- Reference to "Recommendation System Practice" Item Liang
- Concept: Item-based collaborative filtering algorithm, optimization algorithm
- Contrast: Advantages and Disadvantages of User Collaborative Filtering
- python coding implementation
1. Algorithmic Definition
| User-based collaborative filtering algorithm | Commodity-based Collaborative Filtering Algorithms | |
|---|---|---|
| Applicable scenario | Areas with strong timeliness and individualized user interest are not obvious | Long tail goods are abundant in areas where users have strong personalized needs |
| Occasions with fewer users: news recommendation | Where the number of items is far less than the number of users: books, e-commerce and movie websites | |
| Key points | Hotspots of Small Groups with Similar Interests | Maintain user's historical interest and recommendation result is explanatory. |
| User Interaction Characteristics | User's new behavior does not necessarily lead to immediate changes in recommendation results | Real-time changes in recommendation results |
| shortcoming | Computational complexity - user growth: approximate to the square relation, recommendation results are not very explanatory |

1.1 algorithm optimization
Assuming that <user-commodity data> is as follows, the similarity between commodities can be calculated.
1::a 1::b 1::c 2::a 2::b 3::c 4::a 4::d

2. python implementation
Step 1: Computing similarity between goods (cosine similarity formula)

Step 2: Filter & Generate Recommendation List, Summation of Preference Values

The code is as follows
# -*-coding:utf-8-*-
import math
#Step 1: Calculate the similarity between each item
def getMostLikeItemsGroupK(itemUsersDict):
recommDict = {}
for i, usersI in itemUsersDict.items():
for j, usersJ in itemUsersDict.items():
if i < j:
if i not in recommDict.keys():
recommDict[i] = {}
if j not in recommDict.keys():
recommDict[j] = {}
# Computation of similarity and number of common interactive products
ratio= 0.0
setA = set(usersI)
setB = set(usersJ)
common = setA.intersection(setB)
if common.__len__() == 0:
ratio= 0.0
else:
bot = math.sqrt(setA.__len__() * setB.__len__())
ratio= float(common.__len__()) / bot
recommDict[i][j] = ratio
recommDict[j][i] = ratio
# Sort each similarity dictionary in M in reverse order of similarity
dict2 = {}
for k,v in recommDict.items():
dict2[k] = sorted(v.items(), key=lambda e: e[1], reverse=True)
#1. Non-normalization of Item Similarity
#return dict2
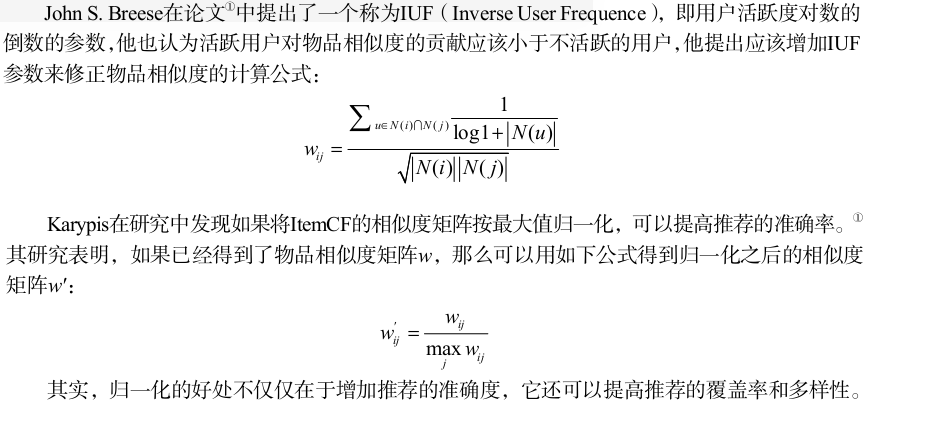
#2. Normalization of Item Similarity: Karypis found in the study that if
def normalItemLike(parmDict):
dict3 = {}
for k,v in parmDict.items():
dict3[k] = []
mx = v[0][1]
for t in v:
dict3[k].append((t[0] , float(t[1]) / mx))
return dict3
return normalItemLike(dict2)
##############Step 2: Filter & Generate Recommendation List, Summation of Preference Values
def recommItemCF(u,K):
# Prepare data: Recommendation dictionary returned [], dictionary between users - > commodities, dictionary between commodities - > users
recommDict = {}
userItemsDict = {}
itemUsersDict = {}
file = open("/home/wang/IdeaProjects/big124/mypython/a")
while True :
line = file.readline()
if line != '':
arr = line.replace("\n","").split("::")
uid = int(arr[0])
iid = str(arr[1])
# userItemDict
if uid in userItemsDict.keys():
userItemsDict[uid].append(iid)
else :
userItemsDict[uid] = [iid]
# itemUsersDict
if iid in itemUsersDict.keys():
itemUsersDict[iid].append(uid)
else:
itemUsersDict[iid] = [uid]
else:
break ;
# 1. Search for each user's history product: other similar product groups
dict1 = getMostLikeItemsGroupK(itemUsersDict)
for i in userItemsDict[u]: # Find historical goods for each user
itemsK = dict1[i][:K] #Take out k similar goods
for j in itemsK:
if j[0] not in userItemsDict[u]:
#2. Generate a list of product recommendations
if j[0] not in recommDict.keys():
recommDict[j[0]] = 0.0
recommDict[j[0]] = recommDict[j[0]] + j[1]
#3. Sort the list of commodity recommendations
return sorted(recommDict.items() , key=lambda e:e[1] ,reverse=True)
###############The third step, test result############################
if __name__ =="__main__":
recommList=recommItemCF(2,3)
for i in recommList:
print i
Contrast results: The accuracy of normalized similarity of goods becomes higher based on collaborative filtering of goods.
#User-based collaborative filtering: recommendation results
# ('c', 1.533734661597076)
# ('d', 0.8304820237218405)
#Commodity-based collaborative filtering: item similarity is not normalized, recommendation results
# ('c', 0.9082482904638631)
# ('d', 0.5773502691896258)
#Commodity-based Collaborative Filtering: Normalization of Item Similarity, Recommendation Results
# ('c', 1.1123724356957945)
# ('d', 0.7071067811865476)