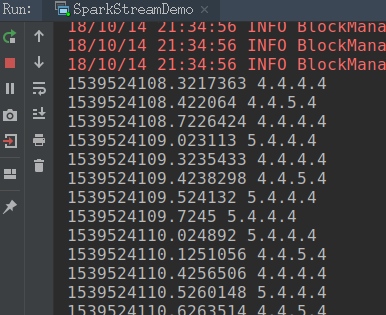
Novice learning, if there are mistakes, please correct, thank you!
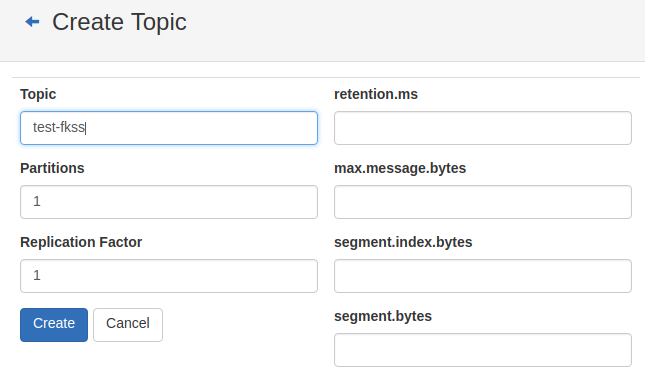
1. Start zookeeper and kafka, and set a topic as test fkss. For the convenience of observation, I added it through kafka manager
2. Configure Flume and start it. The listening file is / home / czh / docker-public-file/testplume.log, which is sent to kafka
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /home/czh/docker-public-file/testflume.log a1.sources.r1.channels = c1 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.topic = test-fkss a1.sinks.k1.brokerList = 172.17.0.2:9092 a1.sinks.k1.requiredAcks = 1 a1.sinks.k1.batchSize = 2 a1.sinks.k1.channel = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
Execute the start command bin / flume ng agent -- conf conf -- conf file conf / flume conf.properties.template -- name A1 - dflume. Root. Logger = info, console
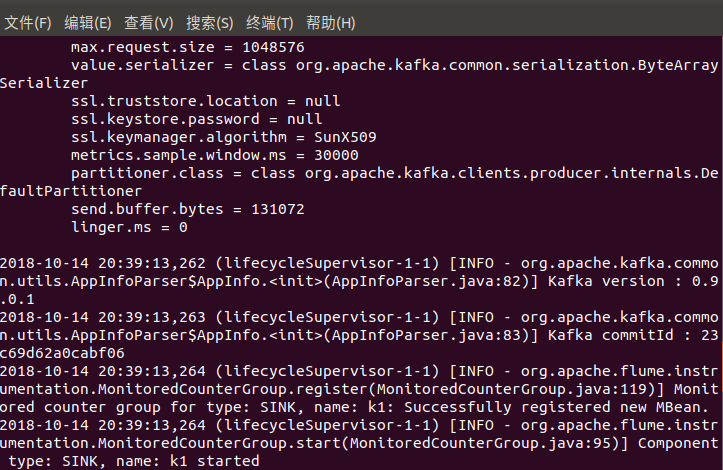
The next line appears indicating that the startup was successful
3. Start redis
4. Start the spark streaming log handler. The specific code is as follows
Parser SparkStreamDemo.scala
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkStreamDemo {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("flume_spark_streaming")
conf.setMaster("local[4]")
val sc = new SparkContext(conf)
sc.setCheckpointDir("/home/czh/IdeaProjects/SparkDemo/out/artifacts")
sc.setLogLevel("ERROR")
val ssc = new StreamingContext(sc, Seconds(3))
val kafkaParams = Map[String, String](
"bootstrap.servers" -> "172.17.0.2:9092",
"group.id" -> "test-fkss",
"auto.offset.reset" -> "smallest"
)
val topics = Set("test-fkss");
val stream = createStream(ssc, kafkaParams, topics)
val lines = stream.map(_._2)
lines.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
partitionOfRecords.foreach(pair => {
val time = parseLog(pair)._1
val ip = parseLog(pair)._2
println(time+" "+ip)
val jedis = RedisClient.pool.getResource
jedis.select(0)
if(null == jedis.get(ip))
jedis.set(ip, "1");
else
jedis.incr(ip)
val at = jedis.get(ip).toInt
val c = new JDBCCommend()
c.add(time, ip, at)
jedis.close()
})
}
}
ssc.start()
ssc.awaitTermination()
}
def createStream(scc: StreamingContext, kafkaParam: Map[String, String], topics: Set[String]) = {
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](scc, kafkaParam, topics)
}
def parseLog(log: String): (String, String) = {
var time = ""
var ip = ""
try{
time = log.split(" ")(0)
ip = log.split(" ")(1)
}
catch {
case e: Exception =>
e.printStackTrace()
}
(time, ip)
}
}Redis connection pool RedisClient.scala
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
import redis.clients.jedis.JedisPool
object RedisClient extends Serializable {
val redisHost = "127.0.0.1"
val redisPort = 6599
val redisTimeout = 30000
lazy val pool = new JedisPool(new GenericObjectPoolConfig(), redisHost, redisPort, redisTimeout)
lazy val hook = new Thread {
override def run = {
println("Execute hook thread: " + this)
pool.destroy()
}
}
sys.addShutdownHook(hook.run)
}JDBC connection JDBC connection.scala
import java.sql.{Connection, DriverManager}
object JDBCConnection {
val IP = "172.17.0.2"
val Port = "3306"
val DBType = "mysql"
val DBName = "st"
val username = "root"
val password = "root"
val url = "jdbc:" + DBType + "://" + IP + ":" + Port + "/" + DBName
classOf[com.mysql.jdbc.Driver]
def getConnection(): Connection = {
DriverManager.getConnection(url, username, password)
}
def close(conn: Connection): Unit = {
try {
if (!conn.isClosed() || conn != null) {
conn.close()
}
}
catch {
case ex: Exception => {
ex.printStackTrace()
}
}
}
}
JDBC operation JDBC comment.scala
class JDBCCommend {
case class Ip(time: String, ip: String, access_times: Int)
def add(time: String, ip: String, access_times: Int): Boolean = {
val conn = JDBCConnection.getConnection()
try {
val sql = new StringBuilder()
.append("INSERT INTO ip_table (time, ip, access_times)")
.append("VALUES(?, ?, ?)")
val ps = conn.prepareStatement(sql.toString())
ps.setObject(1, time)
ps.setObject(2, ip)
ps.setObject(3, access_times)
ps.executeUpdate() > 0
}
finally {
conn.close()
}
}
}pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com</groupId>
<artifactId>czh</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.0</scala.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
5. Start the simulated ip access generation log program
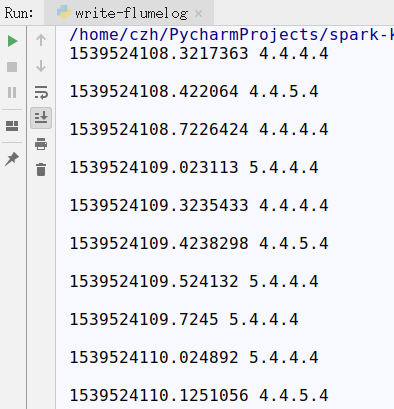
write-flumelog.py
import time
import random
for i in range(10):
f = open('/home/czh/docker-public-file/testflume.log', 'a')
time.sleep(random.randint(4, 9) * 0.1)
current_time = time.time()
ip = str(random.randint(4, 5)) + "." + str(random.randint(4, 4))\
+ "." + str(random.randint(4, 5)) + "." + str(random.randint(4, 4))
print(str(current_time) + " " + ip + "\n")
f.write(current_time.__str__() + " " + ip + "\n")
f.close()The overall operation results are as follows:
Write ip and access time to log file by python program
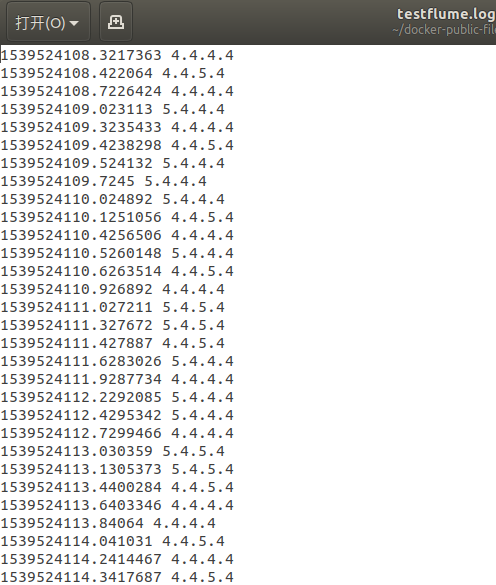
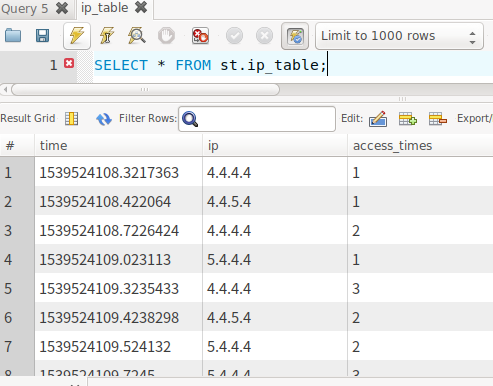
The sparkstreaming program obtains the data from flume in real time, calculates the number of accesses and writes them to mysql