1, Fundamentals
Here, "copy on write" is enclosed with a quotation mark, because this is specifically for the copy on write effect when rsync backup is used, rather than the actual copy on write effect. Its purpose is as follows:
After backing up the data using rsync, create a snapshot immediately:
- The data state of the snapshot will not be changed due to the subsequent synchronization behavior, but will always remain the state when the snapshot is created.
- The snapshot does not take up additional storage space.
- If the rsync backup is used again, the original file will change or a new file will appear, then only the changed file and the new file will occupy the new storage space.
The implementation of this function mainly depends on the fact that when using rsync for backup, the inode will be changed when comparing the new backup file with the original file for the file whose content changes.
We know that in the Linux file system, inode is used as the file index. Multiple files with the same inode number are called hard links, which point to the same piece of data in the hard disk and occupy the same storage space. Multiple hard links have the same status. There is no master-slave relationship. As long as a hard link copy is not deleted, the storage space occupied by this file will not be released. When we use rsync for backup, if the content of the file does not change, rsync skips the file and does not process it. If the content of the file changes, rsync deletes the original file and copies the file to the same file name again. At this time, although the file is the same, the inode will change, indicating that the files before and after backup are different files with the same file name.
Based on this fact, we can create a hard connection for each file after the backup is completed, and save it in the same directory structure. This behavior is called creating a snapshot here. After the snapshot is created, different files are backed up or the original files are deleted, which happens in the backup directory, without affecting the snapshot itself.
2, Basic experiment
Basic steps:
- Simulate real business scenarios, create a new data directory, and write experimental data to the data directory
- Create a backup directory and use rsync for backup
- Manually create the snapshot, compare the inode of the snapshot and the backup data, and view the total occupied space
- Change business data
- Use rsync for backup again, and compare the snapshot data before and after backup
The specific operation is as follows
# Create directory and write data mkdir data dd if=/dev/urandom of=data/bigfile bs=1M count=20 echo the first line in text file. > data/file.txt echo the another file. > data/file_another.txt # backups mkdir backup rsync -a --delete data/ backup/ # Create a snapshot manually mkdir snapshot-1 ls backup | xargs -i{} ln backup/{} snapshot-1/{} # View results du -sh; tree --inodes -sh
The results are as follows (the specific inode number may be different in each experiment):
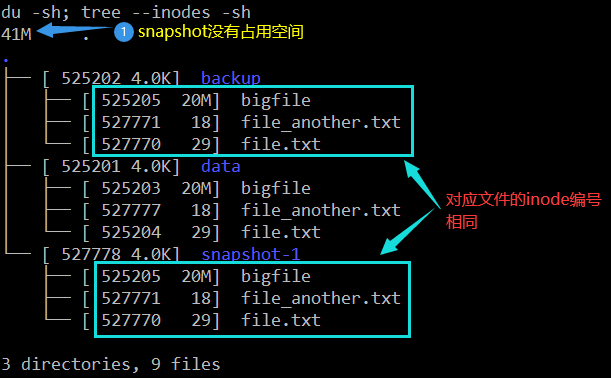
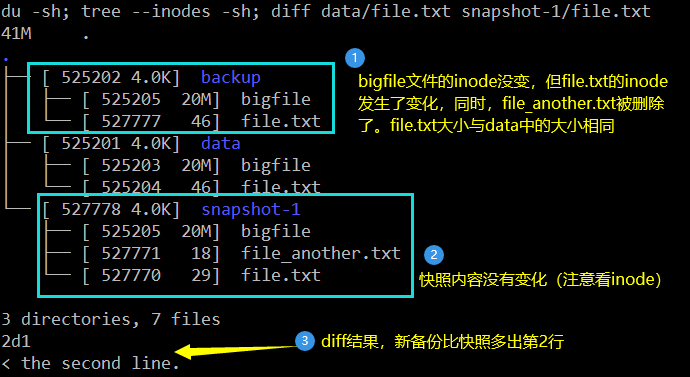
# Change business data echo the second line. >> data/file.txt rm data/file_another.txt # synchronization rsync -a --delete data/ backup/ # View results du -sh; tree --inodes -sh; diff data/file.txt snapshot-1/file.txt
The results are as follows:
3, General implementation
In order to make this backup method easy to use, write the creation and deletion of old backups as shell functions. You can use the following script source:
# Usage: MK? Snapshot backup? Dir snapshot? Dir function mk_snapshot(){ # mk_snapshot src_dir des_dir if [ ! -d "$1" ]; then echo "$1" is not a directory! >&2 return 1 fi WorkDir="$(pwd)" Target=$(realpath $2) cd "$1" find . -type d -exec mkdir -p "${Target}/{}" \; find . -type f -exec ln "{}" "${Target}/{}" \; # Because the mtime of the folder is not reliable, a. Snapshot file is created for later auxiliary find to judge the snapshot creation time touch "${Target}/.snapshot" cd "$WorkDir" } # Usage: delete the snapshot n days ago under the snapshots folder # clean_snapshot snapshots n function clean_snapshot(){ # clean_snapshot snapshot_dir/snapshot_for days_ago if [ ! -d "$1" ]; then echo "Error: \"$1\" is no a directory!" > &2 return 1 fi MountPoint=$(df "$1" | tail -1 | awk '{print $NF}') TempDir=$(mktemp -dp "$MountPoint") find "$1" -maxdepth 2 -mindepth 2 -mtime +$2 -type f -empty \ -name ".snapshot" -exec dirname "{}" \; | xargs -i{} mv {} $TempDir rm -rf "$TempDir" }
4, Advantages and disadvantages
Advantages of this backup solution:
- It can prevent the damaged business data from polluting the backup data and making the backup data unavailable
- Fast snapshot creation
- No additional storage space for duplicate data
Limitations and deficiencies:
- Because a hard connection is used, the snapshot and backup data must be in the same partition
- It is only applicable to unix like systems (windows can also create hard connections through mklink now, and interested partners can study it, welcome to exchange)