Redis data structure
Redis multi database
-
Redis server has 16 databases (0 ~ 15). Database 0 is used by default. You can use the select command to switch databases
Note: 16 databases are independent, and the same key value pairs can be saved
-
To clear the data of the current database, you can use the flushdb command
-
To clear the data of all Redis databases, you can use the flush command
-
Redis does not support user-defined database names. The default is 0, 1, 2, 3, 4... 15
-
Redis does not support setting different access passwords for each database (the default password is blank)
Redis basic operation commands
Note: Redis key s can only be string type
-
set: insert data
-
get: query data
-
set: modify data
-
del: delete data
Redis general operation command
-
keys: query all key s
The format is keys pattern, which supports glob style wildcard format:
? match one character
*Match any character
[] matches any character in brackets. You can use - to represent the range
\X matches the character x for escape symbols
-
Exists: determines whether the key value exists
-
Type: gets the data type of the key value
-
rename: rename
-
Rename X: Rename (newKey does not exist)
Redis core object
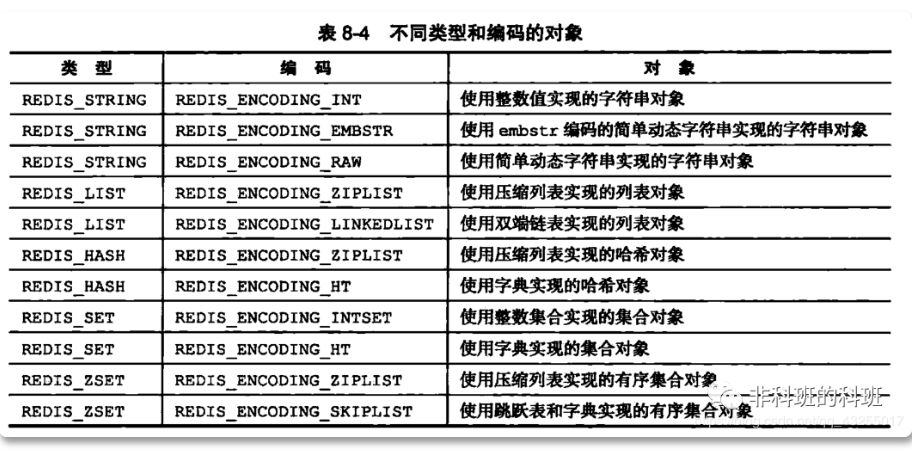
In Redis, there is a "core object" called redisObject, which is used to represent all key s and value s. The redisObject structure is used to represent five data types: String, Hash, List, Set and ZSet.
The source code of redisObject is written in c language in redis.h. you can view it yourself if you are interested. Here I draw a diagram of redisObject, showing the structure of redisObject as follows:
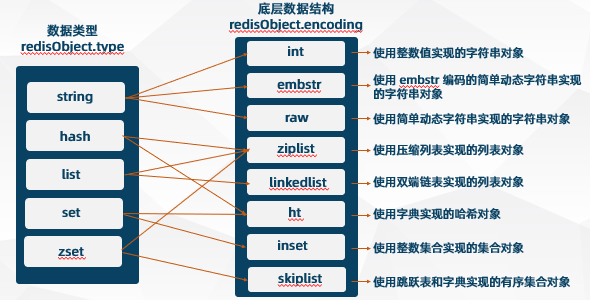
In redisObject, "type indicates which data type it belongs to, and encoding indicates the storage method of the data", that is, the data structure of the data type implemented by the underlying.
127.0.0.1:6379> set k1 234 OK 127.0.0.1:6379> set k2 3.200 OK 127.0.0.1:6379> type k1 #View data types string 127.0.0.1:6379> type k2 string 127.0.0.1:6379> object encoding k1 #View the data structure of the underlying storage "int" 127.0.0.1:6379> object encoding k2 "embstr"
Redis database supports five data types:
- strings
- List (string list)
- Set (string set)
- zset (ordered string set)
- Hash (hash)
key naming considerations:
- The key should not be too long. Try not to exceed 1024 bytes, which will not only consume memory, but also reduce the search efficiency;
- The key should not be too short. If it is too short, the readability of the key will be reduced;
- In a project, it is best to use a unified naming pattern for key s, such as user:10000:passwd
Strings
strings is a basic data type and a necessary data type for any storage system. It can store binary data (up to 512 M)
127.0.0.1:6379> set mystr "hello,world!" OK 127.0.0.1:6379> get mystr "hello,world!" 127.0.0.1:6379> append mystr hahah #Tail append (integer) 17 127.0.0.1:6379> mset k1 11 k2 22 k3 33 #Set the values of multiple keys at the same time OK 127.0.0.1:6379> mget k1 k2 k3 #Get the values of multiple keys at the same time 127.0.0.1:6379> set mynum "2" OK 127.0.0.1:6379> get mynum "2" 127.0.0.1:6379> incr mynum #Increasing (integer) 3 127.0.0.1:6379> get mynum "3" 127.0.0.1:6379> decr mynum #Diminishing (integer) 3 127.0.0.1:6379> get mynum "2" 127.0.0.1:6379> incrby num 3 #Increment (increment value) (integer) 4 127.0.0.1:6379> decrby num 3 #Decrement (increment value) (integer) 1 127.0.0.1:6379> incrbyfloat num 3.3 #Increment / decrement (float) "7.3"
-
When encountering numeric operation, redis will convert string type to numeric value
-
Since INCR and other instructions have the characteristics of atomic operation, we can use the INCR, INCRBY, DECR, DECRBY and other instructions of redis to realize the effect of atomic counting
Hash (hash)
hashes stores the mapping between strings and string values
127.0.0.1:6379> hmset user name antirez password P1pp0 age 34 #Create a hash and assign a value OK 127.0.0.1:6379> hgetall user #Lists the contents of the hash 1) "username" 2) "antirez" 3) "password" 4) "P1pp0" 5) "age" 6) "34" 127.0.0.1:6379> hset user password 12345 #Change a value in the hash (integer) 0 127.0.0.1:6379> hkeys user #Get all field values 1) "id" 2) "name" 3) "age" 4) "gender" 127.0.0.1:6379> hvals user #Get all value values 1) "2" 2) "wu" 3) "23" 4) "male" 127.0.0.1:6379> hget user name #Gets the value of a field "wu" 127.0.0.1:6379> hmget user age gender ##Get the value value of multiple field s 1) "23" 2) "male" 127.0.0.1:6379> hdel user name #Delete a field (integer) 1 127.0.0.1:6379> hlen user #Query hash length (integer) 3 127.0.0.1:6379> hincrby user id 1 #The value of field increases automatically (integer) 12
List (string list)
The underlying implementation of lists in redis is not an array, but a linked list. That is to say, for a list with millions of elements, the time complexity of inserting a new element in the head and tail is constant. Although lists has such advantages, it also has its disadvantages, that is, the element query of linked list lists is relatively slow, while the array query is very slow It will be much faster.
127.0.0.1:6379> lpush mylist "1" #Create a new list and insert elements into the list header (integer) 1 #Returns the number of elements in the current mylist 127.0.0.1:6379> rpush mylist "2" #Insert element in mylist header (integer) 2 127.0.0.1:6379> lpush mylist "0" #Insert element at the end of mylist (integer) 3 127.0.0.1:6379> lrange mylist 0 1 #Lists the elements from 0 to 1 in mylist 1) "0" 2) "1" 127.0.0.1:6379> lrange mylist 0 -1 #Lists the first to last element from number 0 in mylist 1) "0" 2) "1" 3) "2" 127.0.0.1:6379> lindex mylist 0 #Gets the value of the specified index "1" 127.0.0.1:6379> lset mylist 0 11 #Sets the value of the specified location index OK 127.0.0.1:6379> lpop mylist #Header pop-up value "1" 127.0.0.1:6379> rpop mylist #Tail pop-up value "2" 127.0.0.1:6379> llen mylist #Get the number of elements in the list (integer) 1 127.0.0.1:6379> lrem mylist 2 2 #Delete the elements in the list (parameter 1:0 means to delete all the values specified in parameter 2: list) (integer) 0 127.0.0.1:6379> linsert mylist before 1 111 #Inserts an element before/end at the specified location (integer) 3
Set (string set)
Redis collection is an unordered collection, and the elements in the collection have no order.
127.0.0.1:6379> sadd myset "one" #Add a new element "one" to the collection myset (integer) 1 127.0.0.1:6379> smembers myset #Lists all elements in the collection myset 1) "one" 127.0.0.1:6379> sismember myset "one" #Judge whether element 1 is in the set myset, and return 1 to indicate existence (integer) 1 127.0.0.1:6379> sadd yourset "1" "2"#Create a new collection yourset (multiple elements can be added) (integer) 1 127.0.0.1:6379> sunion myset yourset #Union of two sets 1) "1" 2) "one" 127.0.0.1:6379> srem myset v1 #Delete collection elements (integer) 1 127.0.0.1:6379> scard myset #Get the number of collection elements (integer) 7 127.0.0.1:6379> srandmember myset 2 #Randomly obtain the specified number of collection elements (negative numbers have duplicates) 1) "5" 2) "1" 127.0.0.1:6379> spop myset 2 #Pop up the specified number of sets from the head 1) "3" 2) "4"
ZSet (ordered string set)
redis not only provides unordered sets, but also considerate ordered sets. Each element in an ordered set is associated with a score, which is the basis for sorting.
127.0.0.1:6379> zadd myzset 1 baidu.com #Add an ordered set, merge and add an element baidu.com, and the sequence number given to it is 1 (integer) 1 127.0.0.1:6379> zadd myzset 3 360.com #Add an element 360.com to myzset and give it a sequence number of 3 (integer) 1 127.0.0.1:6379> zadd myzset 2 google.com #Add an element google.com to myzset and give it a sequence number of 2 (integer) 1 127.0.0.1:6379> zrange myzset 0 -1 with scores #Lists all the elements of myzset and their ordinal numbers (in order) 1) "baidu.com" 2) "1" 3) "google.com" 4) "2" 5) "360.com" 6) "3" 127.0.0.1:6379> zrange myzset 0 -1 #Only the elements of myzset are listed 1) "baidu.com" 2) "google.com" 3) "360.com"
ZSet is an ordered set. From the figure above, we can see that the underlying implementation of ZSet is implemented by ziplist and skiplist. Ziplist has been described in detail above. Here we will explain the structural implementation of skiplist.
Skip list
Jump table is an ordered data structure. It maintains multiple pointers to other nodes through each node, so as to achieve the purpose of fast access.
skiplist has the following features:
- It is composed of many layers. The number of nodes from top to bottom is gradually dense. The nodes at the top layer are the most sparse and the span is the largest.
- Each layer is an ordered linked list, which contains at least two nodes, head node and tail node.
- Each node of each layer contains a pointer to the next node of the same layer and the same location node of the next layer.
- If a node appears in a certain layer, it will appear in the same position of all linked lists below.
The structure diagram of the specific implementation is as follows:
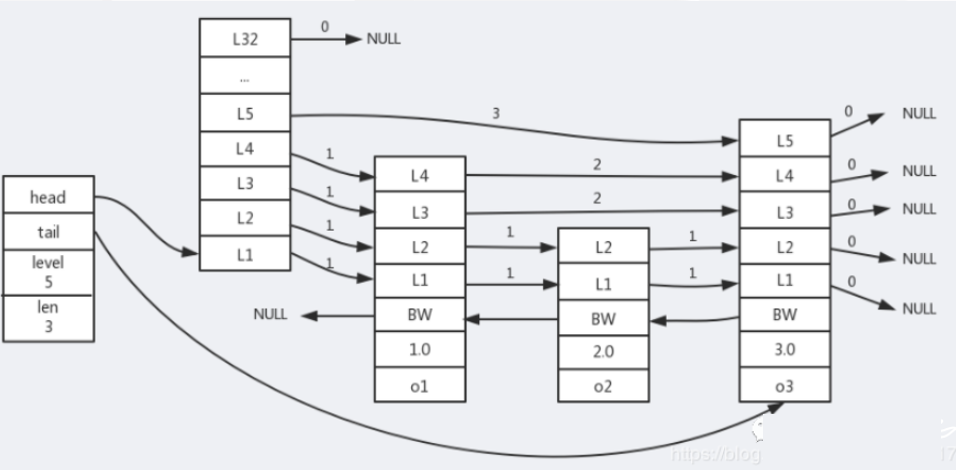
In the structure of the jump table, head and tail represent pointers to the head node and tail node, which can quickly realize positioning. level represents the number of layers, len represents the length of the jump table, BW represents the backward pointer, which is used when traversing forward from the tail.
There are also two values under BW, representing score and member object (member object saved by each node).
In the implementation of jump list, except that the lowest layer stores the complete data of the original linked list, the number of nodes in the upper layer will be less and less, and the span will be larger and larger.
The upper layer of the jump table is equivalent to the index layer, which serves to find the last data. The larger the amount of data, the higher the efficiency of the query reflected in the bar table, which is almost the same as that of the balance tree.
The essence of jump table is to establish multi-level index to improve query efficiency