and can be viewed by cat/proc/sys/fs/file-max.
- The most powerful advantage of Epoll is that it only "actively" connects you, regardless of the total number of connections, so in a real network environment, Epoll is much more efficient than select and poll.
- Memory copy, Epoll uses "shared memory" for this purpose. This memory copy also omits I/O multiplexing. Through a mechanism, multiple descriptors can be monitored, and once a descriptor is ready, programs can be notified to operate accordingly.
The I/O multiplexing implemented by the epoll model can be defined as follows:
socket 1 —>
socket 2 -> I/O multiplexer -> file event dispatcher (obtained from queue and redistributed to corresponding processor) -> processor for command processing, request, connection response, etc.
socket 3 —>
-
Multiple socket s are defined as an fd file descriptor (each new, open, modify, and so on "event" kernel returns an fd (which can be understood as an index). Callback functions in the kernel occur when each fd is activated
-
An I/O multiplexer listens for an active link to a socket and then calls it (a socket file handle that primarily implements a "process" in the network identified by the "ip+port+protocol" on the network) can be simply understood as a virtual interface (abstraction layer)
Essentially, one thread is used to track the state of multiple socket s (I/O streams) to manage multiple I/Os -
I/O multiplexing: A thread tracks and manages multiple connections simultaneously (one thread corresponds to one connection by default) callbacks: specific execution processes are predefined (a method is defined), callbacks are waiting to be invoked, and callbacks can be completed based on the "trigger" hook when a thread executes.
It improves processing performance and saves resources.
2. Redis Advantages
- (redis feature (compared with other nosql)
1. Has a very high speed of data reading and writing: data can be read up to 110,000 times/s, and data can be written up to 81,000 times/s.
2. Support rich data types: support data type operations such as key-value, Strings, Lists, Hashes (hashed values), Sets, and Ordered Sets.
ps:
string strings (can be integer, floating point, and character types, collectively referred to as elements)
List list: (implements queues, elements are not unique, first in, first out principle)
set collection: (different elements)
hash hash value: (hash key must be unique)
Set/ordered sets collection/ordered set
3. Supports data persistence: data in memory can be saved to disk and reloaded for use on reboot.
4. Atomicity: All operations of Redis are atomic.
5. Support data backup: master-salve mode data backup.
- Rich features - Redis also supports publish/subscribe, notification, key expiration, and more.
- Redis is a memory-based database, and caching is one of its most common scenarios. In addition, common Redis scenarios include operations to get the latest N data, ranking applications, counter applications, storage relationships, real-time analysis systems, and logging.
- Data type operations such as key-value, Strings, Lists, Hashes (hashed values), Sets, and Ordered Sets are supported.
3. redis deployment
1.Redis installation deployment and compilation installation
systemctl stop firewalld setenforce 0 yum install -y gcc gcc-c++ make #Upload the redis-5.0.7.tar.gz zip package to the / opt directory tar zxvf redis-5.0.7.tar.gz -C /opt/ cd /opt/redis-5.0.7/ make PREFIX=/usr/local/redis install #Since the Makefile file file is directly available in the Redis source package, you can install it directly by executing make and make install commands without first executing. /configure after unpacking the package. #Execute the install_provided by the package The server.sh script file sets up the configuration files required for the Redis service cd /opt/redis-5.0.7/utils ./install_server.sh ....... #Keep returning. Please select the redis executable path [/usr/local/bin/redis-server] /usr/local/redis/bin/redis-server #Need to be manually modified to/usr/local/redis/bin/redis-server Note that correct input is required at one time --------------------------------------------------------------------------------------------------------- Selected config: Port : 6379 #Default listening port is 6379 Config file : /etc/redis/6379.conf #Profile Path Log file : /var/log/redis_6379.log #log file path Data dir : /var/lib/ redis/6379 #Data File Path Executable : /usr/local/redis/bin/redis-server #Executable path Cli Executable : /usr/local/redis/bin/redis-cli #Client Command Tool
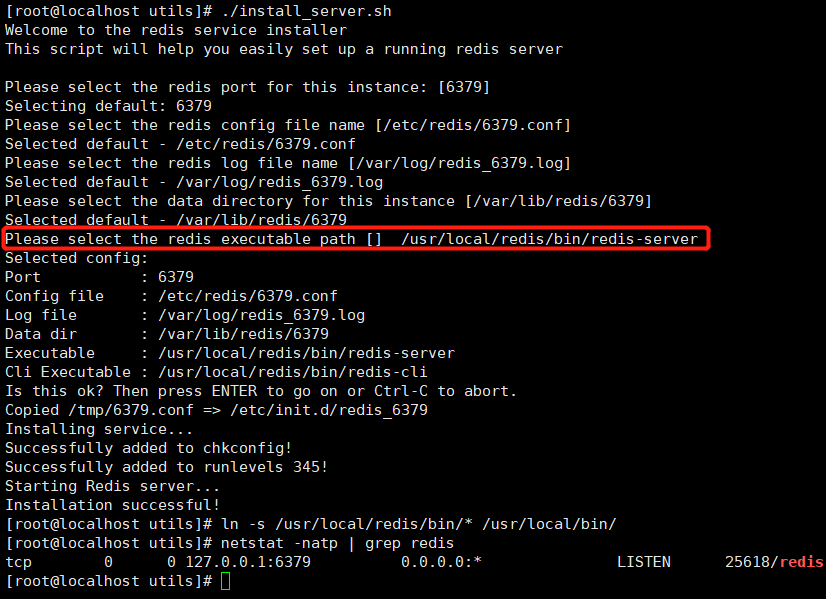
2. Configure Redis-related profiles and start services
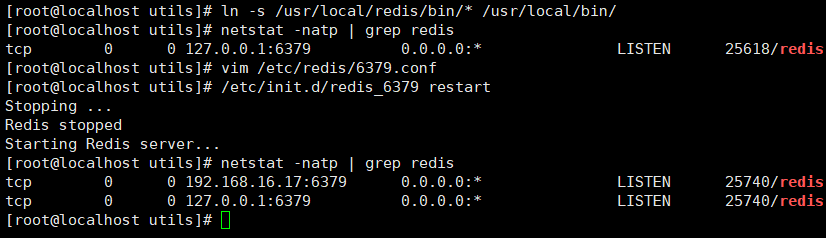
#Put redis executable files in directory of path environment variables for system identification ln -s /usr/local/redis/bin/* /usr/local/bin/ #When install_ When the server.sh script is finished, the Redis service is started and the default listening port is 6379 netstat -natp | grep redis tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6433/redis-server 1 #Redis Service Control /etc/init.d/redis_6379 stop #Stop it /etc/init.d/redis_6379 start #start-up /etc/init.d/redis_6379 restart #restart /etc/init.d/redis_6379 status #state #Modify configuration/etc/redis/6379.conf parameters vim /etc/redis/6379.conf bind 127.0.0.1 192.168.16.17 #70 lines, add host address for listening port 6379 #93 lines, Redis default listening port daemonize yes #Line 137, enable daemon pidfile /var/run/redis_6379.pid #159 lines, specifying the PID file loglevel notice #167 lines, log level logfile /var/log/redis_6379.log #172 lines, specify log file /etc/init.d/redis_6379 restart //Restart redis [root@c7-4 utils]# netstat -natp | grep redis tcp 0 0 192.168.16.17:6379 0.0.0.0:* LISTEN 6539/redis-server 1 tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6539/redis-server 1
4. Common Redis Tools
redis-server: For startup Redis Tools redis-benchmark: For detection Redis Operating efficiency locally redis-check-aof: repair AOF Persist Files redis-check-rdb: repair RDB Persist Files redis-cli: Redis Command Line Tools. rdb and aof yes redis Two forms of persistence functionality in services RDB AOF redis-cli Commonly used to login to redis data base
5. redis-cli command line tool (remote login)
grammar: redis-cli -h host -p port -a password -h :Specify remote host -p :Appoint Redis Port number of service -a :Specify the password, the database password can be omitted if it is not set-a option If no option representation is added, use 127.0.0.1:6379 Connect local Redis Database, redis-cli -h 192.168.16.17 -p 6379
6. redis-benchmark test tool
redis-benchmark is an official Redis performance test tool that can effectively test the performance of Redis services.
Basic test syntax: redis-benchmark [option] [Option Value] -h :Specify the server host name. -p :Specify the server port. -s :Specify Server socket(Socket) -c :Specify the number of concurrent connections. -n :Specify the number of requests. -d :Specify in bytes SET/GET The data size of the value. -k : 1=keep alive 0=reconnect -r : SET/GET/INCR Use Random key, SADD Use random values. -P :Pipeline transmission<numreq>Request. -q :forced return redis. Show Only query/sec Value. --csv :with CSV Format output. -l :Generate loops to permanently execute tests. -t :Run only a comma-separated list of test commands. -I : Idle Pattern. Open only N individual idle Connect and wait.
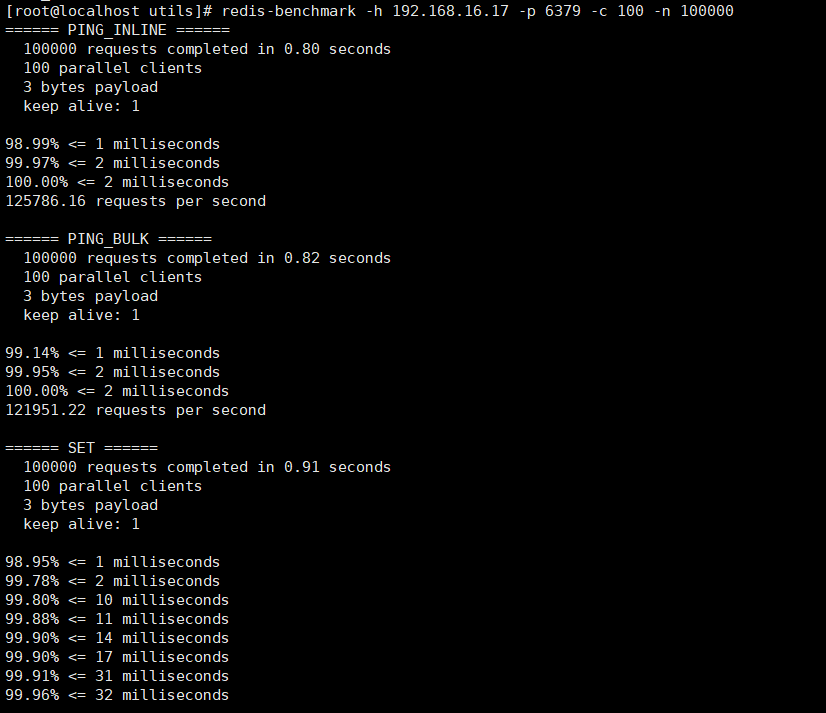
- Test performance by sending 100 concurrent connections and 100000 requests to Edits server with IP address 192.168.16.17 and port 6379
redis-benchmark -h 192.168.16.17 -p 6379 -c 100 -n 100000
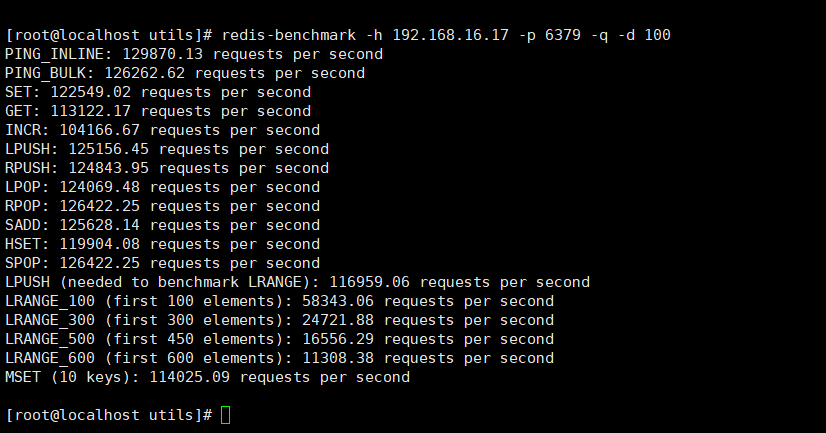
- Test the performance of accessing a 100 byte packet
redis-benchmark -h 192.168.16.17 -p 6379 -q -d 100
- Test the performance of Redis services on your machine for set and lpush operations
redis-benchmark -t set,lpush -n 100000 -q

7. Common commands for Redis databases
set: Store data in command format set key value get: Get data in command format get key redis-cli 127.0.0.1:6379> set teacher zhangsan OK 127.0.0.1:6379> get teacher "zhangsan" #The keys command can take a list of keys that match the rules, usually in combination with *,? And so on. 127.0.0.1:6379> set k1 1 127.0.0.1:6379> set k2 2 127.0.0.1:6379> set k3 3 127.0.0.1:6379> set v1 4 127.0.0.1:6379> set v5 5 127.0.0.1:6379> set v22 5 127.0.0.1:6379> KEYS * #View all keys in the current database 1) "v5" 2) "myset:__rand_int__" 3) "v1" 4) "counter:__rand_int__" 5) "v22" 6) "teacher" 7) "k2" 8) "mylist" 9) "k3" 10) "key:__rand_int__" 11) "k1" 127.0.0.1:6379> KEYS v* #View data starting with v in the current database 1) "v5" 2) "v1" 3) "v22" 127.0.0.1:6379> KEYS v? #View data in the current database that contains any bit after beginning with v 1) "v5" 2) "v1" 127.0.0.1:6379> KEYS v?? #View data in the current database that starts with v and ends with any two digits 1) "v22" #The exists command can determine if a key value exists. 127.0.0.1:6379> exists teacher #Determine whether the teacher key exists (integer) 1 # 1 indicates that the teacher key exists 127.0.0.1:6379> exists tea (integer) 0 #0 means the tea key does not exist #The del command deletes the specified key from the current database. 127.0.0.1:6379> keys * 127.0.0.1:6379> del v5 (integer) 1 127.0.0.1:6379> get v5 (nil) # The type command gets the value type for the key. 127.0.0.1:6379> type k1 string # The rename command renames an existing key. (Coverage) Command Format: rename source key target key Use rename When a command is renamed, regardless of the target key Rename all existing and source key The value of will override the target key Value of. In practice, it is recommended to use first exists Command View Target key Exist before deciding whether to execute rename Commands to avoid overwriting important data. 127.0.0.1:6379> keys v* 1) "v1" 2) "v22" 127.0.0.1:6379> rename v22 v2 OK 127.0.0.1:6379> keys v* 1) "v1" 2) "v2" 127.0.0.1:6379> get v1 "4" 127.0.0.1:6379> get v2 "5" 127.0.0.1:6379> rename v1 v2 127.0.0.1:6379> get v1 (nil) 127.0.0.1:6379> get v2 "4" # renamenx rename n No modifications x Modify nx Combination: Decide first what the command does to the existing key Rename and detect if the new name exists if the target key Exists without renaming. (Not Covered) Command Format: renamenx source key target key 127.0.0.1 :6379> keys * 127.0.0.1:6379> get teacher "zhangsan" 127.0.0.1:6379> get v2 "4" 127.0.0.1:6379> renamenx v2 teacher (integer) 0 127.0.0.1:6379> keys * 127.0.0.1 :6379> get teacher "zhangsan" 127.0.0.1:6379> get v2 "4" #The dbsize command is used to view the number of key s in the current database. 127.0.0.1:6379> dbsize (integer) 9 #Use the config set requirepass your password command to set the password 127.0.0.1:6379> config set requirepass 123456 #Use the config get requirepass command to view the password (once the password is set, you must first verify the pass password, otherwise all operations are not available) 127.0.0.1:6379> auth 123456 127.0.0.1:6379> config get requirepass #Remove password 127.0.0.1:6379> auth 123123 127.0.0.1:6379> config set requirepass '' #Unable to restart redis without setting above
8. Common commands for Redis multi-database (16 libraries 0-15)
Redis Support multiple databases, Redis By default, there are 16 databases with a database name of 0-15 To name them in turn. Many databases are independent and do not interfere with each other. #Switching between multiple databases Command Format: select Sequence Number Use redis-cli Connect Redis After the database, the default is to use a database with a sequence number of 0. 127.0.0.1:6379> select 10 #Switch to database with serial number 10 127.0.0.1:6379[10]> select 15 #Switch to database 15 127.0.0.1:6379[15]> select 0 #Switch to database with sequence number 0 #Moving data between multiple databases format: move Key value ordinal 127.0.0.1:6379> set k1 100 OK 127.0.0.1:6379> get k1 "100" 127.0.0.1:6379> select 1 OK 127.0.0.1:6379[1]> get k1 (nil) 127.0.0.1:6379[1]> select 0 #Switch to target database 0 OK 127.0.0.1:6379> get k1 #See if the target data exists "100" 127.0.0.1:6379> move k1 1 #Move k1 from Database 0 to Database 1 (integer) 1 127.0.0.1:6379> select 1 #Switch to Target Database 1 OK 127.0.0.1:6379[1]> get k1 #View moved data "100" 127.0.0.1:6379[1]> select 0 OK 127.0.0.1:6379> get k1 #The value of k1 cannot be seen in database 0 (nil) #Clean up data in the database (rm-rf) FLUSHDB :Empty the current database data FLUSHALL :Empty all database data, use with caution! redis Remote data backup (full, incremental) Yes Shell Form of script redis_backup.sh #!/bin/bash TIME=$ BCDIR= redis_server= post psword redis Cache Penetration Breakdown Avalanche redis Distributed Lock () nginx SSL Add Secret nginx Expose some interfaces and so on