Let's think about a practical problem. When spring comes, we are going to buy clothes. At the same time, as a clothing manufacturer, we are going to release new clothes. If you are a technical consultant of a clothing manufacturer, please analyze what kind of clothes belong to this year's fashion trend and what would you do?
First of all, as a technical otaku, I don't think you will pay so much attention to the pop elements and not go to Paris fashion week. All you can do is analyze and predict based on various data. You may scan the code in the store to fill in the questionnaire and issue some coupons. You may also go to major fashion websites to pick up some comments and analysis articles. You may also go to microblog, an open social platform, to pick up some fashion bloggers' selfie sharing. You can try your best to get all kinds of data. What you need to do is to use these data to analyze the trend.
For this kind of analysis and prediction in-depth learning is undoubtedly a suitable model tool. The problem is that there are not only the data from this questionnaire, the model suitable for ordinary layer stacking for training, but also the text data of this review and analysis article, the article suitable for cyclic neural network, and the model suitable for convolutional neural network with various pictures to be analyzed. What can we do? According to our existing knowledge, we can consider training different network models respectively, and carry out weighted analysis on them. This is certainly a method, but the weight is too random, and each data is split, so it is not a good method to deal with them separately. What can we do?
To combine them and carry out joint learning, the general appearance is as follows:
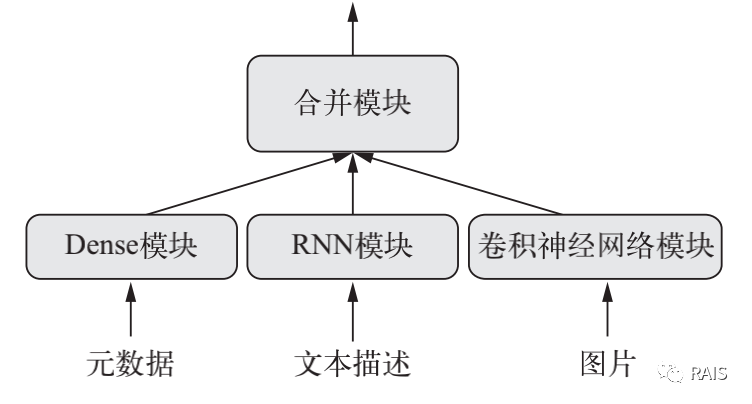
Of course, the joint model can not only receive multiple inputs at the same time, but also give outputs at the same time, such as popular elements and prices, multiple inputs and multiple outputs. This is not just a variety of linear networks we mentioned earlier, but more like the feeling of a graph. Yes, it is a graph similar to the data structure. Just as the graph in data structure is much more complex than the linear linked list, the joint model in deep learning is much more complex than a single model.
Functional API
This is preparatory knowledge, the so-called functional method. Fortunately, Keras supports such a method, that is, the layer is regarded as a function, and the parameters and return values of this function are tensors. Such functions can be combined to form a network model. See the following code example:
def run(): # We've learned to define layers with Sequential seq_model = Sequential() seq_model.add(layers.Dense(32, activation='relu', input_shape=(64,))) seq_model.add(layers.Dense(32, activation='relu')) seq_model.add(layers.Dense(10, activation='softmax')) seq_model.summary() # Define layers as functions input_tensor = Input(shape=(64,)) x = layers.Dense(32, activation='relu')(input_tensor) x = layers.Dense(32, activation='relu')(x) output_tensor = layers.Dense(10, activation='softmax')(x) model = Model(input_tensor, output_tensor) model.summary()
The two ways to define network model are equivalent. Input is used to define tensor. The original data can be converted into tensor for network training. Model is used to find the path from input ﹣ sensor to output ﹣ sensor and add it to the network.
Multiple input model
Suppose a model is conducting a simplified version of Turing test, and the model answers a question. The answer to this question is also handled by this model in an article. Then this model is a network with multiple inputs, as follows:
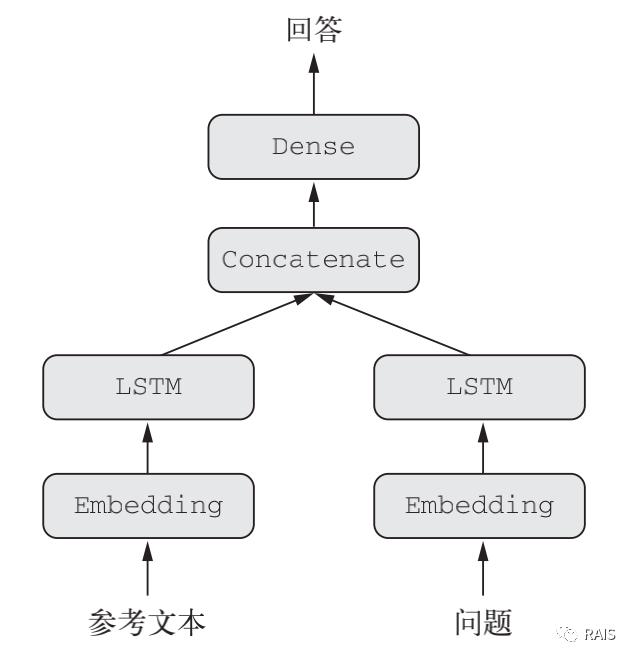
There are a lot of knowledge we have discussed before, such as LSTM is a cyclic neural network, which is used to process text. The Concatenate here needs to be explained as follows: Concatenate is used for connection, which can associate the input question with the answer text. The summary view of the network built with code looks like this:
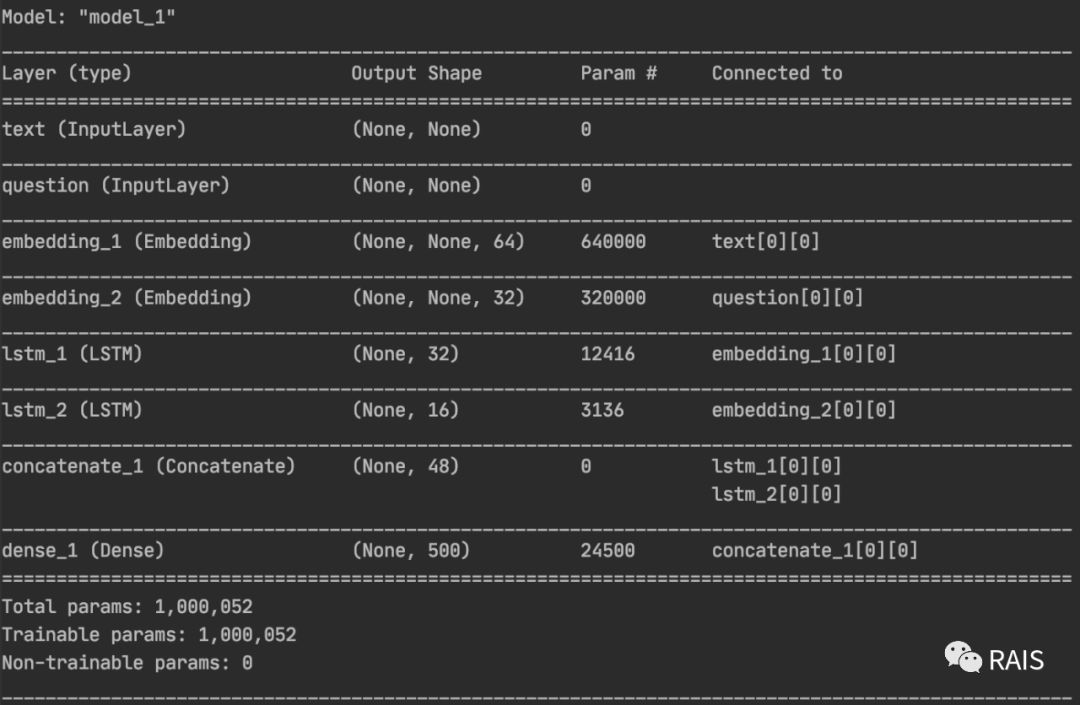
#!/usr/bin/env python3 import time import keras import numpy as np from keras import Input from keras import layers from keras.models import Model def run(): text_vocabulary_size = 10000 question_vocabulary_size = 10000 answer_vocabulary_size = 500 # Text input text_input = Input(shape=(None,), dtype='int32', name='text') # Convert input to vector embedded_text = layers.Embedding(text_vocabulary_size, 64)(text_input) # Convert input to a single vector encoded_text = layers.LSTM(32)(embedded_text) # Deal with the problem as above question_input = Input(shape=(None,), dtype='int32', name='question') embedded_question = layers.Embedding(question_vocabulary_size, 32)(question_input) encoded_question = layers.LSTM(16)(embedded_question) # Link questions to text concatenated = layers.concatenate([encoded_text, encoded_question], axis=-1) # Add a softmax classifier answer = layers.Dense(answer_vocabulary_size, activation='softmax')(concatenated) # Building model model = Model([text_input, question_input], answer) model.summary() model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc']) # Generating virtual training data is of little reference significance num_samples = 1000 max_length = 100 text = np.random.randint(1, text_vocabulary_size, size=(num_samples, max_length)) question = np.random.randint(1, question_vocabulary_size, size=(num_samples, max_length)) answers = np.random.randint(answer_vocabulary_size, size=(num_samples)) answers = keras.utils.to_categorical(answers, answer_vocabulary_size) model.fit([text, question], answers, epochs=10, batch_size=128) model.fit({'text': text, 'question': question}, answers, epochs=10, batch_size=128) if __name__ == "__main__": time_start = time.time() run() time_end = time.time() print('Time Used: ', time_end - time_start)
Multiple output model
In response to this problem, the actual use is very frequent, such as user portraits, my father's Baidu home page is different from my mother's, although they did not fill in personal information in the settings, but they still know what they like, how to do this?
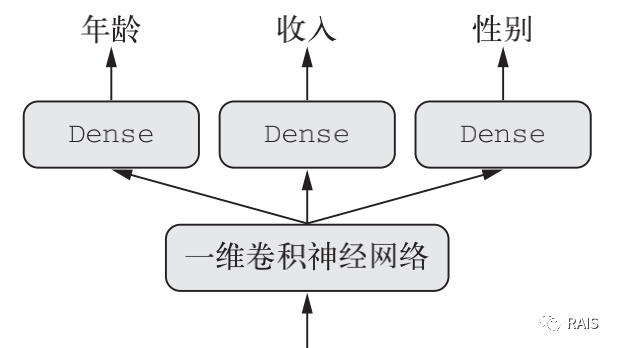
By browsing the news, we can roughly describe the age of the user's income, and then push the news that may be more interested by the Tag tag Tag of the news in the background. Note that the gender classification and income classification here are different, one is two classification, the other is multi classification, which also needs to define different loss functions. To accomplish this task, it is a good way to define the model when compiling it. It should be noted that the unbalanced loss contribution will affect the training of the model. If a certain loss value is particularly large, it will lead to the optimization of the model first, with little or no consideration of the optimization of other tasks. This is not what we want to see. Therefore, we can also define different loss contributions to the final loss and weight the loss:
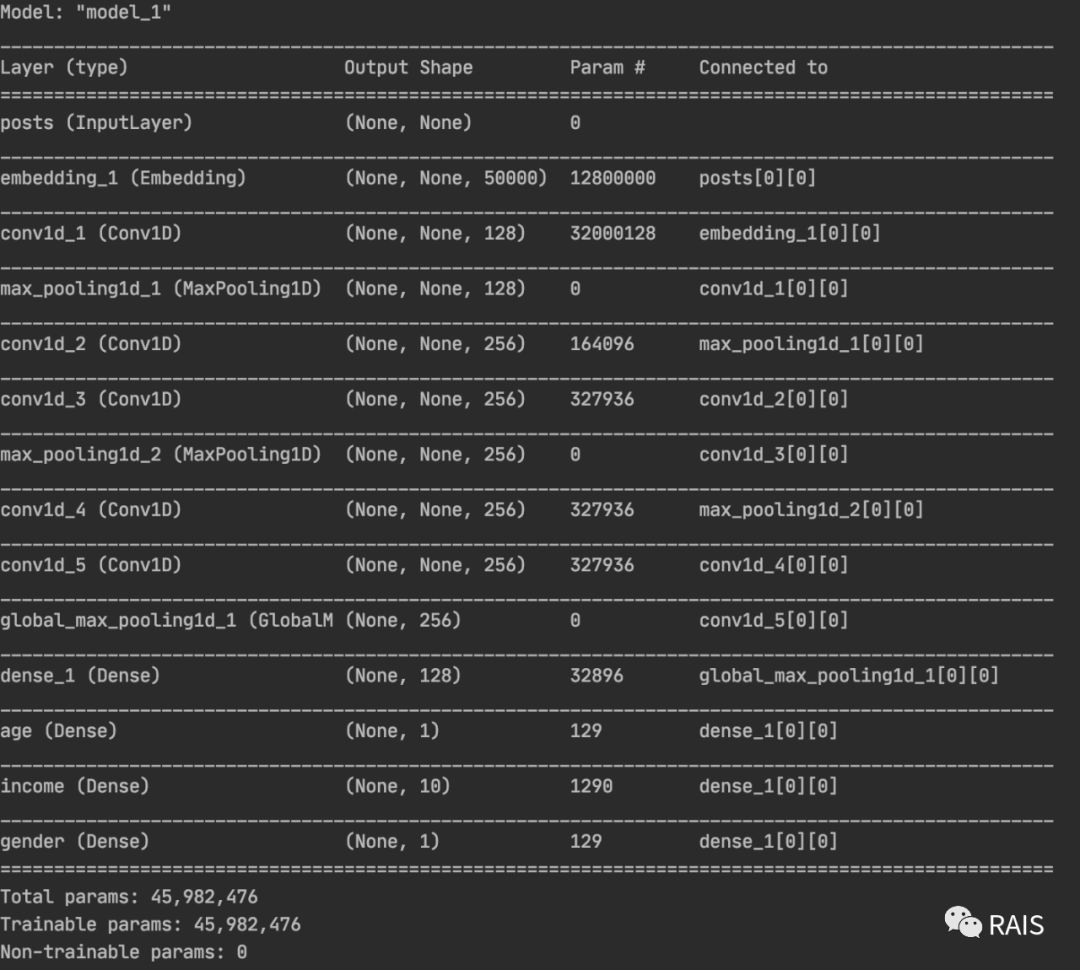
def run(): vocabulary_size = 50000 num_income_groups = 10 posts_input = Input(shape=(None,), dtype='int32', name='posts') embedded_posts = layers.Embedding(256, vocabulary_size)(posts_input) x = layers.Conv1D(128, 5, activation='relu')(embedded_posts) x = layers.MaxPooling1D(5)(x) x = layers.Conv1D(256, 5, activation='relu')(x) x = layers.Conv1D(256, 5, activation='relu')(x) x = layers.MaxPooling1D(5)(x) x = layers.Conv1D(256, 5, activation='relu')(x) x = layers.Conv1D(256, 5, activation='relu')(x) x = layers.GlobalMaxPooling1D()(x) x = layers.Dense(128, activation='relu')(x) age_prediction = layers.Dense(1, name='age')(x) income_prediction = layers.Dense(num_income_groups, activation='softmax', name='income')(x) gender_prediction = layers.Dense(1, activation='sigmoid', name='gender')(x) model = Model(posts_input, [age_prediction, income_prediction, gender_prediction]) model.summary() # Here's the point model.compile(optimizer='rmsprop', loss={'age': 'mse', 'income': 'categorical_crossentropy', 'gender': 'binary_crossentropy'}, loss_weights={'age': 0.25, 'income': 1., 'gender': 10.}) # model.fit(posts, [age_targets, income_targets, gender_targets], epochs=10, batch_size=64)
Graph structure
Of course, the graph structure here refers to the directed acyclic graph. There is no ring between layers, and there can be a ring (cyclic neural network) inside the layer. As mentioned above, the layer is like a function, and the tensor is the input and the output. Then these vectors can be used to combine the complex network graph structure like building blocks. You should also know how to do this Let's combine. Here are two very famous examples, as follows:
Perception module
This module helps to learn spatial features and features of each channel, which is more effective than joint learning. This model is built in keras. Applications. Inception ﹣ v3. Perception V3, which has a good efficiency and accuracy for dealing with ImageNet data set.
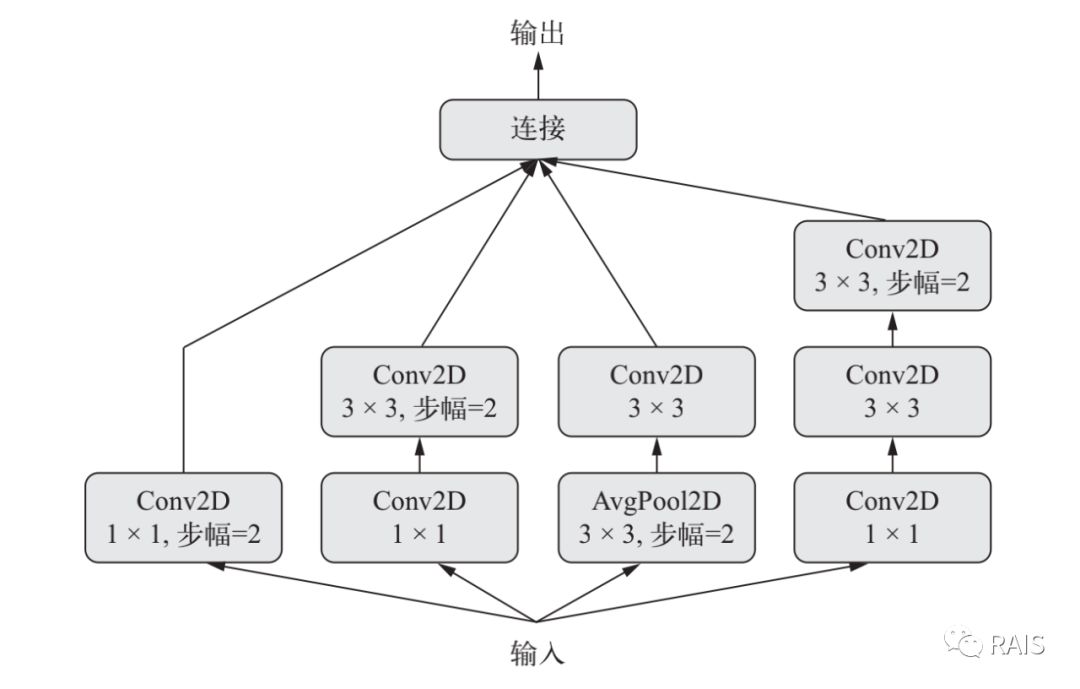
branch_a = layers.Conv2D(128, 1, activation='relu', strides=2)(x) branch_b = layers.Conv2D(128, 1, activation='relu')(x) branch_b = layers.Conv2D(128, 3, activation='relu', strides=2)(branch_b) branch_c = layers.AveragePooling2D(3, strides=2)(x) branch_c = layers.Conv2D(128, 3, activation='relu')(branch_c) branch_d = layers.Conv2D(128, 1, activation='relu')(x) branch_d = layers.Conv2D(128, 3, activation='relu')(branch_d) branch_d = layers.Conv2D(128, 3, activation='relu', strides=2)(branch_d) output = layers.concatenate([branch_a, branch_b, branch_c, branch_d], axis=-1)
Residual connection
This module helps to solve the problems of gradient disappearance (when the feedback signal is transmitted to the bottom layer, the signal is very weak) and representation bottleneck (some layers have too few parameters, which will cause some features to disappear permanently, and the later layers cannot obtain the feature information). The specific method is to make the output of the previous layer as the input of the later layer:
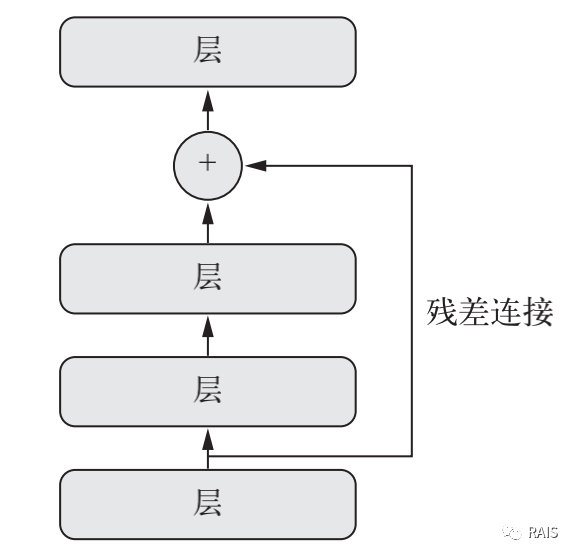
x = ... y = layers.Conv2D(128, 3, activation='relu', padding='same')(x) y = layers.Conv2D(128, 3, activation='relu', padding='same')(y) y = layers.Conv2D(128, 3, activation='relu', padding='same')(y) y = layers.add([y, x])
Shared layer weight
Functions are characterized by reuse and can be called many times. The functional programming here is the same. A layer is defined once and can be reused many times, which is well understood:
# Define once lstm = layers.LSTM(32) left_input = Input(shape=(None, 128)) # Use left_output = lstm(left_input) right_input = Input(shape=(None, 128)) # Use right_output = lstm(right_input) merged = layers.concatenate([left_output, right_output], axis=-1) predictions = layers.Dense(1, activation='sigmoid')(merged) model = Model([left_input, right_input], predictions)
This is the reuse and expansion of layers, and the model can also be the output vector, so the model can also be used as a layer, which is similar to the predefined network in the previous article
# Xception is a network xception_base = applications.Xception(weights=None, include_top=False) left_input = Input(shape=(250, 250, 3)) right_input = Input(shape=(250, 250, 3)) left_features = xception_base(left_input) right_input = xception_base(right_input) merged_features = layers.concatenate([left_features, right_input], axis=-1)
summary
I used to limit every article to about 1000 words, but this article is a little too close. They are too close to each other and can't do it. That's a long article. The content is in one continuous line, mainly remember that because of this functional API, you can build a complex network structure, not just a simple network layer stack. Based on this, you can build a multi input, multi output and complex network in various situations, and because of the characteristics of this functional type, there are various reuse situations.
- This article starts with the official account: RAIS , welcome to pay attention!